 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnatomy-R1: Enhancing Anatomy Reasoning in Multimodal Large Language Models via Anatomical Similarity Curriculum and Group Diversity Augmentation
Dec 24, 2025Multimodal Large Language Models (MLLMs) have achieved impressive progress in natural image reasoning, yet their potential in medical imaging remains underexplored, especially in clinical anatomical surgical images. Anatomy understanding tasks demand precise understanding and clinically coherent answers, which are difficult to achieve due to the complexity of medical data and the scarcity of high-quality expert annotations. These challenges limit the effectiveness of conventional Supervised Fine-Tuning (SFT) strategies. While recent work has demonstrated that Group Relative Policy Optimization (GRPO) can enhance reasoning in MLLMs without relying on large amounts of data, we find two weaknesses that hinder GRPO's reasoning performance in anatomy recognition: 1) knowledge cannot be effectively shared between different anatomical structures, resulting in uneven information gain and preventing the model from converging, and 2) the model quickly converges to a single reasoning path, suppressing the exploration of diverse strategies. To overcome these challenges, we propose two novel methods. First, we implement a progressive learning strategy called Anatomical Similarity Curriculum Learning by controlling question difficulty via the similarity of answer choices, enabling the model to master complex problems incrementally. Second, we utilize question augmentation referred to as Group Diversity Question Augmentation to expand the model's search space for difficult queries, mitigating the tendency to produce uniform responses. Comprehensive experiments on the SGG-VQA and OmniMedVQA benchmarks show our method achieves a significant improvement across the two benchmarks, demonstrating its effectiveness in enhancing the medical reasoning capabilities of MLLMs. The code can be found in https://github.com/tomato996/Anatomy-R1
From Data to Modeling: Fully Open-vocabulary Scene Graph Generation
May 26, 2025We present OvSGTR, a novel transformer-based framework for fully open-vocabulary scene graph generation that overcomes the limitations of traditional closed-set models. Conventional methods restrict both object and relationship recognition to a fixed vocabulary, hindering their applicability to real-world scenarios where novel concepts frequently emerge. In contrast, our approach jointly predicts objects (nodes) and their inter-relationships (edges) beyond predefined categories. OvSGTR leverages a DETR-like architecture featuring a frozen image backbone and text encoder to extract high-quality visual and semantic features, which are then fused via a transformer decoder for end-to-end scene graph prediction. To enrich the model's understanding of complex visual relations, we propose a relation-aware pre-training strategy that synthesizes scene graph annotations in a weakly supervised manner. Specifically, we investigate three pipelines--scene parser-based, LLM-based, and multimodal LLM-based--to generate transferable supervision signals with minimal manual annotation. Furthermore, we address the common issue of catastrophic forgetting in open-vocabulary settings by incorporating a visual-concept retention mechanism coupled with a knowledge distillation strategy, ensuring that the model retains rich semantic cues during fine-tuning. Extensive experiments on the VG150 benchmark demonstrate that OvSGTR achieves state-of-the-art performance across multiple settings, including closed-set, open-vocabulary object detection-based, relation-based, and fully open-vocabulary scenarios. Our results highlight the promise of large-scale relation-aware pre-training and transformer architectures for advancing scene graph generation towards more generalized and reliable visual understanding.
Compile Scene Graphs with Reinforcement Learning
Apr 18, 2025Next token prediction is the fundamental principle for training large language models (LLMs), and reinforcement learning (RL) further enhances their reasoning performance. As an effective way to model language, image, video, and other modalities, the use of LLMs for end-to-end extraction of structured visual representations, such as scene graphs, remains underexplored. It requires the model to accurately produce a set of objects and relationship triplets, rather than generating text token by token. To achieve this, we introduce R1-SGG, a multimodal LLM (M-LLM) initially trained via supervised fine-tuning (SFT) on the scene graph dataset and subsequently refined using reinforcement learning to enhance its ability to generate scene graphs in an end-to-end manner. The SFT follows a conventional prompt-response paradigm, while RL requires the design of effective reward signals. Given the structured nature of scene graphs, we design a graph-centric reward function that integrates node-level rewards, edge-level rewards, and a format consistency reward. Our experiments demonstrate that rule-based RL substantially enhances model performance in the SGG task, achieving a zero failure rate--unlike supervised fine-tuning (SFT), which struggles to generalize effectively. Our code is available at https://github.com/gpt4vision/R1-SGG.
What Makes a Scene ? Scene Graph-based Evaluation and Feedback for Controllable Generation
Nov 23, 2024



While text-to-image generation has been extensively studied, generating images from scene graphs remains relatively underexplored, primarily due to challenges in accurately modeling spatial relationships and object interactions. To fill this gap, we introduce Scene-Bench, a comprehensive benchmark designed to evaluate and enhance the factual consistency in generating natural scenes. Scene-Bench comprises MegaSG, a large-scale dataset of one million images annotated with scene graphs, facilitating the training and fair comparison of models across diverse and complex scenes. Additionally, we propose SGScore, a novel evaluation metric that leverages chain-of-thought reasoning capabilities of multimodal large language models (LLMs) to assess both object presence and relationship accuracy, offering a more effective measure of factual consistency than traditional metrics like FID and CLIPScore. Building upon this evaluation framework, we develop a scene graph feedback pipeline that iteratively refines generated images by identifying and correcting discrepancies between the scene graph and the image. Extensive experiments demonstrate that Scene-Bench provides a more comprehensive and effective evaluation framework compared to existing benchmarks, particularly for complex scene generation. Furthermore, our feedback strategy significantly enhances the factual consistency of image generation models, advancing the field of controllable image generation.
GPT4SGG: Synthesizing Scene Graphs from Holistic and Region-specific Narratives
Dec 07, 2023Learning scene graphs from natural language descriptions has proven to be a cheap and promising scheme for Scene Graph Generation (SGG). However, such unstructured caption data and its processing are troubling the learning an acurrate and complete scene graph. This dilema can be summarized as three points. First, traditional language parsers often fail to extract meaningful relationship triplets from caption data. Second, grounding unlocalized objects in parsed triplets will meet ambiguity in visual-language alignment. Last, caption data typically are sparse and exhibit bias to partial observations of image content. These three issues make it hard for the model to generate comprehensive and accurate scene graphs. To fill this gap, we propose a simple yet effective framework, GPT4SGG, to synthesize scene graphs from holistic and region-specific narratives. The framework discards traditional language parser, and localize objects before obtaining relationship triplets. To obtain relationship triplets, holistic and dense region-specific narratives are generated from the image. With such textual representation of image data and a task-specific prompt, an LLM, particularly GPT-4, directly synthesizes a scene graph as "pseudo labels". Experimental results showcase GPT4SGG significantly improves the performance of SGG models trained on image-caption data. We believe this pioneering work can motivate further research into mining the visual reasoning capabilities of LLMs.
Expanding Scene Graph Boundaries: Fully Open-vocabulary Scene Graph Generation via Visual-Concept Alignment and Retention
Nov 18, 2023Scene Graph Generation (SGG) offers a structured representation critical in many computer vision applications. Traditional SGG approaches, however, are limited by a closed-set assumption, restricting their ability to recognize only predefined object and relation categories. To overcome this, we categorize SGG scenarios into four distinct settings based on the node and edge: Closed-set SGG, Open Vocabulary (object) Detection-based SGG (OvD-SGG), Open Vocabulary Relation-based SGG (OvR-SGG), and Open Vocabulary Detection + Relation-based SGG (OvD+R-SGG). While object-centric open vocabulary SGG has been studied recently, the more challenging problem of relation-involved open-vocabulary SGG remains relatively unexplored. To fill this gap, we propose a unified framework named OvSGTR towards fully open vocabulary SGG from a holistic view. The proposed framework is an end-toend transformer architecture, which learns a visual-concept alignment for both nodes and edges, enabling the model to recognize unseen categories. For the more challenging settings of relation-involved open vocabulary SGG, the proposed approach integrates relation-aware pre-training utilizing image-caption data and retains visual-concept alignment through knowledge distillation. Comprehensive experimental results on the Visual Genome benchmark demonstrate the effectiveness and superiority of the proposed framework.
DPANet: Depth Potentiality-Aware Gated Attention Network for RGB-D Salient Object Detection
Apr 09, 2020
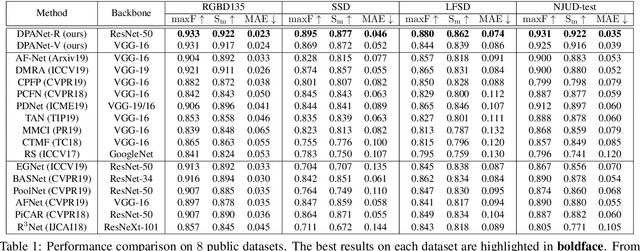

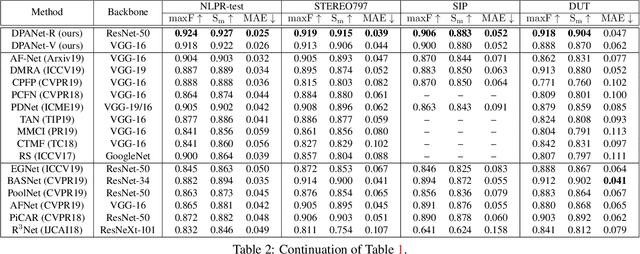
There are two main issues in RGB-D salient object detection: (1) how to effectively integrate the complementarity from the cross-modal RGB-D data; (2) how to prevent the contamination effect from the unreliable depth map. In fact, these two problems are linked and intertwined, but the previous methods tend to focus only on the first problem and ignore the consideration of depth map quality, which may yield the model fall into the sub-optimal state. In this paper, we address these two issues in a holistic model synergistically, and propose a novel network named DPANet to explicitly model the potentiality of the depth map and effectively integrate the cross-modal complementarity. By introducing the depth potentiality perception, the network can perceive the potentiality of depth information in a learning-based manner, and guide the fusion process of two modal data to prevent the contamination occurred. The gated multi-modality attention module in the fusion process exploits the attention mechanism with a gate controller to capture long-range dependencies from a cross-modal perspective. Experimental results compared with 15 state-of-the-art methods on 8 datasets demonstrate the validity of the proposed approach both quantitatively and qualitatively.
Global Context-Aware Progressive Aggregation Network for Salient Object Detection
Mar 02, 2020

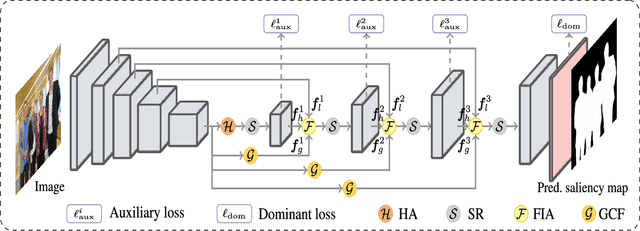

Deep convolutional neural networks have achieved competitive performance in salient object detection, in which how to learn effective and comprehensive features plays a critical role. Most of the previous works mainly adopted multiple level feature integration yet ignored the gap between different features. Besides, there also exists a dilution process of high-level features as they passed on the top-down pathway. To remedy these issues, we propose a novel network named GCPANet to effectively integrate low-level appearance features, high-level semantic features, and global context features through some progressive context-aware Feature Interweaved Aggregation (FIA) modules and generate the saliency map in a supervised way. Moreover, a Head Attention (HA) module is used to reduce information redundancy and enhance the top layers features by leveraging the spatial and channel-wise attention, and the Self Refinement (SR) module is utilized to further refine and heighten the input features. Furthermore, we design the Global Context Flow (GCF) module to generate the global context information at different stages, which aims to learn the relationship among different salient regions and alleviate the dilution effect of high-level features. Experimental results on six benchmark datasets demonstrate that the proposed approach outperforms the state-of-the-art methods both quantitatively and qualitatively.