 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFLAG: Flow-based 3D Avatar Generation from Sparse Observations
Mar 11, 2022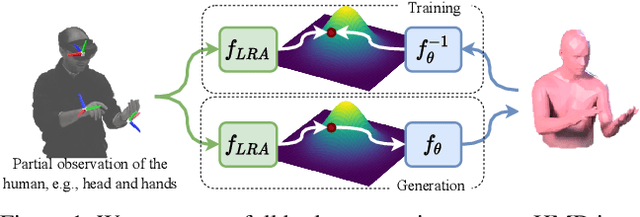

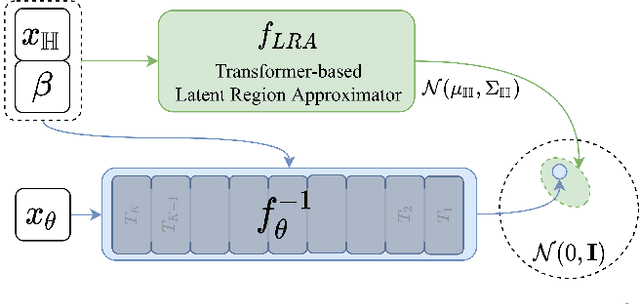
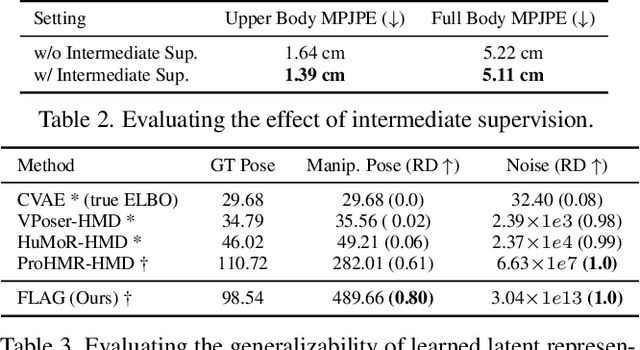
To represent people in mixed reality applications for collaboration and communication, we need to generate realistic and faithful avatar poses. However, the signal streams that can be applied for this task from head-mounted devices (HMDs) are typically limited to head pose and hand pose estimates. While these signals are valuable, they are an incomplete representation of the human body, making it challenging to generate a faithful full-body avatar. We address this challenge by developing a flow-based generative model of the 3D human body from sparse observations, wherein we learn not only a conditional distribution of 3D human pose, but also a probabilistic mapping from observations to the latent space from which we can generate a plausible pose along with uncertainty estimates for the joints. We show that our approach is not only a strong predictive model, but can also act as an efficient pose prior in different optimization settings where a good initial latent code plays a major role.
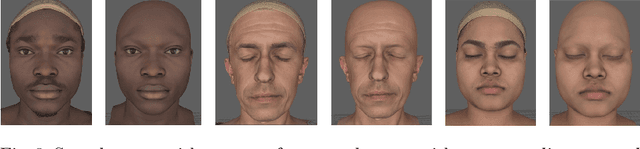
Fake It Till You Make It: Face analysis in the wild using synthetic data alone
Oct 05, 2021
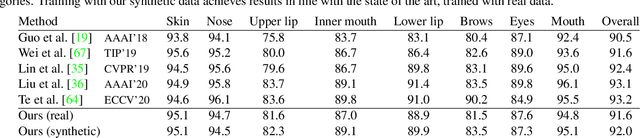


We demonstrate that it is possible to perform face-related computer vision in the wild using synthetic data alone. The community has long enjoyed the benefits of synthesizing training data with graphics, but the domain gap between real and synthetic data has remained a problem, especially for human faces. Researchers have tried to bridge this gap with data mixing, domain adaptation, and domain-adversarial training, but we show that it is possible to synthesize data with minimal domain gap, so that models trained on synthetic data generalize to real in-the-wild datasets. We describe how to combine a procedurally-generated parametric 3D face model with a comprehensive library of hand-crafted assets to render training images with unprecedented realism and diversity. We train machine learning systems for face-related tasks such as landmark localization and face parsing, showing that synthetic data can both match real data in accuracy as well as open up new approaches where manual labelling would be impossible.
HoloLens 2 Research Mode as a Tool for Computer Vision Research
Aug 25, 2020
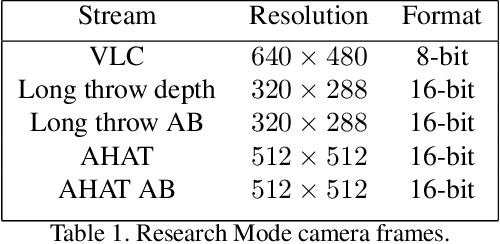


Mixed reality headsets, such as the Microsoft HoloLens 2, are powerful sensing devices with integrated compute capabilities, which makes it an ideal platform for computer vision research. In this technical report, we present HoloLens 2 Research Mode, an API and a set of tools enabling access to the raw sensor streams. We provide an overview of the API and explain how it can be used to build mixed reality applications based on processing sensor data. We also show how to combine the Research Mode sensor data with the built-in eye and hand tracking capabilities provided by HoloLens 2. By releasing the Research Mode API and a set of open-source tools, we aim to foster further research in the fields of computer vision as well as robotics and encourage contributions from the research community.
A high fidelity synthetic face framework for computer vision
Jul 16, 2020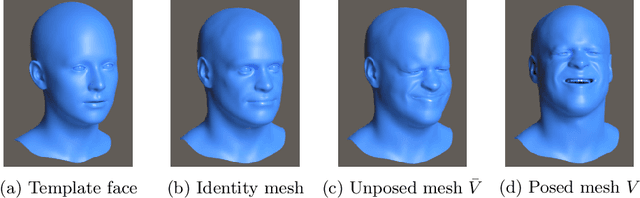


Analysis of faces is one of the core applications of computer vision, with tasks ranging from landmark alignment, head pose estimation, expression recognition, and face recognition among others. However, building reliable methods requires time-consuming data collection and often even more time-consuming manual annotation, which can be unreliable. In our work we propose synthesizing such facial data, including ground truth annotations that would be almost impossible to acquire through manual annotation at the consistency and scale possible through use of synthetic data. We use a parametric face model together with hand crafted assets which enable us to generate training data with unprecedented quality and diversity (varying shape, texture, expression, pose, lighting, and hair).
The Phong Surface: Efficient 3D Model Fitting using Lifted Optimization
Jul 09, 2020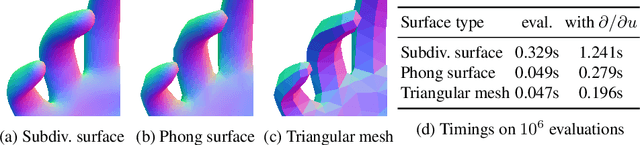
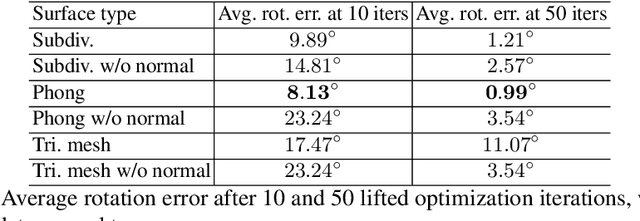
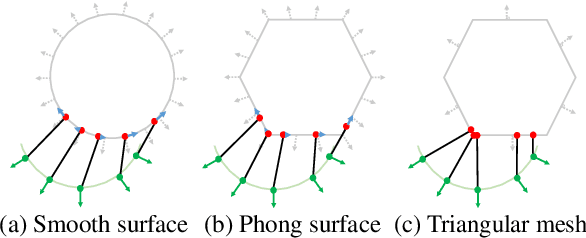
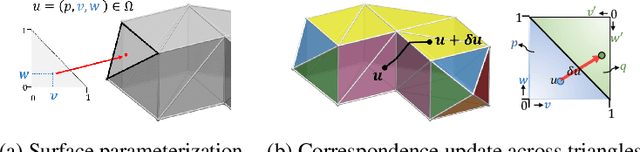
Realtime perceptual and interaction capabilities in mixed reality require a range of 3D tracking problems to be solved at low latency on resource-constrained hardware such as head-mounted devices. Indeed, for devices such as HoloLens 2 where the CPU and GPU are left available for applications, multiple tracking subsystems are required to run on a continuous, real-time basis while sharing a single Digital Signal Processor. To solve model-fitting problems for HoloLens 2 hand tracking, where the computational budget is approximately 100 times smaller than an iPhone 7, we introduce a new surface model: the `Phong surface'. Using ideas from computer graphics, the Phong surface describes the same 3D shape as a triangulated mesh model, but with continuous surface normals which enable the use of lifting-based optimization, providing significant efficiency gains over ICP-based methods. We show that Phong surfaces retain the convergence benefits of smoother surface models, while triangle meshes do not.