 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLumiMotion: Improving Gaussian Relighting with Scene Dynamics
Apr 13, 2026In 3D reconstruction, the problem of inverse rendering, namely recovering the illumination of the scene and the material properties, is fundamental. Existing Gaussian Splatting-based methods primarily target static scenes and often assume simplified or moderate lighting to avoid entangling shadows with surface appearance. This limits their ability to accurately separate lighting effects from material properties, particularly in real-world conditions. We address this limitation by leveraging dynamic elements - regions of the scene that undergo motion - as a supervisory signal for inverse rendering. Motion reveals the same surfaces under varying lighting conditions, providing stronger cues for disentangling material and illumination. This thesis is supported by our experimental results which show we improve LPIPS by 23% for albedo estimation and by 15% for scene relighting relative to next-best baseline. To this end, we introduce LumiMotion, the first Gaussian-based approach that leverages dynamics for inverse rendering and operates in arbitrary dynamic scenes. Our method learns a dynamic 2D Gaussian Splatting representation that employs a set of novel constraints which encourage the dynamic regions of the scene to deform, while keeping static regions stable. As we demonstrate, this separation is crucial for correct optimization of the albedo. Finally, we release a new synthetic benchmark comprising five scenes under four lighting conditions, each in both static and dynamic variants, for the first time enabling systematic evaluation of inverse rendering methods in dynamic environments and challenging lighting. Link to project page: https://joaxkal.github.io/LumiMotion/
AnyStyle: Single-Pass Multimodal Stylization for 3D Gaussian Splatting
Feb 03, 2026The growing demand for rapid and scalable 3D asset creation has driven interest in feed-forward 3D reconstruction methods, with 3D Gaussian Splatting (3DGS) emerging as an effective scene representation. While recent approaches have demonstrated pose-free reconstruction from unposed image collections, integrating stylization or appearance control into such pipelines remains underexplored. Existing attempts largely rely on image-based conditioning, which limits both controllability and flexibility. In this work, we introduce AnyStyle, a feed-forward 3D reconstruction and stylization framework that enables pose-free, zero-shot stylization through multimodal conditioning. Our method supports both textual and visual style inputs, allowing users to control the scene appearance using natural language descriptions or reference images. We propose a modular stylization architecture that requires only minimal architectural modifications and can be integrated into existing feed-forward 3D reconstruction backbones. Experiments demonstrate that AnyStyle improves style controllability over prior feed-forward stylization methods while preserving high-quality geometric reconstruction. A user study further confirms that AnyStyle achieves superior stylization quality compared to an existing state-of-the-art approach. Repository: https://github.com/joaxkal/AnyStyle.
SimuScope: Realistic Endoscopic Synthetic Dataset Generation through Surgical Simulation and Diffusion Models
Dec 03, 2024



Computer-assisted surgical (CAS) systems enhance surgical execution and outcomes by providing advanced support to surgeons. These systems often rely on deep learning models trained on complex, challenging-to-annotate data. While synthetic data generation can address these challenges, enhancing the realism of such data is crucial. This work introduces a multi-stage pipeline for generating realistic synthetic data, featuring a fully-fledged surgical simulator that automatically produces all necessary annotations for modern CAS systems. This simulator generates a wide set of annotations that surpass those available in public synthetic datasets. Additionally, it offers a more complex and realistic simulation of surgical interactions, including the dynamics between surgical instruments and deformable anatomical environments, outperforming existing approaches. To further bridge the visual gap between synthetic and real data, we propose a lightweight and flexible image-to-image translation method based on Stable Diffusion (SD) and Low-Rank Adaptation (LoRA). This method leverages a limited amount of annotated data, enables efficient training, and maintains the integrity of annotations generated by our simulator. The proposed pipeline is experimentally validated and can translate synthetic images into images with real-world characteristics, which can generalize to real-world context, thereby improving both training and CAS guidance. The code and the dataset are available at https://github.com/SanoScience/SimuScope.
PR-ENDO: Physically Based Relightable Gaussian Splatting for Endoscopy
Nov 19, 2024



Endoscopic procedures are crucial for colorectal cancer diagnosis, and three-dimensional reconstruction of the environment for real-time novel-view synthesis can significantly enhance diagnosis. We present PR-ENDO, a framework that leverages 3D Gaussian Splatting within a physically based, relightable model tailored for the complex acquisition conditions in endoscopy, such as restricted camera rotations and strong view-dependent illumination. By exploiting the connection between the camera and light source, our approach introduces a relighting model to capture the intricate interactions between light and tissue using physically based rendering and MLP. Existing methods often produce artifacts and inconsistencies under these conditions, which PR-ENDO overcomes by incorporating a specialized diffuse MLP that utilizes light angles and normal vectors, achieving stable reconstructions even with limited training camera rotations. We benchmarked our framework using a publicly available dataset and a newly introduced dataset with wider camera rotations. Our methods demonstrated superior image quality compared to baseline approaches.
Mediffusion: Joint Diffusion for Self-Explainable Semi-Supervised Classification and Medical Image Generation
Nov 12, 2024We introduce Mediffusion -- a new method for semi-supervised learning with explainable classification based on a joint diffusion model. The medical imaging domain faces unique challenges due to scarce data labelling -- insufficient for standard training, and critical nature of the applications that require high performance, confidence, and explainability of the models. In this work, we propose to tackle those challenges with a single model that combines standard classification with a diffusion-based generative task in a single shared parametrisation. By sharing representations, our model effectively learns from both labeled and unlabeled data while at the same time providing accurate explanations through counterfactual examples. In our experiments, we show that our Mediffusion achieves results comparable to recent semi-supervised methods while providing more reliable and precise explanations.
PitVis-2023 Challenge: Workflow Recognition in videos of Endoscopic Pituitary Surgery
Sep 02, 2024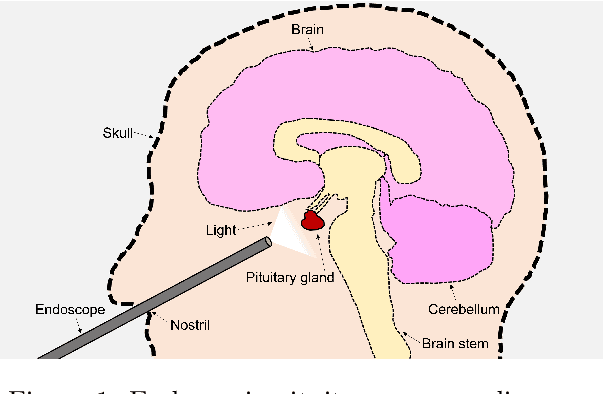

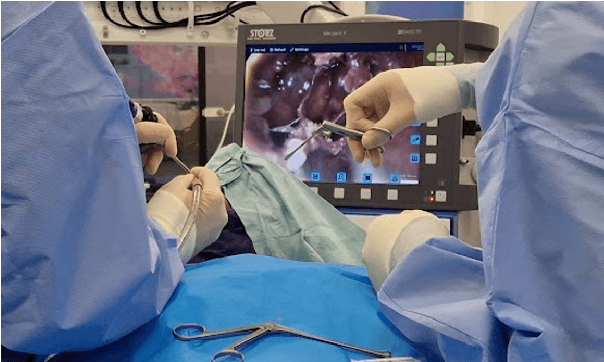
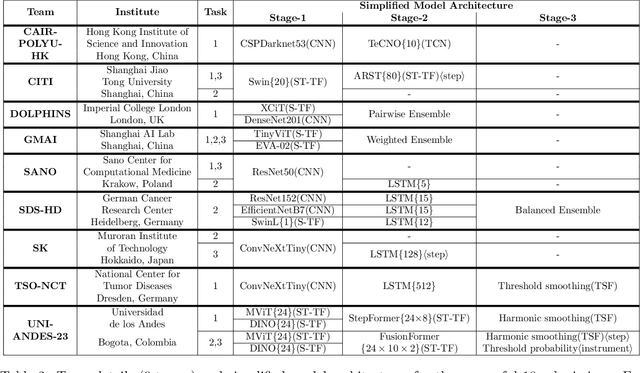
The field of computer vision applied to videos of minimally invasive surgery is ever-growing. Workflow recognition pertains to the automated recognition of various aspects of a surgery: including which surgical steps are performed; and which surgical instruments are used. This information can later be used to assist clinicians when learning the surgery; during live surgery; and when writing operation notes. The Pituitary Vision (PitVis) 2023 Challenge tasks the community to step and instrument recognition in videos of endoscopic pituitary surgery. This is a unique task when compared to other minimally invasive surgeries due to the smaller working space, which limits and distorts vision; and higher frequency of instrument and step switching, which requires more precise model predictions. Participants were provided with 25-videos, with results presented at the MICCAI-2023 conference as part of the Endoscopic Vision 2023 Challenge in Vancouver, Canada, on 08-Oct-2023. There were 18-submissions from 9-teams across 6-countries, using a variety of deep learning models. A commonality between the top performing models was incorporating spatio-temporal and multi-task methods, with greater than 50% and 10% macro-F1-score improvement over purely spacial single-task models in step and instrument recognition respectively. The PitVis-2023 Challenge therefore demonstrates state-of-the-art computer vision models in minimally invasive surgery are transferable to a new dataset, with surgery specific techniques used to enhance performance, progressing the field further. Benchmark results are provided in the paper, and the dataset is publicly available at: https://doi.org/10.5522/04/26531686.
LumiGauss: High-Fidelity Outdoor Relighting with 2D Gaussian Splatting
Aug 06, 2024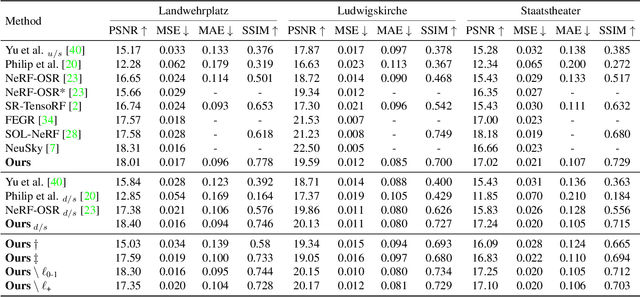
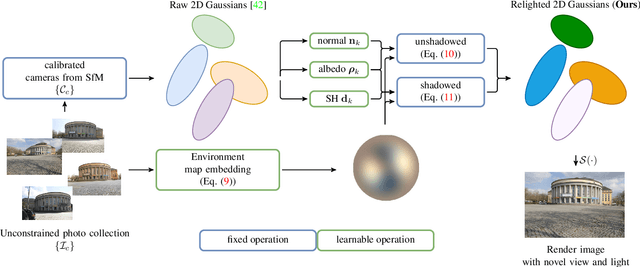

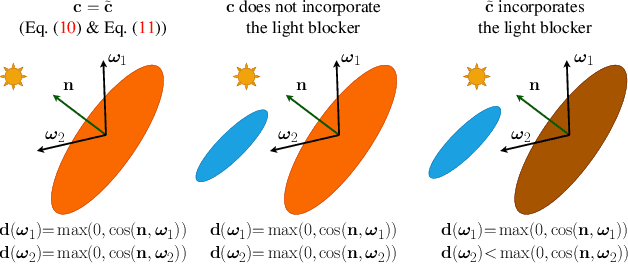
Decoupling lighting from geometry using unconstrained photo collections is notoriously challenging. Solving it would benefit many users, as creating complex 3D assets takes days of manual labor. Many previous works have attempted to address this issue, often at the expense of output fidelity, which questions the practicality of such methods. We introduce LumiGauss, a technique that tackles 3D reconstruction of scenes and environmental lighting through 2D Gaussian Splatting. Our approach yields high-quality scene reconstructions and enables realistic lighting synthesis under novel environment maps. We also propose a method for enhancing the quality of shadows, common in outdoor scenes, by exploiting spherical harmonics properties. Our approach facilitates seamless integration with game engines and enables the use of fast precomputed radiance transfer. We validate our method on the NeRF-OSR dataset, demonstrating superior performance over baseline methods. Moreover, LumiGauss can synthesize realistic images when applying novel environment maps.
D-MiSo: Editing Dynamic 3D Scenes using Multi-Gaussians Soup
May 23, 2024



Over the past years, we have observed an abundance of approaches for modeling dynamic 3D scenes using Gaussian Splatting (GS). Such solutions use GS to represent the scene's structure and the neural network to model dynamics. Such approaches allow fast rendering and extracting each element of such a dynamic scene. However, modifying such objects over time is challenging. SC-GS (Sparse Controlled Gaussian Splatting) enhanced with Deformed Control Points partially solves this issue. However, this approach necessitates selecting elements that need to be kept fixed, as well as centroids that should be adjusted throughout editing. Moreover, this task poses additional difficulties regarding the re-productivity of such editing. To address this, we propose Dynamic Multi-Gaussian Soup (D-MiSo), which allows us to model the mesh-inspired representation of dynamic GS. Additionally, we propose a strategy of linking parameterized Gaussian splats, forming a Triangle Soup with the estimated mesh. Consequently, we can separately construct new trajectories for the 3D objects composing the scene. Thus, we can make the scene's dynamic editable over time or while maintaining partial dynamics.