 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEyelid Fold Consistency in Facial Modeling
Oct 17, 2024



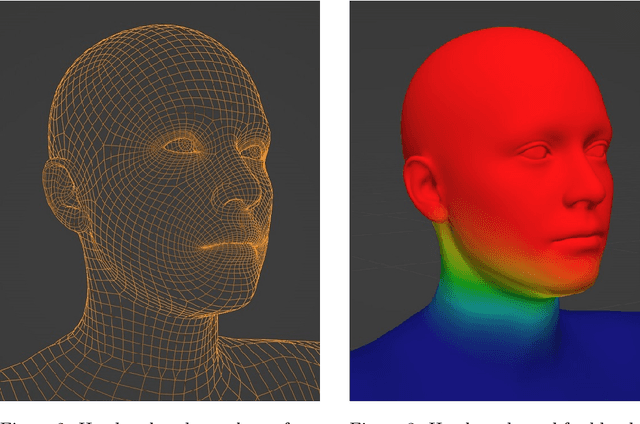
Eyelid shape is integral to identity and likeness in human facial modeling. Human eyelids are diverse in appearance with varied skin fold and epicanthal fold morphology between individuals. Existing parametric face models express eyelid shape variation to an extent, but do not preserve sufficient likeness across a diverse range of individuals. We propose a new definition of eyelid fold consistency and implement geometric processing techniques to model diverse eyelid shapes in a unified topology. Using this method we reprocess data used to train a parametric face model and demonstrate significant improvements in face-related machine learning tasks.
SimpleEgo: Predicting Probabilistic Body Pose from Egocentric Cameras
Jan 26, 2024



Our work addresses the problem of egocentric human pose estimation from downwards-facing cameras on head-mounted devices (HMD). This presents a challenging scenario, as parts of the body often fall outside of the image or are occluded. Previous solutions minimize this problem by using fish-eye camera lenses to capture a wider view, but these can present hardware design issues. They also predict 2D heat-maps per joint and lift them to 3D space to deal with self-occlusions, but this requires large network architectures which are impractical to deploy on resource-constrained HMDs. We predict pose from images captured with conventional rectilinear camera lenses. This resolves hardware design issues, but means body parts are often out of frame. As such, we directly regress probabilistic joint rotations represented as matrix Fisher distributions for a parameterized body model. This allows us to quantify pose uncertainties and explain out-of-frame or occluded joints. This also removes the need to compute 2D heat-maps and allows for simplified DNN architectures which require less compute. Given the lack of egocentric datasets using rectilinear camera lenses, we introduce the SynthEgo dataset, a synthetic dataset with 60K stereo images containing high diversity of pose, shape, clothing and skin tone. Our approach achieves state-of-the-art results for this challenging configuration, reducing mean per-joint position error by 23% overall and 58% for the lower body. Our architecture also has eight times fewer parameters and runs twice as fast as the current state-of-the-art. Experiments show that training on our synthetic dataset leads to good generalization to real world images without fine-tuning.
Procedural Humans for Computer Vision
Jan 03, 2023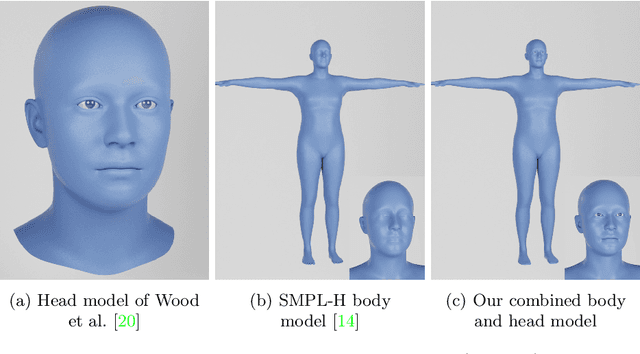
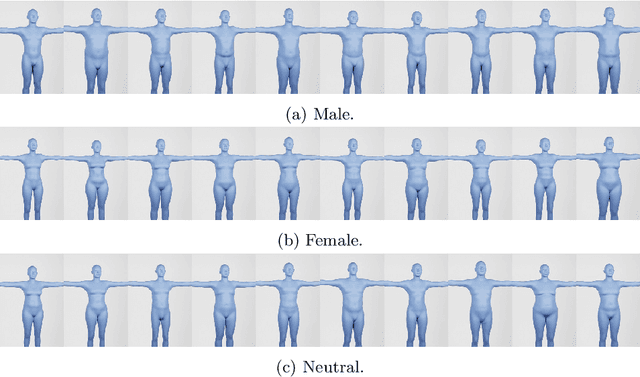

Recent work has shown the benefits of synthetic data for use in computer vision, with applications ranging from autonomous driving to face landmark detection and reconstruction. There are a number of benefits of using synthetic data from privacy preservation and bias elimination to quality and feasibility of annotation. Generating human-centered synthetic data is a particular challenge in terms of realism and domain-gap, though recent work has shown that effective machine learning models can be trained using synthetic face data alone. We show that this can be extended to include the full body by building on the pipeline of Wood et al. to generate synthetic images of humans in their entirety, with ground-truth annotations for computer vision applications. In this report we describe how we construct a parametric model of the face and body, including articulated hands; our rendering pipeline to generate realistic images of humans based on this body model; an approach for training DNNs to regress a dense set of landmarks covering the entire body; and a method for fitting our body model to dense landmarks predicted from multiple views.
Fake It Till You Make It: Face analysis in the wild using synthetic data alone
Oct 05, 2021
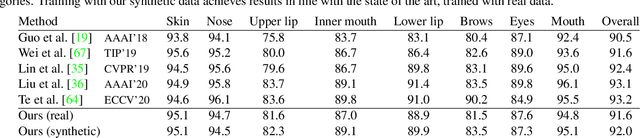


We demonstrate that it is possible to perform face-related computer vision in the wild using synthetic data alone. The community has long enjoyed the benefits of synthesizing training data with graphics, but the domain gap between real and synthetic data has remained a problem, especially for human faces. Researchers have tried to bridge this gap with data mixing, domain adaptation, and domain-adversarial training, but we show that it is possible to synthesize data with minimal domain gap, so that models trained on synthetic data generalize to real in-the-wild datasets. We describe how to combine a procedurally-generated parametric 3D face model with a comprehensive library of hand-crafted assets to render training images with unprecedented realism and diversity. We train machine learning systems for face-related tasks such as landmark localization and face parsing, showing that synthetic data can both match real data in accuracy as well as open up new approaches where manual labelling would be impossible.
CONFIG: Controllable Neural Face Image Generation
May 12, 2020
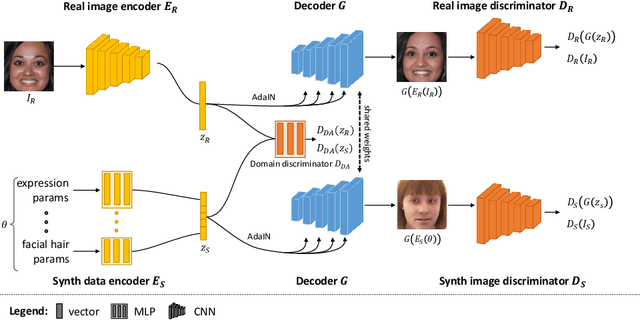


Our ability to sample realistic natural images, particularly faces, has advanced by leaps and bounds in recent years, yet our ability to exert fine-tuned control over the generative process has lagged behind. If this new technology is to find practical uses, we need to achieve a level of control over generative networks which, without sacrificing realism, is on par with that seen in computer graphics and character animation. To this end we propose ConfigNet, a neural face model that allows for controlling individual aspects of output images in semantically meaningful ways and that is a significant step on the path towards finely-controllable neural rendering. ConfigNet is trained on real face images as well as synthetic face renders. Our novel method uses synthetic data to factorize the latent space into elements that correspond to the inputs of a traditional rendering pipeline, separating aspects such as head pose, facial expression, hair style, illumination, and many others which are very hard to annotate in real data. The real images, which are presented to the network without labels, extend the variety of the generated images and encourage realism. Finally, we propose an evaluation criterion using an attribute detection network combined with a user study and demonstrate state-of-the-art individual control over attributes in the output images.
Multimodal Sentiment Analysis with Word-Level Fusion and Reinforcement Learning
Feb 03, 2018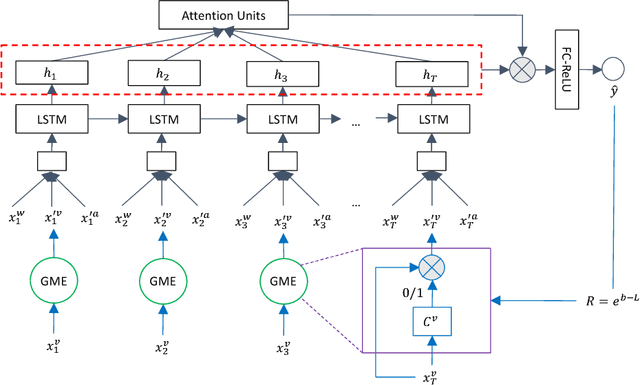
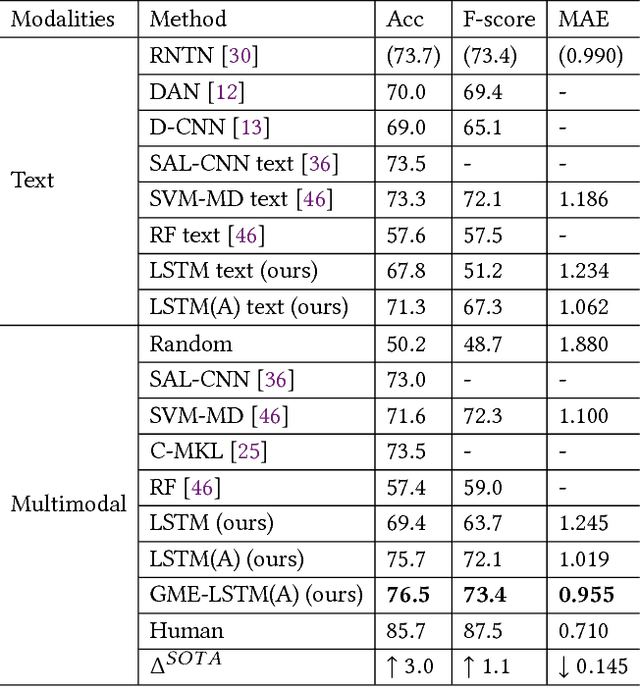

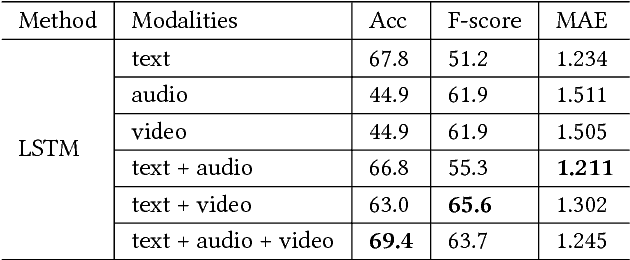
With the increasing popularity of video sharing websites such as YouTube and Facebook, multimodal sentiment analysis has received increasing attention from the scientific community. Contrary to previous works in multimodal sentiment analysis which focus on holistic information in speech segments such as bag of words representations and average facial expression intensity, we develop a novel deep architecture for multimodal sentiment analysis that performs modality fusion at the word level. In this paper, we propose the Gated Multimodal Embedding LSTM with Temporal Attention (GME-LSTM(A)) model that is composed of 2 modules. The Gated Multimodal Embedding alleviates the difficulties of fusion when there are noisy modalities. The LSTM with Temporal Attention performs word level fusion at a finer fusion resolution between input modalities and attends to the most important time steps. As a result, the GME-LSTM(A) is able to better model the multimodal structure of speech through time and perform better sentiment comprehension. We demonstrate the effectiveness of this approach on the publicly-available Multimodal Corpus of Sentiment Intensity and Subjectivity Analysis (CMU-MOSI) dataset by achieving state-of-the-art sentiment classification and regression results. Qualitative analysis on our model emphasizes the importance of the Temporal Attention Layer in sentiment prediction because the additional acoustic and visual modalities are noisy. We also demonstrate the effectiveness of the Gated Multimodal Embedding in selectively filtering these noisy modalities out. Our results and analysis open new areas in the study of sentiment analysis in human communication and provide new models for multimodal fusion.
Attended End-to-end Architecture for Age Estimation from Facial Expression Videos
Nov 23, 2017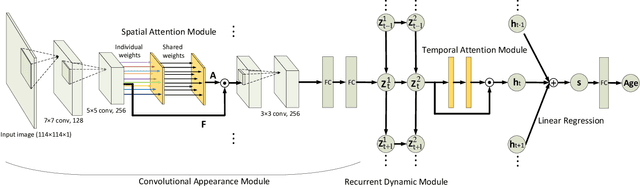
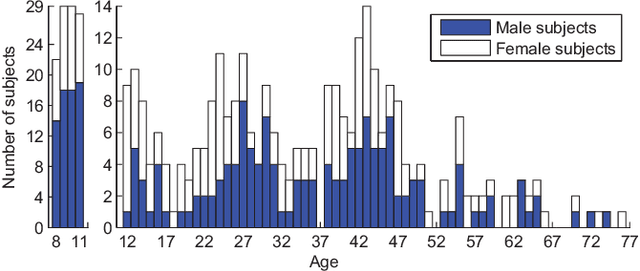
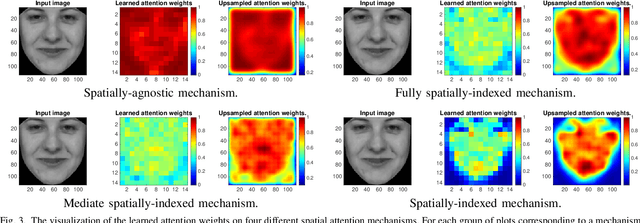
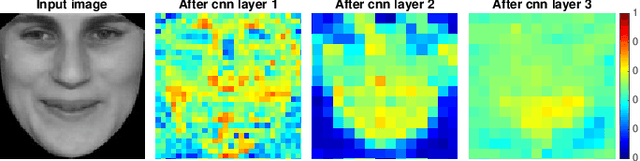
The main challenges of age estimation from facial expression videos lie not only in the modeling of the static facial appearance, but also in the capturing of the temporal facial dynamics. Traditional techniques to this problem focus on constructing handcrafted features to explore the discriminative information contained in facial appearance and dynamics separately. This relies on sophisticated feature-refinement and framework-design. In this paper, we present an end-to-end architecture for age estimation which is able to simultaneously learn both the appearance and dynamics of age from raw videos of facial expressions. Specifically, we employ convolutional neural networks to extract effective latent appearance representations and feed them into recurrent networks to model the temporal dynamics. More importantly, we propose to leverage attention models for salience detection in both the spatial domain for each single image and the temporal domain for the whole video as well. We design a specific spatially-indexed attention mechanism among the convolutional layers to extract the salient facial regions in each individual image, and a temporal attention layer to assign attention weights to each frame. This two-pronged approach not only improves the performance by allowing the model to focus on informative frames and facial areas, but it also offers an interpretable correspondence between the spatial facial regions as well as temporal frames, and the task of age estimation. We demonstrate the strong performance of our model in experiments on a large, gender-balanced database with 400 subjects with ages spanning from 8 to 76 years. Experiments reveal that our model exhibits significant superiority over the state-of-the-art methods given sufficient training data.
Multimodal Machine Learning: A Survey and Taxonomy
Aug 01, 2017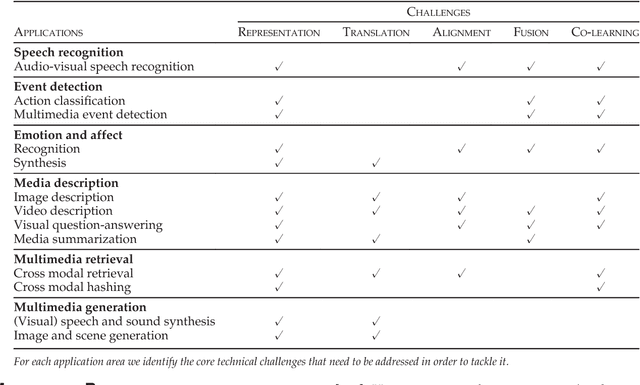
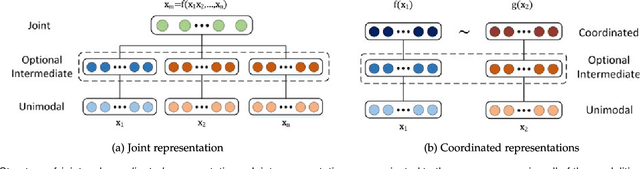
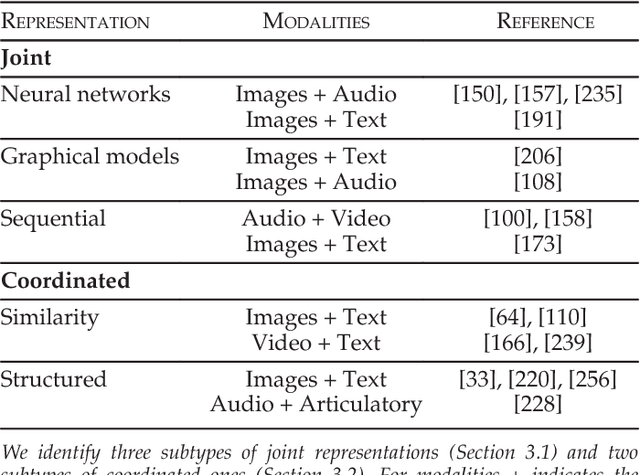
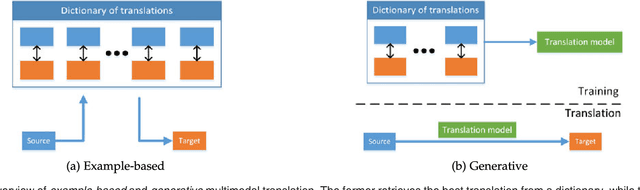
Our experience of the world is multimodal - we see objects, hear sounds, feel texture, smell odors, and taste flavors. Modality refers to the way in which something happens or is experienced and a research problem is characterized as multimodal when it includes multiple such modalities. In order for Artificial Intelligence to make progress in understanding the world around us, it needs to be able to interpret such multimodal signals together. Multimodal machine learning aims to build models that can process and relate information from multiple modalities. It is a vibrant multi-disciplinary field of increasing importance and with extraordinary potential. Instead of focusing on specific multimodal applications, this paper surveys the recent advances in multimodal machine learning itself and presents them in a common taxonomy. We go beyond the typical early and late fusion categorization and identify broader challenges that are faced by multimodal machine learning, namely: representation, translation, alignment, fusion, and co-learning. This new taxonomy will enable researchers to better understand the state of the field and identify directions for future research.
Convolutional Experts Constrained Local Model for Facial Landmark Detection
Jul 26, 2017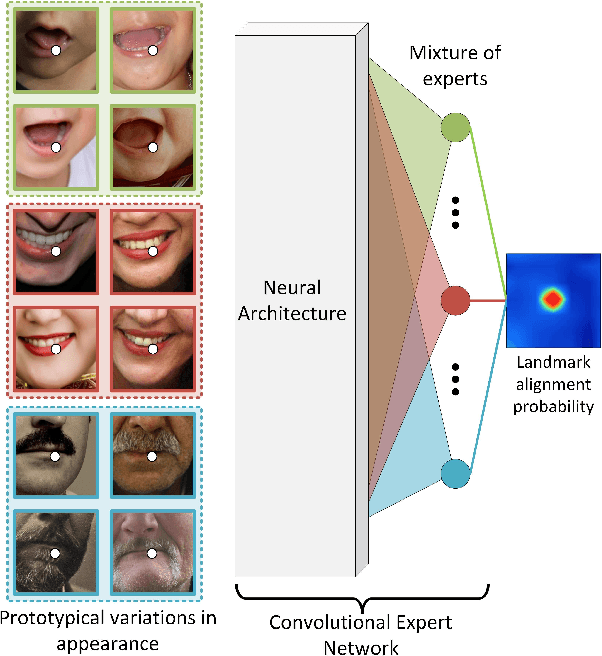
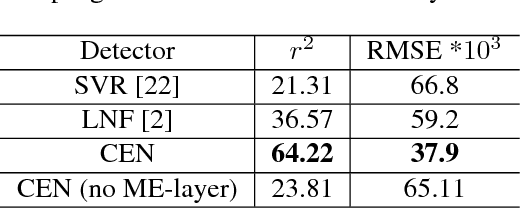
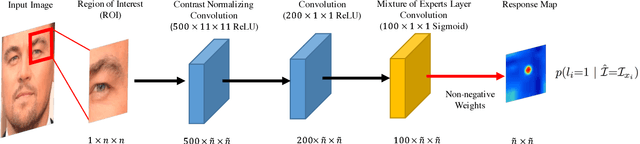
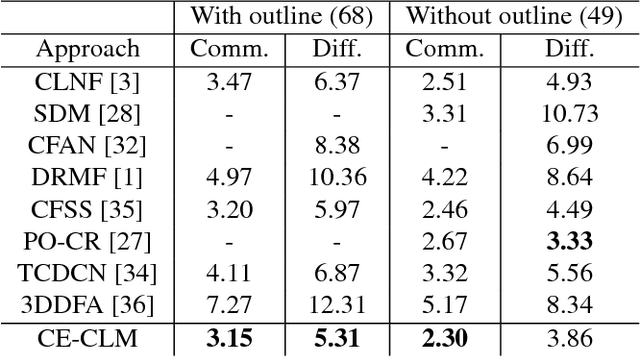
Constrained Local Models (CLMs) are a well-established family of methods for facial landmark detection. However, they have recently fallen out of favor to cascaded regression-based approaches. This is in part due to the inability of existing CLM local detectors to model the very complex individual landmark appearance that is affected by expression, illumination, facial hair, makeup, and accessories. In our work, we present a novel local detector -- Convolutional Experts Network (CEN) -- that brings together the advantages of neural architectures and mixtures of experts in an end-to-end framework. We further propose a Convolutional Experts Constrained Local Model (CE-CLM) algorithm that uses CEN as local detectors. We demonstrate that our proposed CE-CLM algorithm outperforms competitive state-of-the-art baselines for facial landmark detection by a large margin on four publicly-available datasets. Our approach is especially accurate and robust on challenging profile images.
Preserving Intermediate Objectives: One Simple Trick to Improve Learning for Hierarchical Models
Jun 23, 2017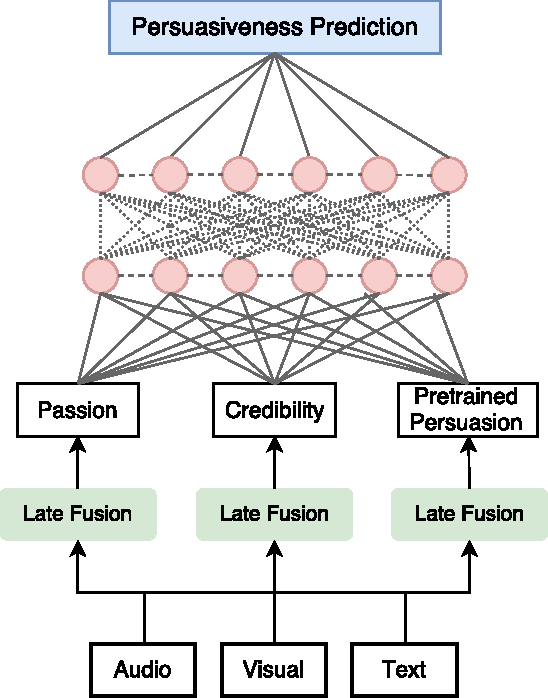
Hierarchical models are utilized in a wide variety of problems which are characterized by task hierarchies, where predictions on smaller subtasks are useful for trying to predict a final task. Typically, neural networks are first trained for the subtasks, and the predictions of these networks are subsequently used as additional features when training a model and doing inference for a final task. In this work, we focus on improving learning for such hierarchical models and demonstrate our method on the task of speaker trait prediction. Speaker trait prediction aims to computationally identify which personality traits a speaker might be perceived to have, and has been of great interest to both the Artificial Intelligence and Social Science communities. Persuasiveness prediction in particular has been of interest, as persuasive speakers have a large amount of influence on our thoughts, opinions and beliefs. In this work, we examine how leveraging the relationship between related speaker traits in a hierarchical structure can help improve our ability to predict how persuasive a speaker is. We present a novel algorithm that allows us to backpropagate through this hierarchy. This hierarchical model achieves a 25% relative error reduction in classification accuracy over current state-of-the art methods on the publicly available POM dataset.