 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSplatFields: Neural Gaussian Splats for Sparse 3D and 4D Reconstruction
Sep 17, 2024



Digitizing 3D static scenes and 4D dynamic events from multi-view images has long been a challenge in computer vision and graphics. Recently, 3D Gaussian Splatting (3DGS) has emerged as a practical and scalable reconstruction method, gaining popularity due to its impressive reconstruction quality, real-time rendering capabilities, and compatibility with widely used visualization tools. However, the method requires a substantial number of input views to achieve high-quality scene reconstruction, introducing a significant practical bottleneck. This challenge is especially severe in capturing dynamic scenes, where deploying an extensive camera array can be prohibitively costly. In this work, we identify the lack of spatial autocorrelation of splat features as one of the factors contributing to the suboptimal performance of the 3DGS technique in sparse reconstruction settings. To address the issue, we propose an optimization strategy that effectively regularizes splat features by modeling them as the outputs of a corresponding implicit neural field. This results in a consistent enhancement of reconstruction quality across various scenarios. Our approach effectively handles static and dynamic cases, as demonstrated by extensive testing across different setups and scene complexities.
ANIM: Accurate Neural Implicit Model for Human Reconstruction from a single RGB-D image
Mar 18, 2024



Recent progress in human shape learning, shows that neural implicit models are effective in generating 3D human surfaces from limited number of views, and even from a single RGB image. However, existing monocular approaches still struggle to recover fine geometric details such as face, hands or cloth wrinkles. They are also easily prone to depth ambiguities that result in distorted geometries along the camera optical axis. In this paper, we explore the benefits of incorporating depth observations in the reconstruction process by introducing ANIM, a novel method that reconstructs arbitrary 3D human shapes from single-view RGB-D images with an unprecedented level of accuracy. Our model learns geometric details from both multi-resolution pixel-aligned and voxel-aligned features to leverage depth information and enable spatial relationships, mitigating depth ambiguities. We further enhance the quality of the reconstructed shape by introducing a depth-supervision strategy, which improves the accuracy of the signed distance field estimation of points that lie on the reconstructed surface. Experiments demonstrate that ANIM outperforms state-of-the-art works that use RGB, surface normals, point cloud or RGB-D data as input. In addition, we introduce ANIM-Real, a new multi-modal dataset comprising high-quality scans paired with consumer-grade RGB-D camera, and our protocol to fine-tune ANIM, enabling high-quality reconstruction from real-world human capture.
HISR: Hybrid Implicit Surface Representation for Photorealistic 3D Human Reconstruction
Dec 28, 2023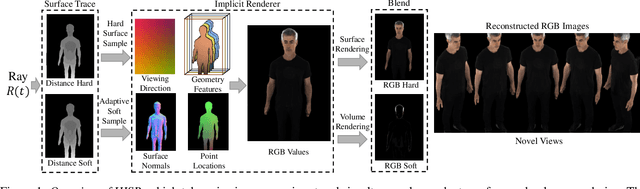
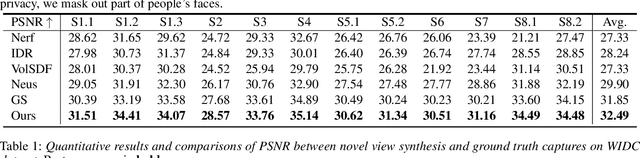
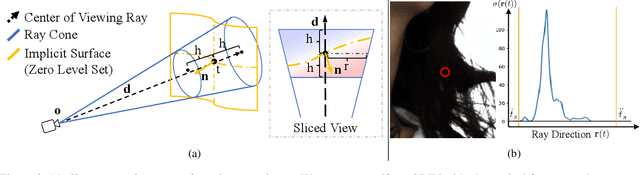
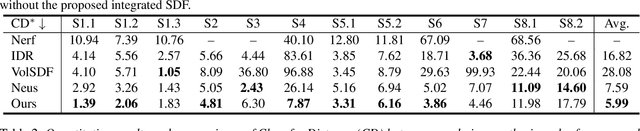
Neural reconstruction and rendering strategies have demonstrated state-of-the-art performances due, in part, to their ability to preserve high level shape details. Existing approaches, however, either represent objects as implicit surface functions or neural volumes and still struggle to recover shapes with heterogeneous materials, in particular human skin, hair or clothes. To this aim, we present a new hybrid implicit surface representation to model human shapes. This representation is composed of two surface layers that represent opaque and translucent regions on the clothed human body. We segment different regions automatically using visual cues and learn to reconstruct two signed distance functions (SDFs). We perform surface-based rendering on opaque regions (e.g., body, face, clothes) to preserve high-fidelity surface normals and volume rendering on translucent regions (e.g., hair). Experiments demonstrate that our approach obtains state-of-the-art results on 3D human reconstructions, and also shows competitive performances on other objects.
CausalOps -- Towards an Industrial Lifecycle for Causal Probabilistic Graphical Models
Aug 02, 2023



Causal probabilistic graph-based models have gained widespread utility, enabling the modeling of cause-and-effect relationships across diverse domains. With their rising adoption in new areas, such as automotive system safety and machine learning, the need for an integrated lifecycle framework akin to DevOps and MLOps has emerged. Currently, a process reference for organizations interested in employing causal engineering is missing. To address this gap and foster widespread industrial adoption, we propose CausalOps, a novel lifecycle framework for causal model development and application. By defining key entities, dependencies, and intermediate artifacts generated during causal engineering, we establish a consistent vocabulary and workflow model. This work contextualizes causal model usage across different stages and stakeholders, outlining a holistic view of creating and maintaining them. CausalOps' aim is to drive the adoption of causal methods in practical applications within interested organizations and the causality community.
Multiframe Scene Flow with Piecewise Rigid Motion
Oct 05, 2017



We introduce a novel multiframe scene flow approach that jointly optimizes the consistency of the patch appearances and their local rigid motions from RGB-D image sequences. In contrast to the competing methods, we take advantage of an oversegmentation of the reference frame and robust optimization techniques. We formulate scene flow recovery as a global non-linear least squares problem which is iteratively solved by a damped Gauss-Newton approach. As a result, we obtain a qualitatively new level of accuracy in RGB-D based scene flow estimation which can potentially run in real-time. Our method can handle challenging cases with rigid, piecewise rigid, articulated and moderate non-rigid motion, and does not rely on prior knowledge about the types of motions and deformations. Extensive experiments on synthetic and real data show that our method outperforms state-of-the-art.
Efficient Online Surface Correction for Real-time Large-Scale 3D Reconstruction
Sep 12, 2017


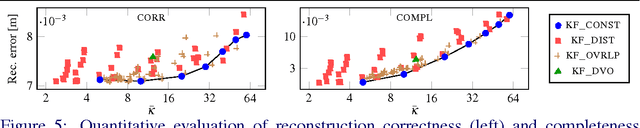
State-of-the-art methods for large-scale 3D reconstruction from RGB-D sensors usually reduce drift in camera tracking by globally optimizing the estimated camera poses in real-time without simultaneously updating the reconstructed surface on pose changes. We propose an efficient on-the-fly surface correction method for globally consistent dense 3D reconstruction of large-scale scenes. Our approach uses a dense Visual RGB-D SLAM system that estimates the camera motion in real-time on a CPU and refines it in a global pose graph optimization. Consecutive RGB-D frames are locally fused into keyframes, which are incorporated into a sparse voxel hashed Signed Distance Field (SDF) on the GPU. On pose graph updates, the SDF volume is corrected on-the-fly using a novel keyframe re-integration strategy with reduced GPU-host streaming. We demonstrate in an extensive quantitative evaluation that our method is up to 93% more runtime efficient compared to the state-of-the-art and requires significantly less memory, with only negligible loss of surface quality. Overall, our system requires only a single GPU and allows for real-time surface correction of large environments.
Intrinsic3D: High-Quality 3D Reconstruction by Joint Appearance and Geometry Optimization with Spatially-Varying Lighting
Aug 04, 2017


We introduce a novel method to obtain high-quality 3D reconstructions from consumer RGB-D sensors. Our core idea is to simultaneously optimize for geometry encoded in a signed distance field (SDF), textures from automatically-selected keyframes, and their camera poses along with material and scene lighting. To this end, we propose a joint surface reconstruction approach that is based on Shape-from-Shading (SfS) techniques and utilizes the estimation of spatially-varying spherical harmonics (SVSH) from subvolumes of the reconstructed scene. Through extensive examples and evaluations, we demonstrate that our method dramatically increases the level of detail in the reconstructed scene geometry and contributes highly to consistent surface texture recovery.
De-noising, Stabilizing and Completing 3D Reconstructions On-the-go using Plane Priors
Mar 28, 2017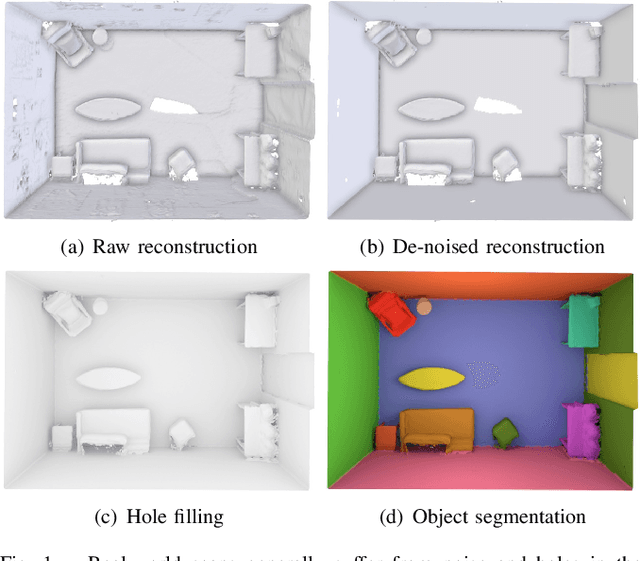
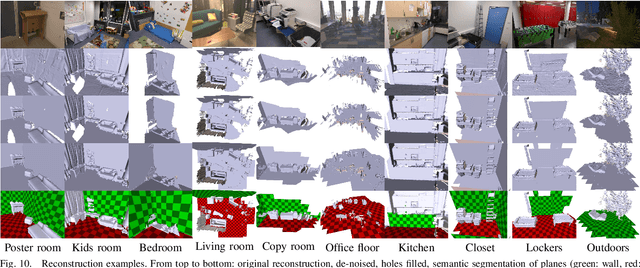

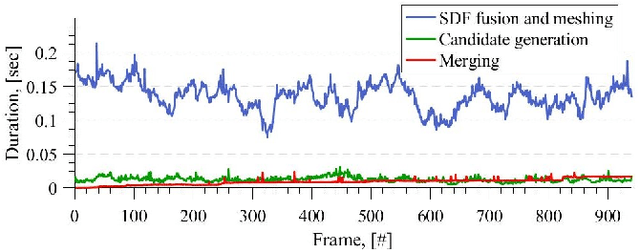
Creating 3D maps on robots and other mobile devices has become a reality in recent years. Online 3D reconstruction enables many exciting applications in robotics and AR/VR gaming. However, the reconstructions are noisy and generally incomplete. Moreover, during onine reconstruction, the surface changes with every newly integrated depth image which poses a significant challenge for physics engines and path planning algorithms. This paper presents a novel, fast and robust method for obtaining and using information about planar surfaces, such as walls, floors, and ceilings as a stage in 3D reconstruction based on Signed Distance Fields. Our algorithm recovers clean and accurate surfaces, reduces the movement of individual mesh vertices caused by noise during online reconstruction and fills in the occluded and unobserved regions. We implemented and evaluated two different strategies to generate plane candidates and two strategies for merging them. Our implementation is optimized to run in real-time on mobile devices such as the Tango tablet. In an extensive set of experiments, we validated that our approach works well in a large number of natural environments despite the presence of significant amount of occlusion, clutter and noise, which occur frequently. We further show that plane fitting enables in many cases a meaningful semantic segmentation of real-world scenes.