 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTCAP: Tri-Component Attention Profiling for Unsupervised Backdoor Detection in MLLM Fine-Tuning
Jan 29, 2026Fine-Tuning-as-a-Service (FTaaS) facilitates the customization of Multimodal Large Language Models (MLLMs) but introduces critical backdoor risks via poisoned data. Existing defenses either rely on supervised signals or fail to generalize across diverse trigger types and modalities. In this work, we uncover a universal backdoor fingerprint-attention allocation divergence-where poisoned samples disrupt the balanced attention distribution across three functional components: system instructions, vision inputs, and user textual queries, regardless of trigger morphology. Motivated by this insight, we propose Tri-Component Attention Profiling (TCAP), an unsupervised defense framework to filter backdoor samples. TCAP decomposes cross-modal attention maps into the three components, identifies trigger-responsive attention heads via Gaussian Mixture Model (GMM) statistical profiling, and isolates poisoned samples through EM-based vote aggregation. Extensive experiments across diverse MLLM architectures and attack methods demonstrate that TCAP achieves consistently strong performance, establishing it as a robust and practical backdoor defense in MLLMs.
OSDEnhancer: Taming Real-World Space-Time Video Super-Resolution with One-Step Diffusion
Jan 28, 2026Diffusion models (DMs) have demonstrated exceptional success in video super-resolution (VSR), showcasing a powerful capacity for generating fine-grained details. However, their potential for space-time video super-resolution (STVSR), which necessitates not only recovering realistic visual content from low-resolution to high-resolution but also improving the frame rate with coherent temporal dynamics, remains largely underexplored. Moreover, existing STVSR methods predominantly address spatiotemporal upsampling under simplified degradation assumptions, which often struggle in real-world scenarios with complex unknown degradations. Such a high demand for reconstruction fidelity and temporal consistency makes the development of a robust STVSR framework particularly non-trivial. To address these challenges, we propose OSDEnhancer, a novel framework that, to the best of our knowledge, represents the first method to achieve real-world STVSR through an efficient one-step diffusion process. OSDEnhancer initializes essential spatiotemporal structures through a linear pre-interpolation strategy and pivots on training temporal refinement and spatial enhancement mixture of experts (TR-SE MoE), which allows distinct expert pathways to progressively learn robust, specialized representations for temporal coherence and spatial detail, further collaboratively reinforcing each other during inference. A bidirectional deformable variational autoencoder (VAE) decoder is further introduced to perform recurrent spatiotemporal aggregation and propagation, enhancing cross-frame reconstruction fidelity. Experiments demonstrate that the proposed method achieves state-of-the-art performance while maintaining superior generalization capability in real-world scenarios.
Towards Ancient Plant Seed Classification: A Benchmark Dataset and Baseline Model
Dec 20, 2025Understanding the dietary preferences of ancient societies and their evolution across periods and regions is crucial for revealing human-environment interactions. Seeds, as important archaeological artifacts, represent a fundamental subject of archaeobotanical research. However, traditional studies rely heavily on expert knowledge, which is often time-consuming and inefficient. Intelligent analysis methods have made progress in various fields of archaeology, but there remains a research gap in data and methods in archaeobotany, especially in the classification task of ancient plant seeds. To address this, we construct the first Ancient Plant Seed Image Classification (APS) dataset. It contains 8,340 images from 17 genus- or species-level seed categories excavated from 18 archaeological sites across China. In addition, we design a framework specifically for the ancient plant seed classification task (APSNet), which introduces the scale feature (size) of seeds based on learning fine-grained information to guide the network in discovering key "evidence" for sufficient classification. Specifically, we design a Size Perception and Embedding (SPE) module in the encoder part to explicitly extract size information for the purpose of complementing fine-grained information. We propose an Asynchronous Decoupled Decoding (ADD) architecture based on traditional progressive learning to decode features from both channel and spatial perspectives, enabling efficient learning of discriminative features. In both quantitative and qualitative analyses, our approach surpasses existing state-of-the-art image classification methods, achieving an accuracy of 90.5%. This demonstrates that our work provides an effective tool for large-scale, systematic archaeological research.
SAM-DAQ: Segment Anything Model with Depth-guided Adaptive Queries for RGB-D Video Salient Object Detection
Nov 13, 2025
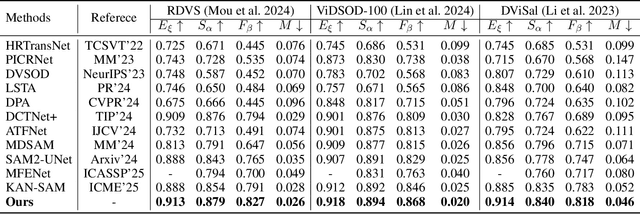
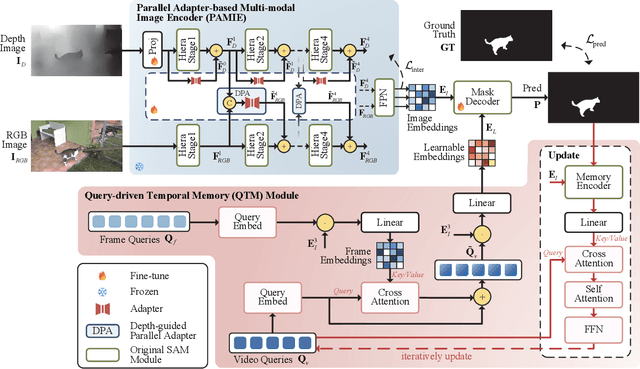
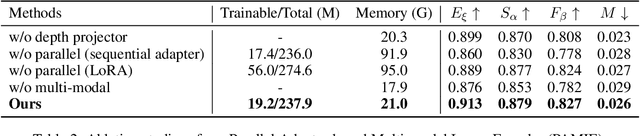
Recently segment anything model (SAM) has attracted widespread concerns, and it is often treated as a vision foundation model for universal segmentation. Some researchers have attempted to directly apply the foundation model to the RGB-D video salient object detection (RGB-D VSOD) task, which often encounters three challenges, including the dependence on manual prompts, the high memory consumption of sequential adapters, and the computational burden of memory attention. To address the limitations, we propose a novel method, namely Segment Anything Model with Depth-guided Adaptive Queries (SAM-DAQ), which adapts SAM2 to pop-out salient objects from videos by seamlessly integrating depth and temporal cues within a unified framework. Firstly, we deploy a parallel adapter-based multi-modal image encoder (PAMIE), which incorporates several depth-guided parallel adapters (DPAs) in a skip-connection way. Remarkably, we fine-tune the frozen SAM encoder under prompt-free conditions, where the DPA utilizes depth cues to facilitate the fusion of multi-modal features. Secondly, we deploy a query-driven temporal memory (QTM) module, which unifies the memory bank and prompt embeddings into a learnable pipeline. Concretely, by leveraging both frame-level queries and video-level queries simultaneously, the QTM module can not only selectively extract temporal consistency features but also iteratively update the temporal representations of the queries. Extensive experiments are conducted on three RGB-D VSOD datasets, and the results show that the proposed SAM-DAQ consistently outperforms state-of-the-art methods in terms of all evaluation metrics.
Divide-and-Conquer Decoupled Network for Cross-Domain Few-Shot Segmentation
Nov 11, 2025Cross-domain few-shot segmentation (CD-FSS) aims to tackle the dual challenge of recognizing novel classes and adapting to unseen domains with limited annotations. However, encoder features often entangle domain-relevant and category-relevant information, limiting both generalization and rapid adaptation to new domains. To address this issue, we propose a Divide-and-Conquer Decoupled Network (DCDNet). In the training stage, to tackle feature entanglement that impedes cross-domain generalization and rapid adaptation, we propose the Adversarial-Contrastive Feature Decomposition (ACFD) module. It decouples backbone features into category-relevant private and domain-relevant shared representations via contrastive learning and adversarial learning. Then, to mitigate the potential degradation caused by the disentanglement, the Matrix-Guided Dynamic Fusion (MGDF) module adaptively integrates base, shared, and private features under spatial guidance, maintaining structural coherence. In addition, in the fine-tuning stage, to enhanced model generalization, the Cross-Adaptive Modulation (CAM) module is placed before the MGDF, where shared features guide private features via modulation ensuring effective integration of domain-relevant information. Extensive experiments on four challenging datasets show that DCDNet outperforms existing CD-FSS methods, setting a new state-of-the-art for cross-domain generalization and few-shot adaptation.
Empowering DINO Representations for Underwater Instance Segmentation via Aligner and Prompter
Nov 11, 2025Underwater instance segmentation (UIS), integrating pixel-level understanding and instance-level discrimination, is a pivotal technology in marine resource exploration and ecological protection. In recent years, large-scale pretrained visual foundation models, exemplified by DINO, have advanced rapidly and demonstrated remarkable performance on complex downstream tasks. In this paper, we demonstrate that DINO can serve as an effective feature learner for UIS, and we introduce DiveSeg, a novel framework built upon two insightful components: (1) The AquaStyle Aligner, designed to embed underwater color style features into the DINO fine-tuning process, facilitating better adaptation to the underwater domain. (2) The ObjectPrior Prompter, which incorporates binary segmentation-based prompts to deliver object-level priors, provides essential guidance for instance segmentation task that requires both object- and instance-level reasoning. We conduct thorough experiments on the popular UIIS and USIS10K datasets, and the results show that DiveSeg achieves the state-of-the-art performance. Code: https://github.com/ettof/Diveseg.
Semantic Concentration for Self-Supervised Dense Representations Learning
Sep 11, 2025Recent advances in image-level self-supervised learning (SSL) have made significant progress, yet learning dense representations for patches remains challenging. Mainstream methods encounter an over-dispersion phenomenon that patches from the same instance/category scatter, harming downstream performance on dense tasks. This work reveals that image-level SSL avoids over-dispersion by involving implicit semantic concentration. Specifically, the non-strict spatial alignment ensures intra-instance consistency, while shared patterns, i.e., similar parts of within-class instances in the input space, ensure inter-image consistency. Unfortunately, these approaches are infeasible for dense SSL due to their spatial sensitivity and complicated scene-centric data. These observations motivate us to explore explicit semantic concentration for dense SSL. First, to break the strict spatial alignment, we propose to distill the patch correspondences. Facing noisy and imbalanced pseudo labels, we propose a noise-tolerant ranking loss. The core idea is extending the Average Precision (AP) loss to continuous targets, such that its decision-agnostic and adaptive focusing properties prevent the student model from being misled. Second, to discriminate the shared patterns from complicated scenes, we propose the object-aware filter to map the output space to an object-based space. Specifically, patches are represented by learnable prototypes of objects via cross-attention. Last but not least, empirical studies across various tasks soundly support the effectiveness of our method. Code is available in https://github.com/KID-7391/CoTAP.
Proto-FG3D: Prototype-based Interpretable Fine-Grained 3D Shape Classification
May 23, 2025Deep learning-based multi-view coarse-grained 3D shape classification has achieved remarkable success over the past decade, leveraging the powerful feature learning capabilities of CNN-based and ViT-based backbones. However, as a challenging research area critical for detailed shape understanding, fine-grained 3D classification remains understudied due to the limited discriminative information captured during multi-view feature aggregation, particularly for subtle inter-class variations, class imbalance, and inherent interpretability limitations of parametric model. To address these problems, we propose the first prototype-based framework named Proto-FG3D for fine-grained 3D shape classification, achieving a paradigm shift from parametric softmax to non-parametric prototype learning. Firstly, Proto-FG3D establishes joint multi-view and multi-category representation learning via Prototype Association. Secondly, prototypes are refined via Online Clustering, improving both the robustness of multi-view feature allocation and inter-subclass balance. Finally, prototype-guided supervised learning is established to enhance fine-grained discrimination via prototype-view correlation analysis and enables ad-hoc interpretability through transparent case-based reasoning. Experiments on FG3D and ModelNet40 show Proto-FG3D surpasses state-of-the-art methods in accuracy, transparent predictions, and ad-hoc interpretability with visualizations, challenging conventional fine-grained 3D recognition approaches.
UWSAM: Segment Anything Model Guided Underwater Instance Segmentation and A Large-scale Benchmark Dataset
May 21, 2025With recent breakthroughs in large-scale modeling, the Segment Anything Model (SAM) has demonstrated significant potential in a variety of visual applications. However, due to the lack of underwater domain expertise, SAM and its variants face performance limitations in end-to-end underwater instance segmentation tasks, while their higher computational requirements further hinder their application in underwater scenarios. To address this challenge, we propose a large-scale underwater instance segmentation dataset, UIIS10K, which includes 10,048 images with pixel-level annotations for 10 categories. Then, we introduce UWSAM, an efficient model designed for automatic and accurate segmentation of underwater instances. UWSAM efficiently distills knowledge from the SAM ViT-Huge image encoder into the smaller ViT-Small image encoder via the Mask GAT-based Underwater Knowledge Distillation (MG-UKD) method for effective visual representation learning. Furthermore, we design an End-to-end Underwater Prompt Generator (EUPG) for UWSAM, which automatically generates underwater prompts instead of explicitly providing foreground points or boxes as prompts, thus enabling the network to locate underwater instances accurately for efficient segmentation. Comprehensive experimental results show that our model is effective, achieving significant performance improvements over state-of-the-art methods on multiple underwater instance datasets. Datasets and codes are available at https://github.com/LiamLian0727/UIIS10K.
SEFE: Superficial and Essential Forgetting Eliminator for Multimodal Continual Instruction Tuning
May 05, 2025Multimodal Continual Instruction Tuning (MCIT) aims to enable Multimodal Large Language Models (MLLMs) to incrementally learn new tasks without catastrophic forgetting. In this paper, we explore forgetting in this context, categorizing it into superficial forgetting and essential forgetting. Superficial forgetting refers to cases where the model's knowledge may not be genuinely lost, but its responses to previous tasks deviate from expected formats due to the influence of subsequent tasks' answer styles, making the results unusable. By contrast, essential forgetting refers to situations where the model provides correctly formatted but factually inaccurate answers, indicating a true loss of knowledge. Assessing essential forgetting necessitates addressing superficial forgetting first, as severe superficial forgetting can obscure the model's knowledge state. Hence, we first introduce the Answer Style Diversification (ASD) paradigm, which defines a standardized process for transforming data styles across different tasks, unifying their training sets into similarly diversified styles to prevent superficial forgetting caused by style shifts. Building on this, we propose RegLoRA to mitigate essential forgetting. RegLoRA stabilizes key parameters where prior knowledge is primarily stored by applying regularization, enabling the model to retain existing competencies. Experimental results demonstrate that our overall method, SEFE, achieves state-of-the-art performance.