 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNymeriaPlus: Enriching Nymeria Dataset with Additional Annotations and Data
Mar 19, 2026The Nymeria Dataset, released in 2024, is a large-scale collection of in-the-wild human activities captured with multiple egocentric wearable devices that are spatially localized and temporally synchronized. It provides body-motion ground truth recorded with a motion-capture suit, device trajectories, semi-dense 3D point clouds, and in-context narrations. In this paper, we upgrade Nymeria and introduce NymeriaPlus. NymeriaPlus features: (1) improved human motion in Momentum Human Rig (MHR) and SMPL formats; (2) dense 3D and 2D bounding box annotations for indoor objects and structural elements; (3) instance-level 3D object reconstructions; and (4) additional modalities e.g., basemap recordings, audio, and wristband videos. By consolidating these complementary modalities and annotations into a single, coherent benchmark, NymeriaPlus strengthens Nymeria into a more powerful in-the-wild egocentric dataset. We expect NymeriaPlus to bridge a key gap in existing egocentric resources and to support a broader range of research, including unique explorations of multimodal learning for embodied AI.
Masked Modeling for Human Motion Recovery Under Occlusions
Jan 23, 2026Human motion reconstruction from monocular videos is a fundamental challenge in computer vision, with broad applications in AR/VR, robotics, and digital content creation, but remains challenging under frequent occlusions in real-world settings. Existing regression-based methods are efficient but fragile to missing observations, while optimization- and diffusion-based approaches improve robustness at the cost of slow inference speed and heavy preprocessing steps. To address these limitations, we leverage recent advances in generative masked modeling and present MoRo: Masked Modeling for human motion Recovery under Occlusions. MoRo is an occlusion-robust, end-to-end generative framework that formulates motion reconstruction as a video-conditioned task, and efficiently recover human motion in a consistent global coordinate system from RGB videos. By masked modeling, MoRo naturally handles occlusions while enabling efficient, end-to-end inference. To overcome the scarcity of paired video-motion data, we design a cross-modality learning scheme that learns multi-modal priors from a set of heterogeneous datasets: (i) a trajectory-aware motion prior trained on MoCap datasets, (ii) an image-conditioned pose prior trained on image-pose datasets, capturing diverse per-frame poses, and (iii) a video-conditioned masked transformer that fuses motion and pose priors, finetuned on video-motion datasets to integrate visual cues with motion dynamics for robust inference. Extensive experiments on EgoBody and RICH demonstrate that MoRo substantially outperforms state-of-the-art methods in accuracy and motion realism under occlusions, while performing on-par in non-occluded scenarios. MoRo achieves real-time inference at 70 FPS on a single H200 GPU.
MHR: Momentum Human Rig
Nov 19, 2025We present MHR, a parametric human body model that combines the decoupled skeleton/shape paradigm of ATLAS with a flexible, modern rig and pose corrective system inspired by the Momentum library. Our model enables expressive, anatomically plausible human animation, supporting non-linear pose correctives, and is designed for robust integration in AR/VR and graphics pipelines.
SplatFields: Neural Gaussian Splats for Sparse 3D and 4D Reconstruction
Sep 17, 2024



Digitizing 3D static scenes and 4D dynamic events from multi-view images has long been a challenge in computer vision and graphics. Recently, 3D Gaussian Splatting (3DGS) has emerged as a practical and scalable reconstruction method, gaining popularity due to its impressive reconstruction quality, real-time rendering capabilities, and compatibility with widely used visualization tools. However, the method requires a substantial number of input views to achieve high-quality scene reconstruction, introducing a significant practical bottleneck. This challenge is especially severe in capturing dynamic scenes, where deploying an extensive camera array can be prohibitively costly. In this work, we identify the lack of spatial autocorrelation of splat features as one of the factors contributing to the suboptimal performance of the 3DGS technique in sparse reconstruction settings. To address the issue, we propose an optimization strategy that effectively regularizes splat features by modeling them as the outputs of a corresponding implicit neural field. This results in a consistent enhancement of reconstruction quality across various scenarios. Our approach effectively handles static and dynamic cases, as demonstrated by extensive testing across different setups and scene complexities.
RoHM: Robust Human Motion Reconstruction via Diffusion
Jan 16, 2024



We propose RoHM, an approach for robust 3D human motion reconstruction from monocular RGB(-D) videos in the presence of noise and occlusions. Most previous approaches either train neural networks to directly regress motion in 3D or learn data-driven motion priors and combine them with optimization at test time. The former do not recover globally coherent motion and fail under occlusions; the latter are time-consuming, prone to local minima, and require manual tuning. To overcome these shortcomings, we exploit the iterative, denoising nature of diffusion models. RoHM is a novel diffusion-based motion model that, conditioned on noisy and occluded input data, reconstructs complete, plausible motions in consistent global coordinates. Given the complexity of the problem -- requiring one to address different tasks (denoising and infilling) in different solution spaces (local and global motion) -- we decompose it into two sub-tasks and learn two models, one for global trajectory and one for local motion. To capture the correlations between the two, we then introduce a novel conditioning module, combining it with an iterative inference scheme. We apply RoHM to a variety of tasks -- from motion reconstruction and denoising to spatial and temporal infilling. Extensive experiments on three popular datasets show that our method outperforms state-of-the-art approaches qualitatively and quantitatively, while being faster at test time. The code will be available at https://sanweiliti.github.io/ROHM/ROHM.html.
FLAG: Flow-based 3D Avatar Generation from Sparse Observations
Mar 11, 2022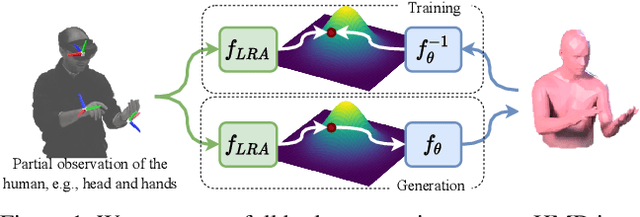

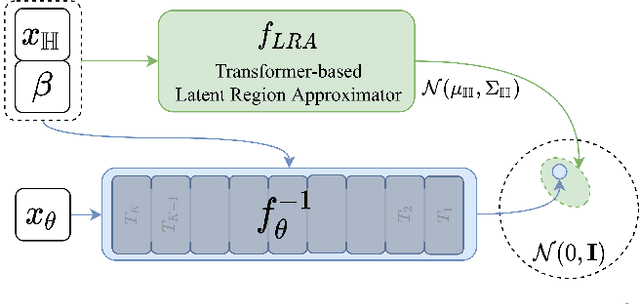
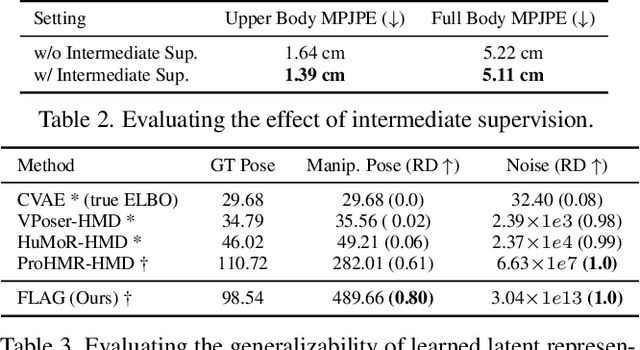
To represent people in mixed reality applications for collaboration and communication, we need to generate realistic and faithful avatar poses. However, the signal streams that can be applied for this task from head-mounted devices (HMDs) are typically limited to head pose and hand pose estimates. While these signals are valuable, they are an incomplete representation of the human body, making it challenging to generate a faithful full-body avatar. We address this challenge by developing a flow-based generative model of the 3D human body from sparse observations, wherein we learn not only a conditional distribution of 3D human pose, but also a probabilistic mapping from observations to the latent space from which we can generate a plausible pose along with uncertainty estimates for the joints. We show that our approach is not only a strong predictive model, but can also act as an efficient pose prior in different optimization settings where a good initial latent code plays a major role.
Spatial Computing and Intuitive Interaction: Bringing Mixed Reality and Robotics Together
Feb 03, 2022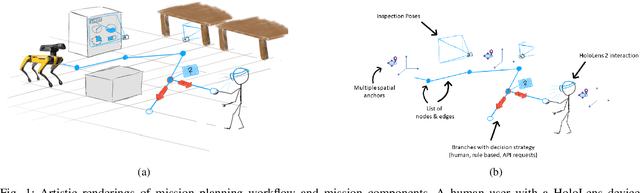

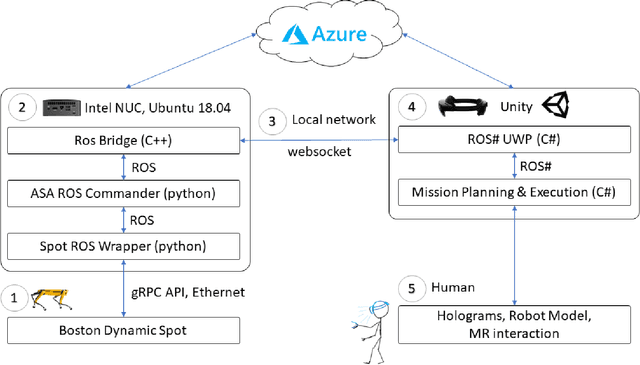

Spatial computing -- the ability of devices to be aware of their surroundings and to represent this digitally -- offers novel capabilities in human-robot interaction. In particular, the combination of spatial computing and egocentric sensing on mixed reality devices enables them to capture and understand human actions and translate these to actions with spatial meaning, which offers exciting new possibilities for collaboration between humans and robots. This paper presents several human-robot systems that utilize these capabilities to enable novel robot use cases: mission planning for inspection, gesture-based control, and immersive teleoperation. These works demonstrate the power of mixed reality as a tool for human-robot interaction, and the potential of spatial computing and mixed reality to drive the future of human-robot interaction.
EgoBody: Human Body Shape, Motion and Social Interactions from Head-Mounted Devices
Dec 14, 2021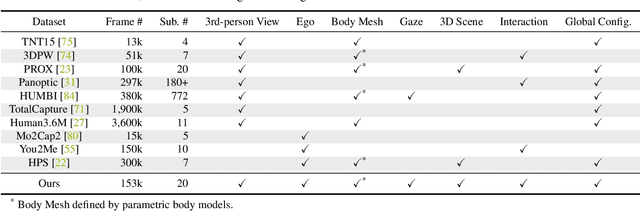
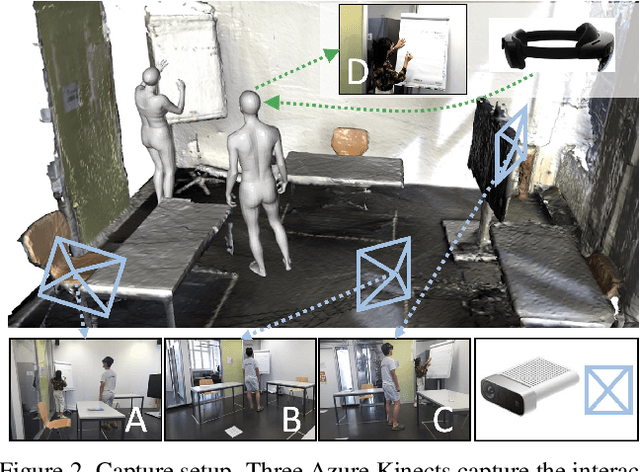


Understanding social interactions from first-person views is crucial for many applications, ranging from assistive robotics to AR/VR. A first step for reasoning about interactions is to understand human pose and shape. However, research in this area is currently hindered by the lack of data. Existing datasets are limited in terms of either size, annotations, ground-truth capture modalities or the diversity of interactions. We address this shortcoming by proposing EgoBody, a novel large-scale dataset for social interactions in complex 3D scenes. We employ Microsoft HoloLens2 headsets to record rich egocentric data streams (including RGB, depth, eye gaze, head and hand tracking). To obtain accurate 3D ground-truth, we calibrate the headset with a multi-Kinect rig and fit expressive SMPL-X body meshes to multi-view RGB-D frames, reconstructing 3D human poses and shapes relative to the scene. We collect 68 sequences, spanning diverse sociological interaction categories, and propose the first benchmark for 3D full-body pose and shape estimation from egocentric views. Our dataset and code will be available for research at https://sanweiliti.github.io/egobody/egobody.html.
Learning to Fit Morphable Models
Nov 29, 2021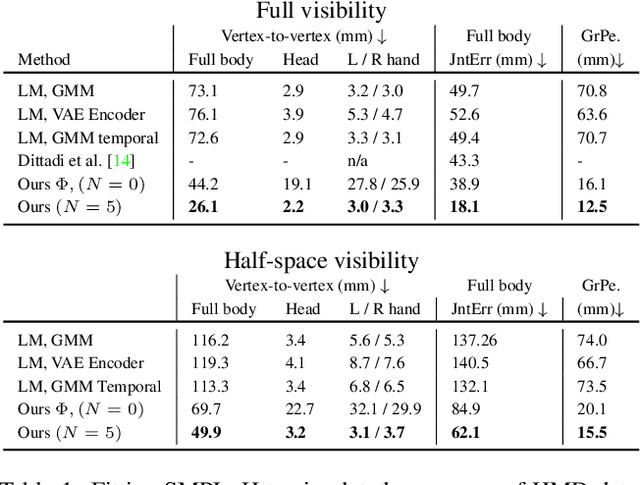
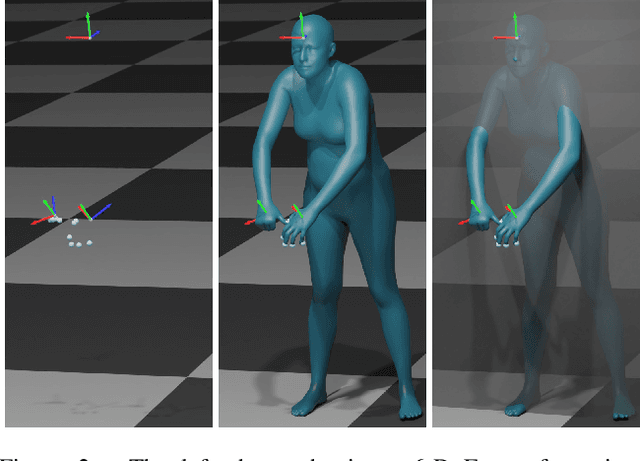


Fitting parametric models of human bodies, hands or faces to sparse input signals in an accurate, robust, and fast manner has the promise of significantly improving immersion in AR and VR scenarios. A common first step in systems that tackle these problems is to regress the parameters of the parametric model directly from the input data. This approach is fast, robust, and is a good starting point for an iterative minimization algorithm. The latter searches for the minimum of an energy function, typically composed of a data term and priors that encode our knowledge about the problem's structure. While this is undoubtedly a very successful recipe, priors are often hand defined heuristics and finding the right balance between the different terms to achieve high quality results is a non-trivial task. Furthermore, converting and optimizing these systems to run in a performant way requires custom implementations that demand significant time investments from both engineers and domain experts. In this work, we build upon recent advances in learned optimization and propose an update rule inspired by the classic Levenberg-Marquardt algorithm. We show the effectiveness of the proposed neural optimizer on the problems of 3D body surface estimation from a head-mounted device and face fitting from 2D landmarks. Our method can easily be applied to new model fitting problems and offers a competitive alternative to well tuned 'traditional' model fitting pipelines, both in terms of accuracy and speed.
Learning Motion Priors for 4D Human Body Capture in 3D Scenes
Aug 23, 2021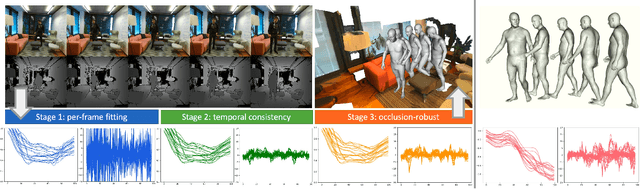
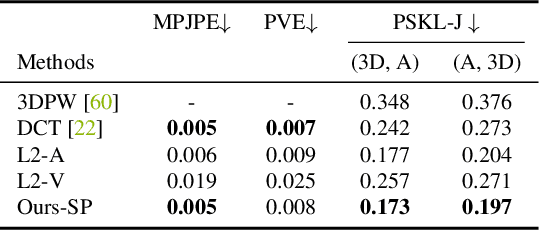
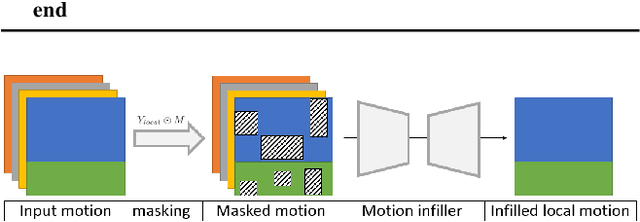
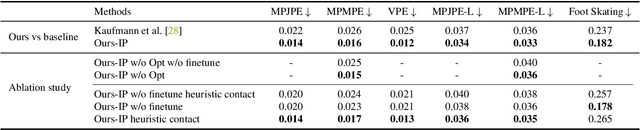
Recovering high-quality 3D human motion in complex scenes from monocular videos is important for many applications, ranging from AR/VR to robotics. However, capturing realistic human-scene interactions, while dealing with occlusions and partial views, is challenging; current approaches are still far from achieving compelling results. We address this problem by proposing LEMO: LEarning human MOtion priors for 4D human body capture. By leveraging the large-scale motion capture dataset AMASS, we introduce a novel motion smoothness prior, which strongly reduces the jitters exhibited by poses recovered over a sequence. Furthermore, to handle contacts and occlusions occurring frequently in body-scene interactions, we design a contact friction term and a contact-aware motion infiller obtained via per-instance self-supervised training. To prove the effectiveness of the proposed motion priors, we combine them into a novel pipeline for 4D human body capture in 3D scenes. With our pipeline, we demonstrate high-quality 4D human body capture, reconstructing smooth motions and physically plausible body-scene interactions. The code and data are available at https://sanweiliti.github.io/LEMO/LEMO.html.