 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePixJail: Self-Evolving Paper-to-Pipeline Reproduction for Text-to-Image Jailbreak Evaluation
Jun 23, 2026As Text-to-Image (T2I) jailbreak techniques evolve rapidly, existing benchmarks and reproduction workflows often struggle to keep pace. More importantly, T2I jailbreak evaluation is not a single prompt-level test, but a pipeline-level problem shaped by multiple stages, including prompt transformation, image generation, safety filtering, and multimodal judging. This makes results across papers difficult to reliably reproduce and fairly compare. To bridge this gap, we propose PixJail, a self-evolving paper-to-pipeline agent framework for reproducible T2I jailbreak evaluation. Given a T2I jailbreak paper and optional reference code, PixJail rapidly constructs a paper-specific attack module and a runnable evaluation pipeline under a unified contract, while faithfully reproducing the original experimental results. PixJail further maintains a memory bank that stores paper digests, attack evolution patterns, reusable templates, failure cases, and versioned artifacts, enabling future reproduction efforts to reuse prior experience. We reproduce eleven representative T2I jailbreak methods, including both code-available and code-unavailable papers. Under their original settings, our framework accurately recovers prior results with minimal error (2.1\% average, 0\% median). We hope that PixJail can serve as a unified foundation for future T2I jailbreak reproduction and evaluation, significantly reducing manual effort.
scHelix: Asymmetric Dual-Stream Integration via Explicit Gene-Level Disentanglement
May 18, 2026A critical challenge in single-cell RNA sequencing (scRNA-seq) integration is resolving the tension between eliminating batch effects and maintaining biological fidelity. While recent evidence indicates that batch effects manifest heterogeneously across genes, most existing methods process the transcriptome uniformly, frequently resulting in over-correction and loss of subtle biological signals. To address this, we present scHelix, a dataset-adaptive framework that fundamentally changes how features are processed by explicitly partitioning genes into domain-invariant Anchors and domain-sensitive Variants at the input level. scHelix utilizes a dual-stream sparse diffusion encoder equipped with stop-gradient graph caching to efficiently learn multi-scale structural representations. The core of our approach is a novel asymmetric Align-Refine-Fuse protocol: the unstable Variant stream is first aligned to the robust topology of the Anchor stream, followed by a conservative refinement phase where the Anchor stream absorbs denoised details via bounded residual gating. This divide-and-conquer architecture prevents shortcut learning and ensures robust batch removal without compromising the integrity of biological clusters. Extensive benchmarking demonstrates that scHelix outperforms state-of-the-art methods.
MAT-Cell: A Multi-Agent Tree-Structured Reasoning Framework for Batch-Level Single-Cell Annotation
Apr 07, 2026Automated cellular reasoning faces a core dichotomy: supervised methods fall into the Reference Trap and fail to generalize to out-of-distribution cell states, while large language models (LLMs), without grounded biological priors, suffer from a Signal-to-Noise Paradox that produces spurious associations. We propose MAT-Cell, a neuro-symbolic reasoning framework that reframes single-cell analysis from black-box classification into constructive, verifiable proof generation. MAT-Cell injects symbolic constraints through adaptive Retrieval-Augmented Generation (RAG) to ground neural reasoning in biological axioms and reduce transcriptomic noise. It further employs a dialectic verification process with homogeneous rebuttal agents to audit and prune reasoning paths, forming syllogistic derivation trees that enforce logical consistency.Across large-scale and cross-species benchmarks, MAT-Cell significantly outperforms state-of-the-art (SOTA) models and maintains robust per-formance in challenging scenarios where baselinemethods severely degrade. Code is available at https://gith ub.com/jiangliu91/MAT-Cell-A-Mul ti-Agent-Tree-Structured-Reasoni ng-Framework-for-Batch-Level-Sin gle-Cell-Annotation.
The Eleventh NTIRE 2026 Efficient Super-Resolution Challenge Report
Apr 03, 2026This paper reviews the NTIRE 2026 challenge on efficient single-image super-resolution with a focus on the proposed solutions and results. The aim of this challenge is to devise a network that reduces one or several aspects, such as runtime, parameters, and FLOPs, while maintaining PSNR of around 26.90 dB on the DIV2K_LSDIR_valid dataset, and 26.99 dB on the DIV2K_LSDIR_test dataset. The challenge had 95 registered participants, and 15 teams made valid submissions. They gauge the state-of-the-art results for efficient single-image super-resolution.
UniDA3D: A Unified Domain-Adaptive Framework for Multi-View 3D Object Detection
Mar 30, 2026Camera-only 3D object detection is critical for autonomous driving, offering a cost-effective alternative to LiDAR based methods. In particular, multi-view 3D object detection has emerged as a promising direction due to its balanced trade-off between performance and cost. However, existing methods often suffer significant performance degradation under complex environmental conditions such as nighttime, fog, and rain, primarily due to their reliance on training data collected mostly in ideal conditions. To address this challenge, we propose UniDA3D, a unified domain-adaptive multi-view 3D object detector designed for robust perception under diverse adverse conditions. UniDA3D formulates nighttime, rainy, and foggy scenes as a unified multi target domain adaptation problem and leverages a novel query guided domain discrepancy mitigation (QDDM) module to align object features between source and target domains at both batch and global levels via query-centric adversarial and contrastive learning. Furthermore, we introduce a domain-adaptive teacher student training pipeline with an exponential-moving-average teacher and dynamically updated high-quality pseudo labels to enhance consistency learning and suppress background noise in unlabeled target domains. In contrast to prior approaches that require separate training for each condition, UniDA3D performs a single unified training process across multiple domains, enabling robust all-weather 3D perception. On a synthesized multi-view 3D benchmark constructed by generating nighttime, rainy, and foggy counterparts from nuScenes (nuScenes-Night, nuScenes-Rain, and nuScenes-Haze), UniDA3D consistently outperforms state of-the-art camera-only multi-view 3D detectors under extreme conditions, achieving substantial gains in mAP and NDS while maintaining real-time inference efficiency.
Geometry OR Tracker: Universal Geometric Operating Room Tracking
Feb 28, 2026In operating rooms (OR), world-scale multi-view 3D tracking supports downstream applications such as surgeon behavior recognition, where physically meaningful quantities such as distances and motion statistics must be measured in meters. However, real clinical deployments rarely satisfy the geometric prerequisites for stable multi-view fusion and tracking: camera calibration and RGB-D registration are always unreliable, leading to cross-view geometric inconsistency that produces "ghosting" during fusion and degrades 3D trajectories in a shared OR coordinate frame. To address this, we introduce Geometry OR Tracker, a two-stage pipeline that first rectifies imprecise calibration into a scaleconsistent and geometrically consistent camera setup with a single global scale via a Multi-view Metric Geometry Rectification module, and then performs Occlusion-Robust 3D Point Tracking directly in the unified OR world frame. On the MM-OR benchmark, improved geometric consistency translates into tracking gains: our rectification front-end reduces cross-view depth disagreement by more than 30$\times$ compared to raw calibration. Ablation studies further demonstrate the relationship between calibration quality and tracking accuracy, showing that improved geometric consistency yields stronger world-frame tracking.
UniSurg: A Video-Native Foundation Model for Universal Understanding of Surgical Videos
Feb 05, 2026While foundation models have advanced surgical video analysis, current approaches rely predominantly on pixel-level reconstruction objectives that waste model capacity on low-level visual details - such as smoke, specular reflections, and fluid motion - rather than semantic structures essential for surgical understanding. We present UniSurg, a video-native foundation model that shifts the learning paradigm from pixel-level reconstruction to latent motion prediction. Built on the Video Joint Embedding Predictive Architecture (V-JEPA), UniSurg introduces three key technical innovations tailored to surgical videos: 1) motion-guided latent prediction to prioritize semantically meaningful regions, 2) spatiotemporal affinity self-distillation to enforce relational consistency, and 3) feature diversity regularization to prevent representation collapse in texture-sparse surgical scenes. To enable large-scale pretraining, we curate UniSurg-15M, the largest surgical video dataset to date, comprising 3,658 hours of video from 50 sources across 13 anatomical regions. Extensive experiments across 17 benchmarks demonstrate that UniSurg significantly outperforms state-of-the-art methods on surgical workflow recognition (+14.6% F1 on EgoSurgery, +10.3% on PitVis), action triplet recognition (39.54% mAP-IVT on CholecT50), skill assessment, polyp segmentation, and depth estimation. These results establish UniSurg as a new standard for universal, motion-oriented surgical video understanding.
Anatomy-R1: Enhancing Anatomy Reasoning in Multimodal Large Language Models via Anatomical Similarity Curriculum and Group Diversity Augmentation
Dec 24, 2025Multimodal Large Language Models (MLLMs) have achieved impressive progress in natural image reasoning, yet their potential in medical imaging remains underexplored, especially in clinical anatomical surgical images. Anatomy understanding tasks demand precise understanding and clinically coherent answers, which are difficult to achieve due to the complexity of medical data and the scarcity of high-quality expert annotations. These challenges limit the effectiveness of conventional Supervised Fine-Tuning (SFT) strategies. While recent work has demonstrated that Group Relative Policy Optimization (GRPO) can enhance reasoning in MLLMs without relying on large amounts of data, we find two weaknesses that hinder GRPO's reasoning performance in anatomy recognition: 1) knowledge cannot be effectively shared between different anatomical structures, resulting in uneven information gain and preventing the model from converging, and 2) the model quickly converges to a single reasoning path, suppressing the exploration of diverse strategies. To overcome these challenges, we propose two novel methods. First, we implement a progressive learning strategy called Anatomical Similarity Curriculum Learning by controlling question difficulty via the similarity of answer choices, enabling the model to master complex problems incrementally. Second, we utilize question augmentation referred to as Group Diversity Question Augmentation to expand the model's search space for difficult queries, mitigating the tendency to produce uniform responses. Comprehensive experiments on the SGG-VQA and OmniMedVQA benchmarks show our method achieves a significant improvement across the two benchmarks, demonstrating its effectiveness in enhancing the medical reasoning capabilities of MLLMs. The code can be found in https://github.com/tomato996/Anatomy-R1
6DAttack: Backdoor Attacks in the 6DoF Pose Estimation
Dec 22, 2025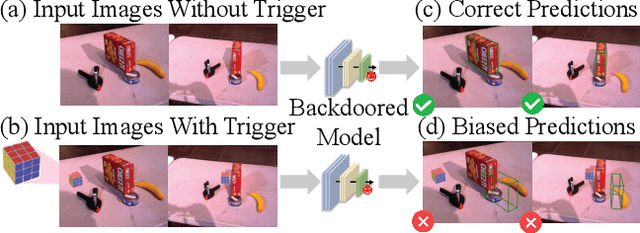
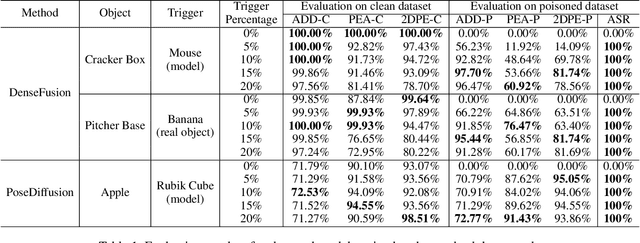
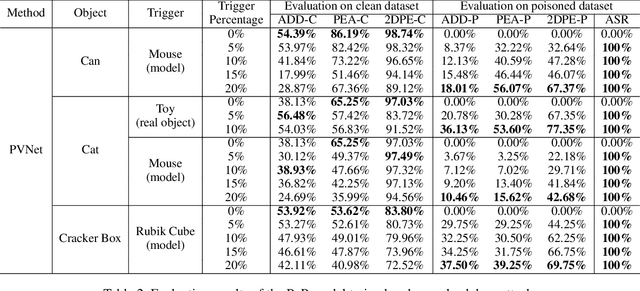
Deep learning advances have enabled accurate six-degree-of-freedom (6DoF) object pose estimation, widely used in robotics, AR/VR, and autonomous systems. However, backdoor attacks pose significant security risks. While most research focuses on 2D vision, 6DoF pose estimation remains largely unexplored. Unlike traditional backdoors that only change classes, 6DoF attacks must control continuous parameters like translation and rotation, rendering 2D methods inapplicable. We propose 6DAttack, a framework using 3D object triggers to induce controlled erroneous poses while maintaining normal behavior. Evaluations on PVNet, DenseFusion, and PoseDiffusion across LINEMOD, YCB-Video, and CO3D show high attack success rates (ASRs) without compromising clean performance. Backdoored models achieve up to 100% clean ADD accuracy and 100% ASR, with triggered samples reaching 97.70% ADD-P. Furthermore, a representative defense remains ineffective. Our findings reveal a serious, underexplored threat to 6DoF pose estimation.
Multimodal Causal-Driven Representation Learning for Generalizable Medical Image Segmentation
Aug 07, 2025Vision-Language Models (VLMs), such as CLIP, have demonstrated remarkable zero-shot capabilities in various computer vision tasks. However, their application to medical imaging remains challenging due to the high variability and complexity of medical data. Specifically, medical images often exhibit significant domain shifts caused by various confounders, including equipment differences, procedure artifacts, and imaging modes, which can lead to poor generalization when models are applied to unseen domains. To address this limitation, we propose Multimodal Causal-Driven Representation Learning (MCDRL), a novel framework that integrates causal inference with the VLM to tackle domain generalization in medical image segmentation. MCDRL is implemented in two steps: first, it leverages CLIP's cross-modal capabilities to identify candidate lesion regions and construct a confounder dictionary through text prompts, specifically designed to represent domain-specific variations; second, it trains a causal intervention network that utilizes this dictionary to identify and eliminate the influence of these domain-specific variations while preserving the anatomical structural information critical for segmentation tasks. Extensive experiments demonstrate that MCDRL consistently outperforms competing methods, yielding superior segmentation accuracy and exhibiting robust generalizability.