 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnyStyle: Single-Pass Multimodal Stylization for 3D Gaussian Splatting
Feb 03, 2026The growing demand for rapid and scalable 3D asset creation has driven interest in feed-forward 3D reconstruction methods, with 3D Gaussian Splatting (3DGS) emerging as an effective scene representation. While recent approaches have demonstrated pose-free reconstruction from unposed image collections, integrating stylization or appearance control into such pipelines remains underexplored. Existing attempts largely rely on image-based conditioning, which limits both controllability and flexibility. In this work, we introduce AnyStyle, a feed-forward 3D reconstruction and stylization framework that enables pose-free, zero-shot stylization through multimodal conditioning. Our method supports both textual and visual style inputs, allowing users to control the scene appearance using natural language descriptions or reference images. We propose a modular stylization architecture that requires only minimal architectural modifications and can be integrated into existing feed-forward 3D reconstruction backbones. Experiments demonstrate that AnyStyle improves style controllability over prior feed-forward stylization methods while preserving high-quality geometric reconstruction. A user study further confirms that AnyStyle achieves superior stylization quality compared to an existing state-of-the-art approach. Repository: https://github.com/joaxkal/AnyStyle.
GASP: Gaussian Avatars with Synthetic Priors
Dec 10, 2024



Gaussian Splatting has changed the game for real-time photo-realistic rendering. One of the most popular applications of Gaussian Splatting is to create animatable avatars, known as Gaussian Avatars. Recent works have pushed the boundaries of quality and rendering efficiency but suffer from two main limitations. Either they require expensive multi-camera rigs to produce avatars with free-view rendering, or they can be trained with a single camera but only rendered at high quality from this fixed viewpoint. An ideal model would be trained using a short monocular video or image from available hardware, such as a webcam, and rendered from any view. To this end, we propose GASP: Gaussian Avatars with Synthetic Priors. To overcome the limitations of existing datasets, we exploit the pixel-perfect nature of synthetic data to train a Gaussian Avatar prior. By fitting this prior model to a single photo or video and fine-tuning it, we get a high-quality Gaussian Avatar, which supports 360$^\circ$ rendering. Our prior is only required for fitting, not inference, enabling real-time application. Through our method, we obtain high-quality, animatable Avatars from limited data which can be animated and rendered at 70fps on commercial hardware. See our project page (https://microsoft.github.io/GASP/) for results.
LumiGauss: High-Fidelity Outdoor Relighting with 2D Gaussian Splatting
Aug 06, 2024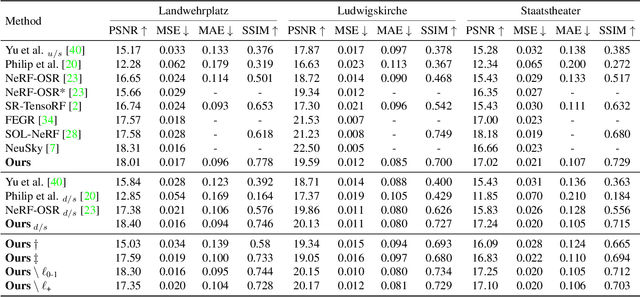
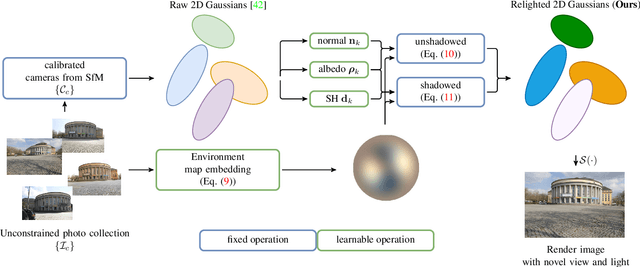

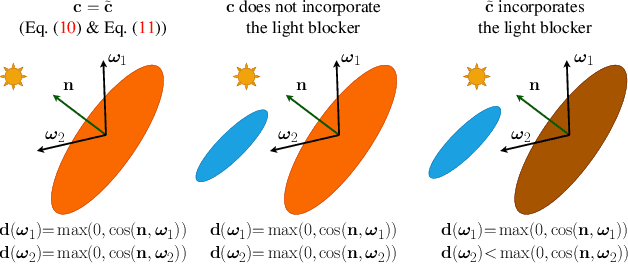
Decoupling lighting from geometry using unconstrained photo collections is notoriously challenging. Solving it would benefit many users, as creating complex 3D assets takes days of manual labor. Many previous works have attempted to address this issue, often at the expense of output fidelity, which questions the practicality of such methods. We introduce LumiGauss, a technique that tackles 3D reconstruction of scenes and environmental lighting through 2D Gaussian Splatting. Our approach yields high-quality scene reconstructions and enables realistic lighting synthesis under novel environment maps. We also propose a method for enhancing the quality of shadows, common in outdoor scenes, by exploiting spherical harmonics properties. Our approach facilitates seamless integration with game engines and enables the use of fast precomputed radiance transfer. We validate our method on the NeRF-OSR dataset, demonstrating superior performance over baseline methods. Moreover, LumiGauss can synthesize realistic images when applying novel environment maps.
BlendFields: Few-Shot Example-Driven Facial Modeling
May 12, 2023
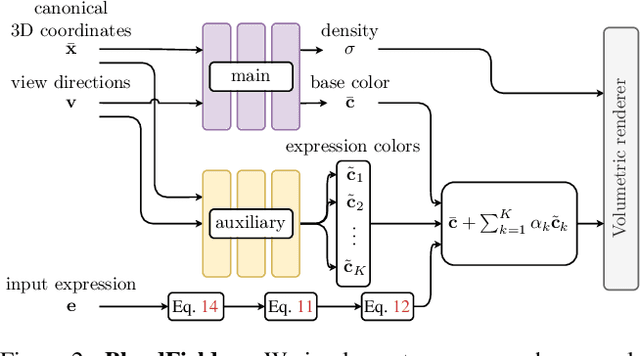
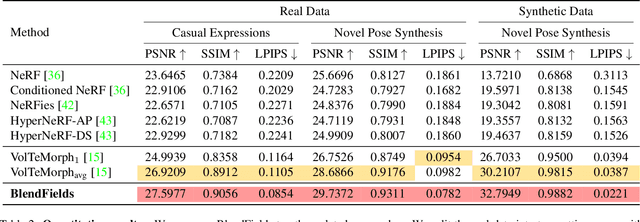
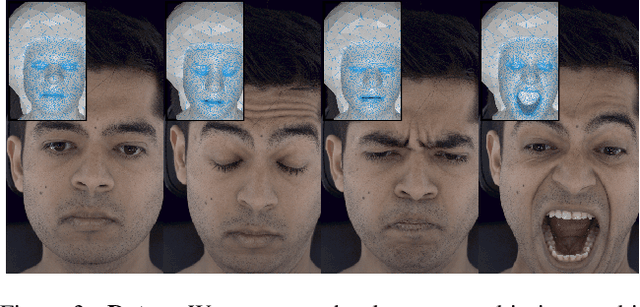
Generating faithful visualizations of human faces requires capturing both coarse and fine-level details of the face geometry and appearance. Existing methods are either data-driven, requiring an extensive corpus of data not publicly accessible to the research community, or fail to capture fine details because they rely on geometric face models that cannot represent fine-grained details in texture with a mesh discretization and linear deformation designed to model only a coarse face geometry. We introduce a method that bridges this gap by drawing inspiration from traditional computer graphics techniques. Unseen expressions are modeled by blending appearance from a sparse set of extreme poses. This blending is performed by measuring local volumetric changes in those expressions and locally reproducing their appearance whenever a similar expression is performed at test time. We show that our method generalizes to unseen expressions, adding fine-grained effects on top of smooth volumetric deformations of a face, and demonstrate how it generalizes beyond faces.
VolTeMorph: Realtime, Controllable and Generalisable Animation of Volumetric Representations
Aug 01, 2022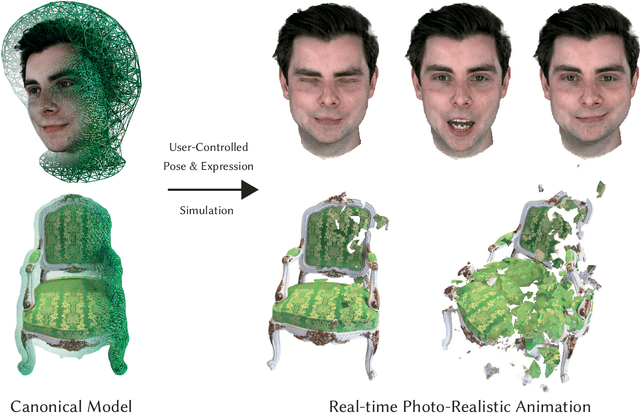
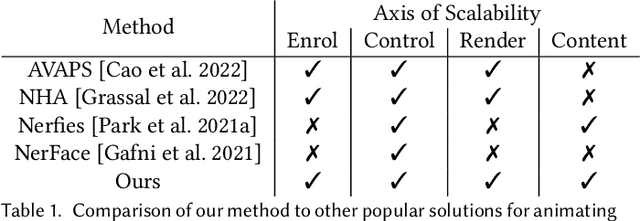
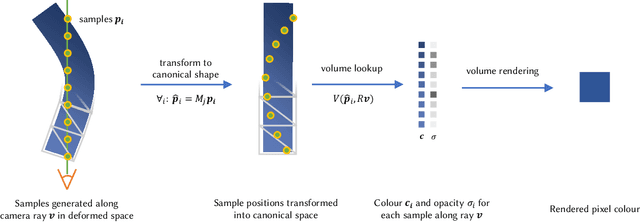
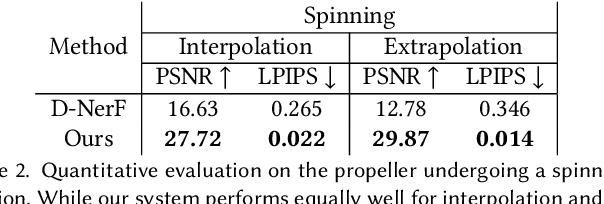
The recent increase in popularity of volumetric representations for scene reconstruction and novel view synthesis has put renewed focus on animating volumetric content at high visual quality and in real-time. While implicit deformation methods based on learned functions can produce impressive results, they are `black boxes' to artists and content creators, they require large amounts of training data to generalise meaningfully, and they do not produce realistic extrapolations outside the training data. In this work we solve these issues by introducing a volume deformation method which is real-time, easy to edit with off-the-shelf software and can extrapolate convincingly. To demonstrate the versatility of our method, we apply it in two scenarios: physics-based object deformation and telepresence where avatars are controlled using blendshapes. We also perform thorough experiments showing that our method compares favourably to both volumetric approaches combined with implicit deformation and methods based on mesh deformation.
CoNeRF: Controllable Neural Radiance Fields
Dec 06, 2021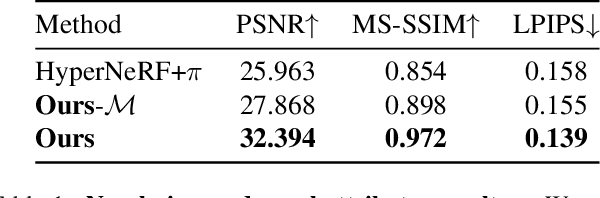

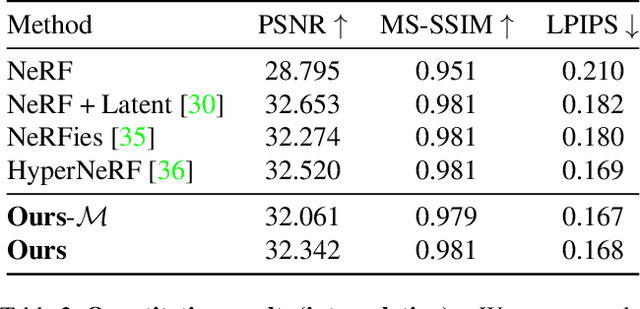

We extend neural 3D representations to allow for intuitive and interpretable user control beyond novel view rendering (i.e. camera control). We allow the user to annotate which part of the scene one wishes to control with just a small number of mask annotations in the training images. Our key idea is to treat the attributes as latent variables that are regressed by the neural network given the scene encoding. This leads to a few-shot learning framework, where attributes are discovered automatically by the framework, when annotations are not provided. We apply our method to various scenes with different types of controllable attributes (e.g. expression control on human faces, or state control in movement of inanimate objects). Overall, we demonstrate, to the best of our knowledge, for the first time novel view and novel attribute re-rendering of scenes from a single video.
FastNeRF: High-Fidelity Neural Rendering at 200FPS
Apr 15, 2021
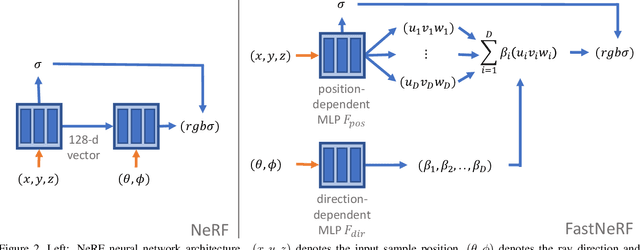
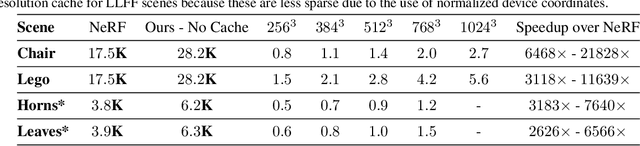
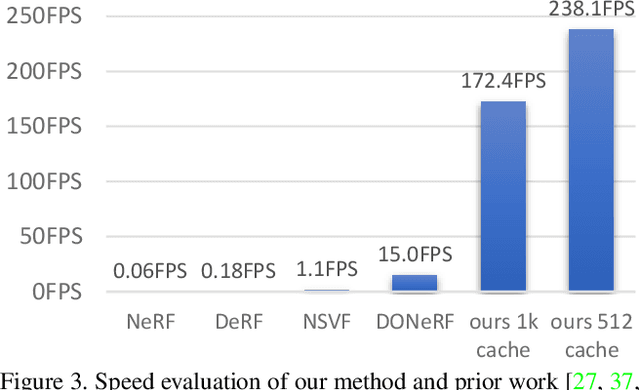
Recent work on Neural Radiance Fields (NeRF) showed how neural networks can be used to encode complex 3D environments that can be rendered photorealistically from novel viewpoints. Rendering these images is very computationally demanding and recent improvements are still a long way from enabling interactive rates, even on high-end hardware. Motivated by scenarios on mobile and mixed reality devices, we propose FastNeRF, the first NeRF-based system capable of rendering high fidelity photorealistic images at 200Hz on a high-end consumer GPU. The core of our method is a graphics-inspired factorization that allows for (i) compactly caching a deep radiance map at each position in space, (ii) efficiently querying that map using ray directions to estimate the pixel values in the rendered image. Extensive experiments show that the proposed method is 3000 times faster than the original NeRF algorithm and at least an order of magnitude faster than existing work on accelerating NeRF, while maintaining visual quality and extensibility.
TrajeVAE -- Controllable Human Motion Generation from Trajectories
Apr 01, 2021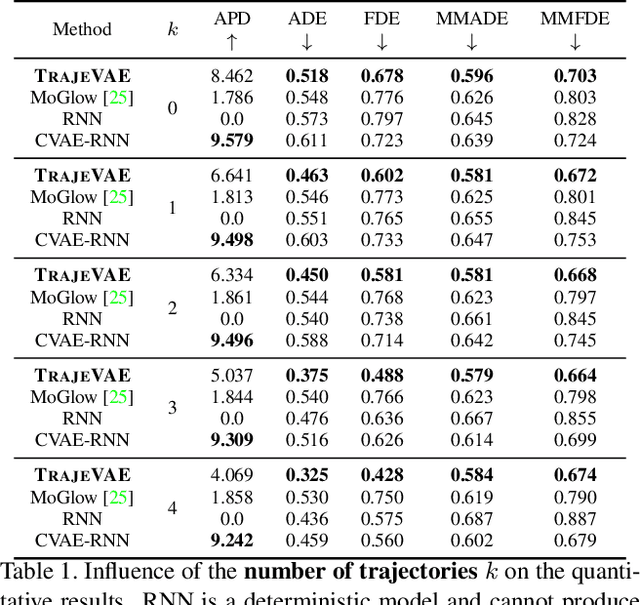
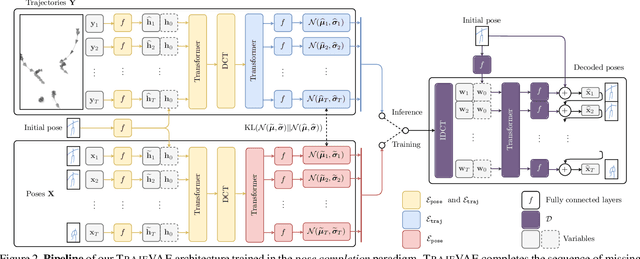
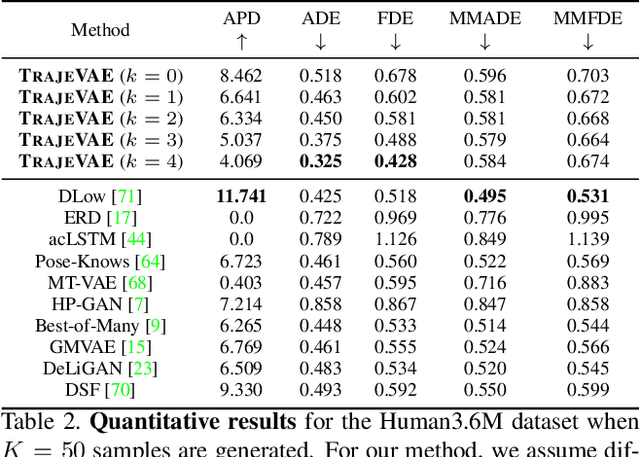
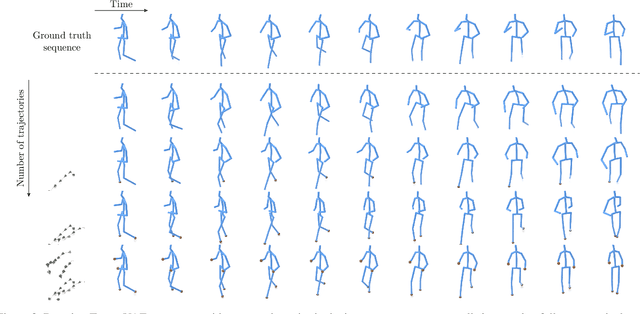
The generation of plausible and controllable 3D human motion animations is a long-standing problem that often requires a manual intervention of skilled artists. Existing machine learning approaches try to semi-automate this process by allowing the user to input partial information about the future movement. However, they are limited in two significant ways: they either base their pose prediction on past prior frames with no additional control over the future poses or allow the user to input only a single trajectory that precludes fine-grained control over the output. To mitigate these two issues, we reformulate the problem of future pose prediction into pose completion in space and time where trajectories are represented as poses with missing joints. We show that such a framework can generalize to other neural networks designed for future pose prediction. Once trained in this framework, a model is capable of predicting sequences from any number of trajectories. To leverage this notion, we propose a novel transformer-like architecture, TrajeVAE, that provides a versatile framework for 3D human animation. We demonstrate that TrajeVAE outperforms trajectory-based reference approaches and methods that base their predictions on past poses in terms of accuracy. We also show that it can predict reasonable future poses even if provided only with an initial pose.
A high fidelity synthetic face framework for computer vision
Jul 16, 2020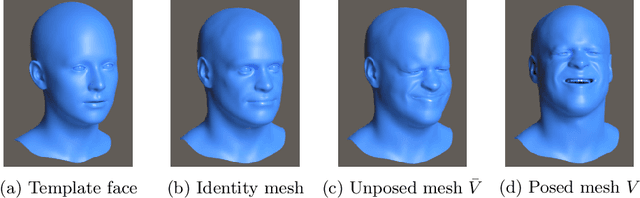

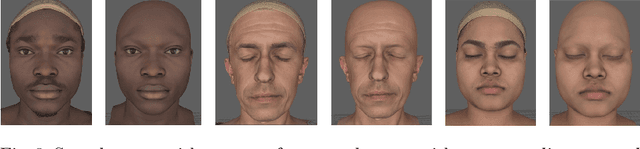

Analysis of faces is one of the core applications of computer vision, with tasks ranging from landmark alignment, head pose estimation, expression recognition, and face recognition among others. However, building reliable methods requires time-consuming data collection and often even more time-consuming manual annotation, which can be unreliable. In our work we propose synthesizing such facial data, including ground truth annotations that would be almost impossible to acquire through manual annotation at the consistency and scale possible through use of synthetic data. We use a parametric face model together with hand crafted assets which enable us to generate training data with unprecedented quality and diversity (varying shape, texture, expression, pose, lighting, and hair).
High Resolution Zero-Shot Domain Adaptation of Synthetically Rendered Face Images
Jun 26, 2020



Generating photorealistic images of human faces at scale remains a prohibitively difficult task using computer graphics approaches. This is because these require the simulation of light to be photorealistic, which in turn requires physically accurate modelling of geometry, materials, and light sources, for both the head and the surrounding scene. Non-photorealistic renders however are increasingly easy to produce. In contrast to computer graphics approaches, generative models learned from more readily available 2D image data have been shown to produce samples of human faces that are hard to distinguish from real data. The process of learning usually corresponds to a loss of control over the shape and appearance of the generated images. For instance, even simple disentangling tasks such as modifying the hair independently of the face, which is trivial to accomplish in a computer graphics approach, remains an open research question. In this work, we propose an algorithm that matches a non-photorealistic, synthetically generated image to a latent vector of a pretrained StyleGAN2 model which, in turn, maps the vector to a photorealistic image of a person of the same pose, expression, hair, and lighting. In contrast to most previous work, we require no synthetic training data. To the best of our knowledge, this is the first algorithm of its kind to work at a resolution of 1K and represents a significant leap forward in visual realism.