 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStable-Layers: Fine-Tuning Image Layer Decomposition Models with VLM-Scored Reinforcement Learning
May 28, 2026We present Stable-Layers, a reinforcement learning framework that eliminates the need for paired supervision by fine-tuning a pretrained layer decomposition model using only feedback from a vision-language model (VLM). Starting from Qwen-Image-Layered, we apply Flow-GRPO with LoRA adaptation, sampling multiple candidate decompositions per image, scoring them with a VLM, and optimising the policy from group-relative advantages. The key challenge lies in designing a reliable reward signal: VLMs scoring samples in isolation tend to compress their judgements into a narrow band, leaving GRPO with little within-group variance to learn from. We address this with a two-stage evaluation pipeline that pairs structured per-sample scoring across five edit-centric criteria with a grid-based calibration step in which the VLM re-scores all candidates side-by-side. Stable-Layers produces decompositions with stronger layer separation, fewer blank or artifact-heavy layers, and lower per-layer reconstruction error on the Crello dataset compared to the base model.
OCTOPUS: Optimized KV Cache for Transformers via Octahedral Parametrization Under optimal Squared error quantization
May 20, 2026The key-value (KV) cache dominates memory bandwidth and footprint in long-context autoregressive inference. Recent rotation-preconditioned codecs (TurboQuant, PolarQuant) show that a structured random rotation followed by a per-coordinate scalar quantizer matched to an analytically tractable marginal is a near-optimal recipe for KV compression. OCTOPUS advances this paradigm through joint quantization of rotated coordinate triplets. Each triplet's direction is mapped to a square via an octahedral parameterization, and the two resulting coordinates and the triplet norm are Lloyd-Max quantized against implementation-matched marginals. Optimizing the per-triplet squared error gives a strictly non-uniform bit allocation depending only on the total dimensionality of the keys. We find the finite-dimensional quality optimum with sweeps to be constant on every real decoder we test. The codec is data-oblivious, online, and deterministic given a seed. Across text, video, and audio, OCTOPUS matches or beats every prior rotation codec at every reported bit width and metric, with a lead that grows as bits drop for extreme compression. Furthermore, a fused Triton implementation reconstructs keys on the fly without materializing the uncompressed key, so the codec adds no decode-time bandwidth or latency over the existing dequantization. Project Page: https://octopus-quant.github.io/
ReLi3D: Relightable Multi-view 3D Reconstruction with Disentangled Illumination
Mar 20, 2026Reconstructing 3D assets from images has long required separate pipelines for geometry reconstruction, material estimation, and illumination recovery, each with distinct limitations and computational overhead. We present ReLi3D, the first unified end-to-end pipeline that simultaneously reconstructs complete 3D geometry, spatially-varying physically-based materials, and environment illumination from sparse multi-view images in under one second. Our key insight is that multi-view constraints can dramatically improve material and illumination disentanglement, a problem that remains fundamentally ill-posed for single-image methods. Key to our approach is the fusion of the multi-view input via a transformer cross-conditioning architecture, followed by a novel unified two-path prediction strategy. The first path predicts the object's structure and appearance, while the second path predicts the environment illumination from image background or object reflections. This, combined with a differentiable Monte Carlo multiple importance sampling renderer, creates an optimal illumination disentanglement training pipeline. In addition, with our mixed domain training protocol, which combines synthetic PBR datasets with real-world RGB captures, we establish generalizable results in geometry, material accuracy, and illumination quality. By unifying previously separate reconstruction tasks into a single feed-forward pass, we enable near-instantaneous generation of complete, relightable 3D assets. Project Page: https://reli3d.jdihlmann.com/
* Project Page: https://reli3d.jdihlmann.com/
MARBLE: Material Recomposition and Blending in CLIP-Space
Jun 05, 2025



Editing materials of objects in images based on exemplar images is an active area of research in computer vision and graphics. We propose MARBLE, a method for performing material blending and recomposing fine-grained material properties by finding material embeddings in CLIP-space and using that to control pre-trained text-to-image models. We improve exemplar-based material editing by finding a block in the denoising UNet responsible for material attribution. Given two material exemplar-images, we find directions in the CLIP-space for blending the materials. Further, we can achieve parametric control over fine-grained material attributes such as roughness, metallic, transparency, and glow using a shallow network to predict the direction for the desired material attribute change. We perform qualitative and quantitative analysis to demonstrate the efficacy of our proposed method. We also present the ability of our method to perform multiple edits in a single forward pass and applicability to painting. Project Page: https://marblecontrol.github.io/
Stable Virtual Camera: Generative View Synthesis with Diffusion Models
Mar 18, 2025We present Stable Virtual Camera (Seva), a generalist diffusion model that creates novel views of a scene, given any number of input views and target cameras. Existing works struggle to generate either large viewpoint changes or temporally smooth samples, while relying on specific task configurations. Our approach overcomes these limitations through simple model design, optimized training recipe, and flexible sampling strategy that generalize across view synthesis tasks at test time. As a result, our samples maintain high consistency without requiring additional 3D representation-based distillation, thus streamlining view synthesis in the wild. Furthermore, we show that our method can generate high-quality videos lasting up to half a minute with seamless loop closure. Extensive benchmarking demonstrates that Seva outperforms existing methods across different datasets and settings.
SPAR3D: Stable Point-Aware Reconstruction of 3D Objects from Single Images
Jan 08, 2025



We study the problem of single-image 3D object reconstruction. Recent works have diverged into two directions: regression-based modeling and generative modeling. Regression methods efficiently infer visible surfaces, but struggle with occluded regions. Generative methods handle uncertain regions better by modeling distributions, but are computationally expensive and the generation is often misaligned with visible surfaces. In this paper, we present SPAR3D, a novel two-stage approach aiming to take the best of both directions. The first stage of SPAR3D generates sparse 3D point clouds using a lightweight point diffusion model, which has a fast sampling speed. The second stage uses both the sampled point cloud and the input image to create highly detailed meshes. Our two-stage design enables probabilistic modeling of the ill-posed single-image 3D task while maintaining high computational efficiency and great output fidelity. Using point clouds as an intermediate representation further allows for interactive user edits. Evaluated on diverse datasets, SPAR3D demonstrates superior performance over previous state-of-the-art methods, at an inference speed of 0.7 seconds. Project page with code and model: https://spar3d.github.io
SF3D: Stable Fast 3D Mesh Reconstruction with UV-unwrapping and Illumination Disentanglement
Aug 01, 2024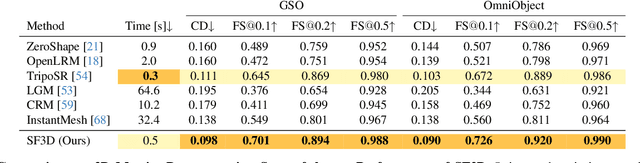
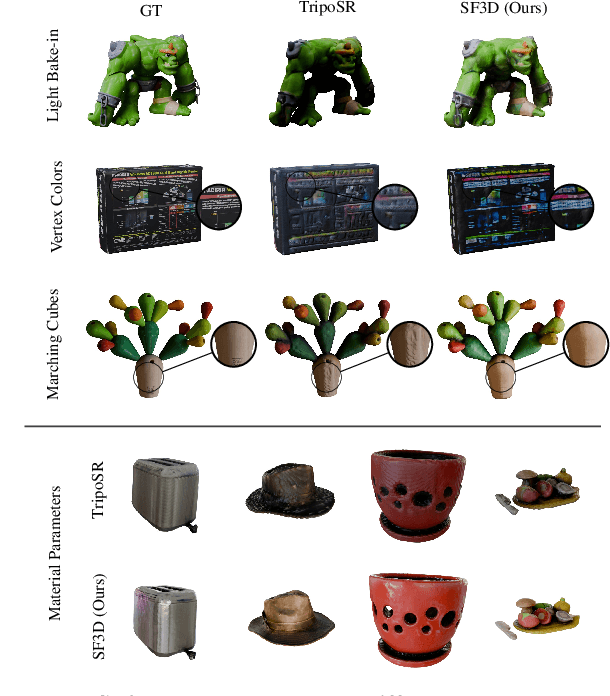

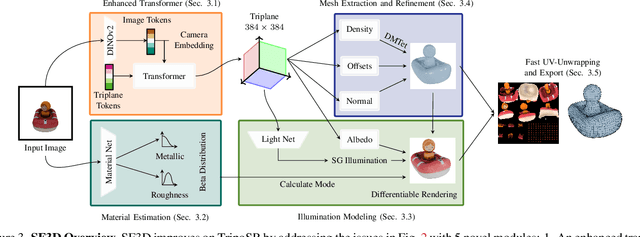
We present SF3D, a novel method for rapid and high-quality textured object mesh reconstruction from a single image in just 0.5 seconds. Unlike most existing approaches, SF3D is explicitly trained for mesh generation, incorporating a fast UV unwrapping technique that enables swift texture generation rather than relying on vertex colors. The method also learns to predict material parameters and normal maps to enhance the visual quality of the reconstructed 3D meshes. Furthermore, SF3D integrates a delighting step to effectively remove low-frequency illumination effects, ensuring that the reconstructed meshes can be easily used in novel illumination conditions. Experiments demonstrate the superior performance of SF3D over the existing techniques. Project page: https://stable-fast-3d.github.io
SV3D: Novel Multi-view Synthesis and 3D Generation from a Single Image using Latent Video Diffusion
Mar 18, 2024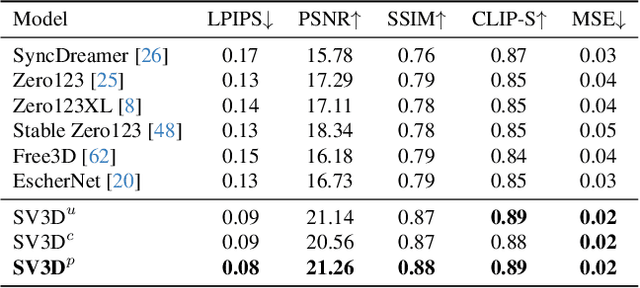
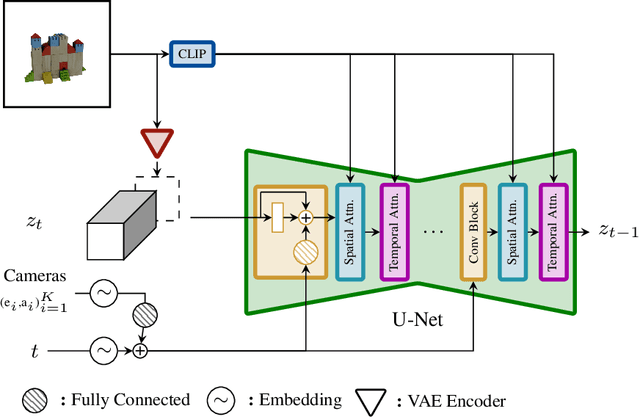
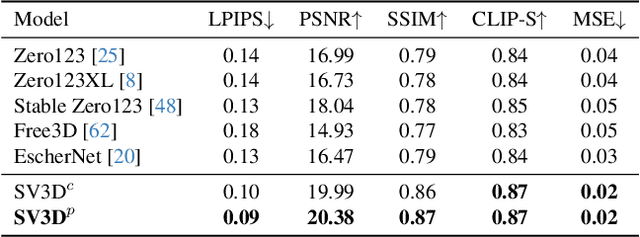
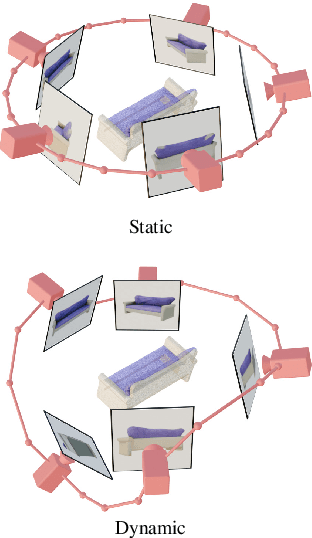
We present Stable Video 3D (SV3D) -- a latent video diffusion model for high-resolution, image-to-multi-view generation of orbital videos around a 3D object. Recent work on 3D generation propose techniques to adapt 2D generative models for novel view synthesis (NVS) and 3D optimization. However, these methods have several disadvantages due to either limited views or inconsistent NVS, thereby affecting the performance of 3D object generation. In this work, we propose SV3D that adapts image-to-video diffusion model for novel multi-view synthesis and 3D generation, thereby leveraging the generalization and multi-view consistency of the video models, while further adding explicit camera control for NVS. We also propose improved 3D optimization techniques to use SV3D and its NVS outputs for image-to-3D generation. Extensive experimental results on multiple datasets with 2D and 3D metrics as well as user study demonstrate SV3D's state-of-the-art performance on NVS as well as 3D reconstruction compared to prior works.
Collaborative Control for Geometry-Conditioned PBR Image Generation
Feb 20, 2024Current 3D content generation approaches build on diffusion models that output RGB images. Modern graphics pipelines, however, require physically-based rendering (PBR) material properties. We propose to model the PBR image distribution directly, avoiding photometric inaccuracies in RGB generation and the inherent ambiguity in extracting PBR from RGB. Existing paradigms for cross-modal fine-tuning are not suited for PBR generation due to both a lack of data and the high dimensionality of the output modalities: we overcome both challenges by retaining a frozen RGB model and tightly linking a newly trained PBR model using a novel cross-network communication paradigm. As the base RGB model is fully frozen, the proposed method does not risk catastrophic forgetting during fine-tuning and remains compatible with techniques such as IPAdapter pretrained for the base RGB model. We validate our design choices, robustness to data sparsity, and compare against existing paradigms with an extensive experimental section.
SHINOBI: Shape and Illumination using Neural Object Decomposition via BRDF Optimization In-the-wild
Jan 18, 2024We present SHINOBI, an end-to-end framework for the reconstruction of shape, material, and illumination from object images captured with varying lighting, pose, and background. Inverse rendering of an object based on unconstrained image collections is a long-standing challenge in computer vision and graphics and requires a joint optimization over shape, radiance, and pose. We show that an implicit shape representation based on a multi-resolution hash encoding enables faster and robust shape reconstruction with joint camera alignment optimization that outperforms prior work. Further, to enable the editing of illumination and object reflectance (i.e. material) we jointly optimize BRDF and illumination together with the object's shape. Our method is class-agnostic and works on in-the-wild image collections of objects to produce relightable 3D assets for several use cases such as AR/VR, movies, games, etc. Project page: https://shinobi.aengelhardt.com Video: https://www.youtube.com/watch?v=iFENQ6AcYd8&feature=youtu.be