 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman Video Generation from a Single Image with 3D Pose and View Control
Feb 24, 2026Recent diffusion methods have made significant progress in generating videos from single images due to their powerful visual generation capabilities. However, challenges persist in image-to-video synthesis, particularly in human video generation, where inferring view-consistent, motion-dependent clothing wrinkles from a single image remains a formidable problem. In this paper, we present Human Video Generation in 4D (HVG), a latent video diffusion model capable of generating high-quality, multi-view, spatiotemporally coherent human videos from a single image with 3D pose and view control. HVG achieves this through three key designs: (i) Articulated Pose Modulation, which captures the anatomical relationships of 3D joints via a novel dual-dimensional bone map and resolves self-occlusions across views by introducing 3D information; (ii) View and Temporal Alignment, which ensures multi-view consistency and alignment between a reference image and pose sequences for frame-to-frame stability; and (iii) Progressive Spatio-Temporal Sampling with temporal alignment to maintain smooth transitions in long multi-view animations. Extensive experiments on image-to-video tasks demonstrate that HVG outperforms existing methods in generating high-quality 4D human videos from diverse human images and pose inputs.
FaceCraft4D: Animated 3D Facial Avatar Generation from a Single Image
Apr 21, 2025We present a novel framework for generating high-quality, animatable 4D avatar from a single image. While recent advances have shown promising results in 4D avatar creation, existing methods either require extensive multiview data or struggle with shape accuracy and identity consistency. To address these limitations, we propose a comprehensive system that leverages shape, image, and video priors to create full-view, animatable avatars. Our approach first obtains initial coarse shape through 3D-GAN inversion. Then, it enhances multiview textures using depth-guided warping signals for cross-view consistency with the help of the image diffusion model. To handle expression animation, we incorporate a video prior with synchronized driving signals across viewpoints. We further introduce a Consistent-Inconsistent training to effectively handle data inconsistencies during 4D reconstruction. Experimental results demonstrate that our method achieves superior quality compared to the prior art, while maintaining consistency across different viewpoints and expressions.
SV4D 2.0: Enhancing Spatio-Temporal Consistency in Multi-View Video Diffusion for High-Quality 4D Generation
Mar 21, 2025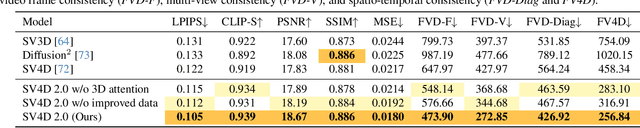
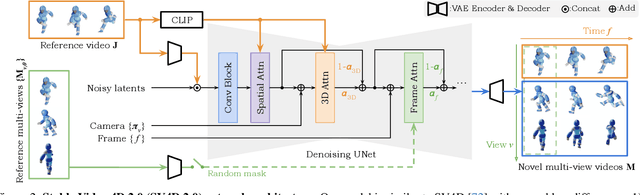
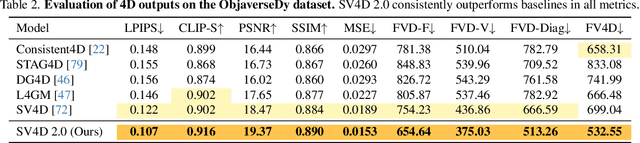
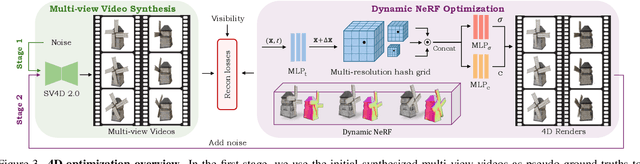
We present Stable Video 4D 2.0 (SV4D 2.0), a multi-view video diffusion model for dynamic 3D asset generation. Compared to its predecessor SV4D, SV4D 2.0 is more robust to occlusions and large motion, generalizes better to real-world videos, and produces higher-quality outputs in terms of detail sharpness and spatio-temporal consistency. We achieve this by introducing key improvements in multiple aspects: 1) network architecture: eliminating the dependency of reference multi-views and designing blending mechanism for 3D and frame attention, 2) data: enhancing quality and quantity of training data, 3) training strategy: adopting progressive 3D-4D training for better generalization, and 4) 4D optimization: handling 3D inconsistency and large motion via 2-stage refinement and progressive frame sampling. Extensive experiments demonstrate significant performance gain by SV4D 2.0 both visually and quantitatively, achieving better detail (-14\% LPIPS) and 4D consistency (-44\% FV4D) in novel-view video synthesis and 4D optimization (-12\% LPIPS and -24\% FV4D) compared to SV4D.
Stable Virtual Camera: Generative View Synthesis with Diffusion Models
Mar 18, 2025We present Stable Virtual Camera (Seva), a generalist diffusion model that creates novel views of a scene, given any number of input views and target cameras. Existing works struggle to generate either large viewpoint changes or temporally smooth samples, while relying on specific task configurations. Our approach overcomes these limitations through simple model design, optimized training recipe, and flexible sampling strategy that generalize across view synthesis tasks at test time. As a result, our samples maintain high consistency without requiring additional 3D representation-based distillation, thus streamlining view synthesis in the wild. Furthermore, we show that our method can generate high-quality videos lasting up to half a minute with seamless loop closure. Extensive benchmarking demonstrates that Seva outperforms existing methods across different datasets and settings.
SV4D: Dynamic 3D Content Generation with Multi-Frame and Multi-View Consistency
Jul 24, 2024We present Stable Video 4D (SV4D), a latent video diffusion model for multi-frame and multi-view consistent dynamic 3D content generation. Unlike previous methods that rely on separately trained generative models for video generation and novel view synthesis, we design a unified diffusion model to generate novel view videos of dynamic 3D objects. Specifically, given a monocular reference video, SV4D generates novel views for each video frame that are temporally consistent. We then use the generated novel view videos to optimize an implicit 4D representation (dynamic NeRF) efficiently, without the need for cumbersome SDS-based optimization used in most prior works. To train our unified novel view video generation model, we curated a dynamic 3D object dataset from the existing Objaverse dataset. Extensive experimental results on multiple datasets and user studies demonstrate SV4D's state-of-the-art performance on novel-view video synthesis as well as 4D generation compared to prior works.
ANIM: Accurate Neural Implicit Model for Human Reconstruction from a single RGB-D image
Mar 18, 2024



Recent progress in human shape learning, shows that neural implicit models are effective in generating 3D human surfaces from limited number of views, and even from a single RGB image. However, existing monocular approaches still struggle to recover fine geometric details such as face, hands or cloth wrinkles. They are also easily prone to depth ambiguities that result in distorted geometries along the camera optical axis. In this paper, we explore the benefits of incorporating depth observations in the reconstruction process by introducing ANIM, a novel method that reconstructs arbitrary 3D human shapes from single-view RGB-D images with an unprecedented level of accuracy. Our model learns geometric details from both multi-resolution pixel-aligned and voxel-aligned features to leverage depth information and enable spatial relationships, mitigating depth ambiguities. We further enhance the quality of the reconstructed shape by introducing a depth-supervision strategy, which improves the accuracy of the signed distance field estimation of points that lie on the reconstructed surface. Experiments demonstrate that ANIM outperforms state-of-the-art works that use RGB, surface normals, point cloud or RGB-D data as input. In addition, we introduce ANIM-Real, a new multi-modal dataset comprising high-quality scans paired with consumer-grade RGB-D camera, and our protocol to fine-tune ANIM, enabling high-quality reconstruction from real-world human capture.
SV3D: Novel Multi-view Synthesis and 3D Generation from a Single Image using Latent Video Diffusion
Mar 18, 2024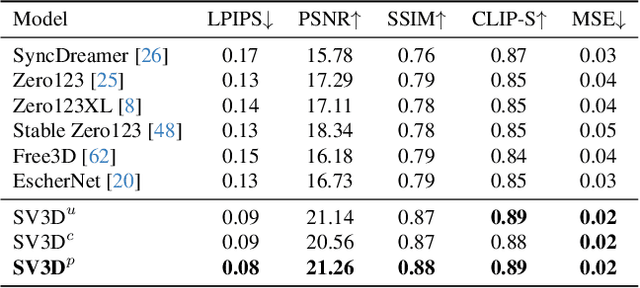
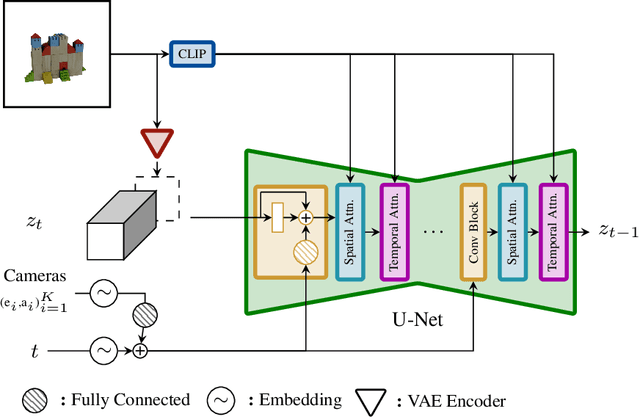
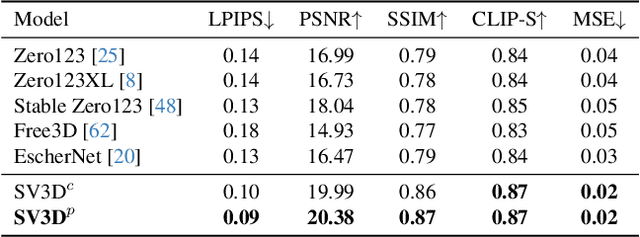
We present Stable Video 3D (SV3D) -- a latent video diffusion model for high-resolution, image-to-multi-view generation of orbital videos around a 3D object. Recent work on 3D generation propose techniques to adapt 2D generative models for novel view synthesis (NVS) and 3D optimization. However, these methods have several disadvantages due to either limited views or inconsistent NVS, thereby affecting the performance of 3D object generation. In this work, we propose SV3D that adapts image-to-video diffusion model for novel multi-view synthesis and 3D generation, thereby leveraging the generalization and multi-view consistency of the video models, while further adding explicit camera control for NVS. We also propose improved 3D optimization techniques to use SV3D and its NVS outputs for image-to-3D generation. Extensive experimental results on multiple datasets with 2D and 3D metrics as well as user study demonstrate SV3D's state-of-the-art performance on NVS as well as 3D reconstruction compared to prior works.
ARTIC3D: Learning Robust Articulated 3D Shapes from Noisy Web Image Collections
Jun 07, 2023



Estimating 3D articulated shapes like animal bodies from monocular images is inherently challenging due to the ambiguities of camera viewpoint, pose, texture, lighting, etc. We propose ARTIC3D, a self-supervised framework to reconstruct per-instance 3D shapes from a sparse image collection in-the-wild. Specifically, ARTIC3D is built upon a skeleton-based surface representation and is further guided by 2D diffusion priors from Stable Diffusion. First, we enhance the input images with occlusions/truncation via 2D diffusion to obtain cleaner mask estimates and semantic features. Second, we perform diffusion-guided 3D optimization to estimate shape and texture that are of high-fidelity and faithful to input images. We also propose a novel technique to calculate more stable image-level gradients via diffusion models compared to existing alternatives. Finally, we produce realistic animations by fine-tuning the rendered shape and texture under rigid part transformations. Extensive evaluations on multiple existing datasets as well as newly introduced noisy web image collections with occlusions and truncation demonstrate that ARTIC3D outputs are more robust to noisy images, higher quality in terms of shape and texture details, and more realistic when animated. Project page: https://chhankyao.github.io/artic3d/
Hi-LASSIE: High-Fidelity Articulated Shape and Skeleton Discovery from Sparse Image Ensemble
Dec 28, 2022



Automatically estimating 3D skeleton, shape, camera viewpoints, and part articulation from sparse in-the-wild image ensembles is a severely under-constrained and challenging problem. Most prior methods rely on large-scale image datasets, dense temporal correspondence, or human annotations like camera pose, 2D keypoints, and shape templates. We propose Hi-LASSIE, which performs 3D articulated reconstruction from only 20-30 online images in the wild without any user-defined shape or skeleton templates. We follow the recent work of LASSIE that tackles a similar problem setting and make two significant advances. First, instead of relying on a manually annotated 3D skeleton, we automatically estimate a class-specific skeleton from the selected reference image. Second, we improve the shape reconstructions with novel instance-specific optimization strategies that allow reconstructions to faithful fit on each instance while preserving the class-specific priors learned across all images. Experiments on in-the-wild image ensembles show that Hi-LASSIE obtains higher fidelity state-of-the-art 3D reconstructions despite requiring minimum user input.
Learning Visibility for Robust Dense Human Body Estimation
Aug 23, 2022
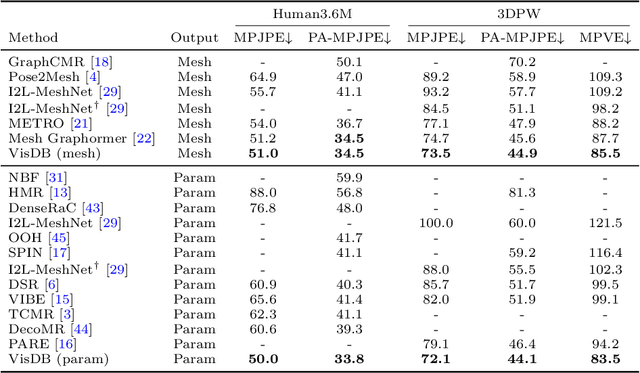
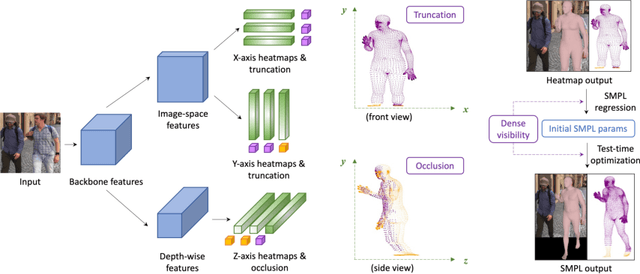

Estimating 3D human pose and shape from 2D images is a crucial yet challenging task. While prior methods with model-based representations can perform reasonably well on whole-body images, they often fail when parts of the body are occluded or outside the frame. Moreover, these results usually do not faithfully capture the human silhouettes due to their limited representation power of deformable models (e.g., representing only the naked body). An alternative approach is to estimate dense vertices of a predefined template body in the image space. Such representations are effective in localizing vertices within an image but cannot handle out-of-frame body parts. In this work, we learn dense human body estimation that is robust to partial observations. We explicitly model the visibility of human joints and vertices in the x, y, and z axes separately. The visibility in x and y axes help distinguishing out-of-frame cases, and the visibility in depth axis corresponds to occlusions (either self-occlusions or occlusions by other objects). We obtain pseudo ground-truths of visibility labels from dense UV correspondences and train a neural network to predict visibility along with 3D coordinates. We show that visibility can serve as 1) an additional signal to resolve depth ordering ambiguities of self-occluded vertices and 2) a regularization term when fitting a human body model to the predictions. Extensive experiments on multiple 3D human datasets demonstrate that visibility modeling significantly improves the accuracy of human body estimation, especially for partial-body cases. Our project page with code is at: https://github.com/chhankyao/visdb.