 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Efficient Agents: Memory, Tool learning, and Planning
Jan 20, 2026Recent years have witnessed increasing interest in extending large language models into agentic systems. While the effectiveness of agents has continued to improve, efficiency, which is crucial for real-world deployment, has often been overlooked. This paper therefore investigates efficiency from three core components of agents: memory, tool learning, and planning, considering costs such as latency, tokens, steps, etc. Aimed at conducting comprehensive research addressing the efficiency of the agentic system itself, we review a broad range of recent approaches that differ in implementation yet frequently converge on shared high-level principles including but not limited to bounding context via compression and management, designing reinforcement learning rewards to minimize tool invocation, and employing controlled search mechanisms to enhance efficiency, which we discuss in detail. Accordingly, we characterize efficiency in two complementary ways: comparing effectiveness under a fixed cost budget, and comparing cost at a comparable level of effectiveness. This trade-off can also be viewed through the Pareto frontier between effectiveness and cost. From this perspective, we also examine efficiency oriented benchmarks by summarizing evaluation protocols for these components and consolidating commonly reported efficiency metrics from both benchmark and methodological studies. Moreover, we discuss the key challenges and future directions, with the goal of providing promising insights.
SimpleVLA-RL: Scaling VLA Training via Reinforcement Learning
Sep 11, 2025Vision-Language-Action (VLA) models have recently emerged as a powerful paradigm for robotic manipulation. Despite substantial progress enabled by large-scale pretraining and supervised fine-tuning (SFT), these models face two fundamental challenges: (i) the scarcity and high cost of large-scale human-operated robotic trajectories required for SFT scaling, and (ii) limited generalization to tasks involving distribution shift. Recent breakthroughs in Large Reasoning Models (LRMs) demonstrate that reinforcement learning (RL) can dramatically enhance step-by-step reasoning capabilities, raising a natural question: Can RL similarly improve the long-horizon step-by-step action planning of VLA? In this work, we introduce SimpleVLA-RL, an efficient RL framework tailored for VLA models. Building upon veRL, we introduce VLA-specific trajectory sampling, scalable parallelization, multi-environment rendering, and optimized loss computation. When applied to OpenVLA-OFT, SimpleVLA-RL achieves SoTA performance on LIBERO and even outperforms $\pi_0$ on RoboTwin 1.0\&2.0 with the exploration-enhancing strategies we introduce. SimpleVLA-RL not only reduces dependence on large-scale data and enables robust generalization, but also remarkably surpasses SFT in real-world tasks. Moreover, we identify a novel phenomenon ``pushcut'' during RL training, wherein the policy discovers previously unseen patterns beyond those seen in the previous training process. Github: https://github.com/PRIME-RL/SimpleVLA-RL
A Survey of Reinforcement Learning for Large Reasoning Models
Sep 10, 2025In this paper, we survey recent advances in Reinforcement Learning (RL) for reasoning with Large Language Models (LLMs). RL has achieved remarkable success in advancing the frontier of LLM capabilities, particularly in addressing complex logical tasks such as mathematics and coding. As a result, RL has emerged as a foundational methodology for transforming LLMs into LRMs. With the rapid progress of the field, further scaling of RL for LRMs now faces foundational challenges not only in computational resources but also in algorithm design, training data, and infrastructure. To this end, it is timely to revisit the development of this domain, reassess its trajectory, and explore strategies to enhance the scalability of RL toward Artificial SuperIntelligence (ASI). In particular, we examine research applying RL to LLMs and LRMs for reasoning abilities, especially since the release of DeepSeek-R1, including foundational components, core problems, training resources, and downstream applications, to identify future opportunities and directions for this rapidly evolving area. We hope this review will promote future research on RL for broader reasoning models. Github: https://github.com/TsinghuaC3I/Awesome-RL-for-LRMs
The Entropy Mechanism of Reinforcement Learning for Reasoning Language Models
May 28, 2025



This paper aims to overcome a major obstacle in scaling RL for reasoning with LLMs, namely the collapse of policy entropy. Such phenomenon is consistently observed across vast RL runs without entropy intervention, where the policy entropy dropped sharply at the early training stage, this diminished exploratory ability is always accompanied with the saturation of policy performance. In practice, we establish a transformation equation R=-a*e^H+b between entropy H and downstream performance R. This empirical law strongly indicates that, the policy performance is traded from policy entropy, thus bottlenecked by its exhaustion, and the ceiling is fully predictable H=0, R=-a+b. Our finding necessitates entropy management for continuous exploration toward scaling compute for RL. To this end, we investigate entropy dynamics both theoretically and empirically. Our derivation highlights that, the change in policy entropy is driven by the covariance between action probability and the change in logits, which is proportional to its advantage when using Policy Gradient-like algorithms. Empirical study shows that, the values of covariance term and entropy differences matched exactly, supporting the theoretical conclusion. Moreover, the covariance term stays mostly positive throughout training, further explaining why policy entropy would decrease monotonically. Through understanding the mechanism behind entropy dynamics, we motivate to control entropy by restricting the update of high-covariance tokens. Specifically, we propose two simple yet effective techniques, namely Clip-Cov and KL-Cov, which clip and apply KL penalty to tokens with high covariances respectively. Experiments show that these methods encourage exploration, thus helping policy escape entropy collapse and achieve better downstream performance.
Technologies on Effectiveness and Efficiency: A Survey of State Spaces Models
Mar 14, 2025



State Space Models (SSMs) have emerged as a promising alternative to the popular transformer-based models and have been increasingly gaining attention. Compared to transformers, SSMs excel at tasks with sequential data or longer contexts, demonstrating comparable performances with significant efficiency gains. In this survey, we provide a coherent and systematic overview for SSMs, including their theoretical motivations, mathematical formulations, comparison with existing model classes, and various applications. We divide the SSM series into three main sections, providing a detailed introduction to the original SSM, the structured SSM represented by S4, and the selective SSM typified by Mamba. We put an emphasis on technicality, and highlight the various key techniques introduced to address the effectiveness and efficiency of SSMs. We hope this manuscript serves as an introduction for researchers to explore the theoretical foundations of SSMs.
Process Reinforcement through Implicit Rewards
Feb 03, 2025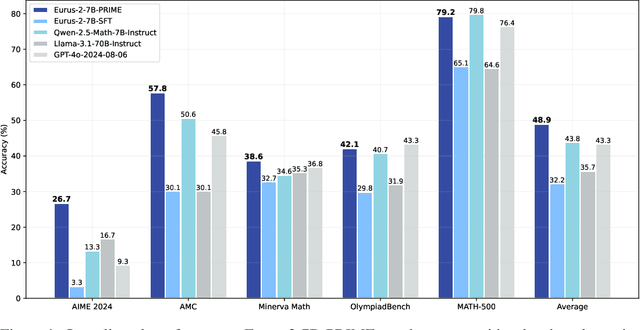

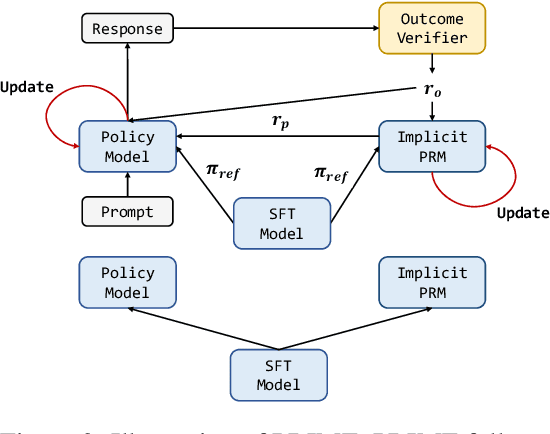
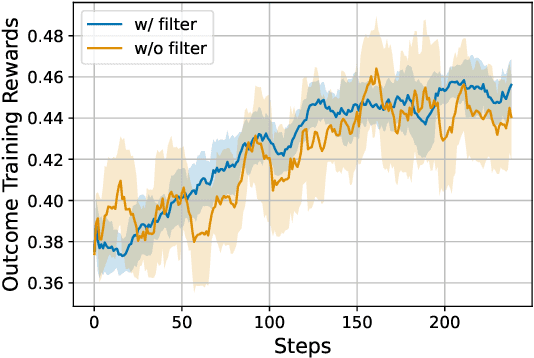
Dense process rewards have proven a more effective alternative to the sparse outcome-level rewards in the inference-time scaling of large language models (LLMs), particularly in tasks requiring complex multi-step reasoning. While dense rewards also offer an appealing choice for the reinforcement learning (RL) of LLMs since their fine-grained rewards have the potential to address some inherent issues of outcome rewards, such as training efficiency and credit assignment, this potential remains largely unrealized. This can be primarily attributed to the challenges of training process reward models (PRMs) online, where collecting high-quality process labels is prohibitively expensive, making them particularly vulnerable to reward hacking. To address these challenges, we propose PRIME (Process Reinforcement through IMplicit rEwards), which enables online PRM updates using only policy rollouts and outcome labels through implict process rewards. PRIME combines well with various advantage functions and forgoes the dedicated reward model training phrase that existing approaches require, substantially reducing the development overhead. We demonstrate PRIME's effectiveness on competitional math and coding. Starting from Qwen2.5-Math-7B-Base, PRIME achieves a 15.1% average improvement across several key reasoning benchmarks over the SFT model. Notably, our resulting model, Eurus-2-7B-PRIME, surpasses Qwen2.5-Math-7B-Instruct on seven reasoning benchmarks with 10% of its training data.
Fourier Position Embedding: Enhancing Attention's Periodic Extension for Length Generalization
Dec 23, 2024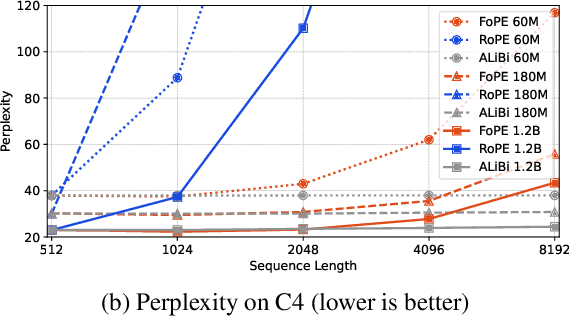
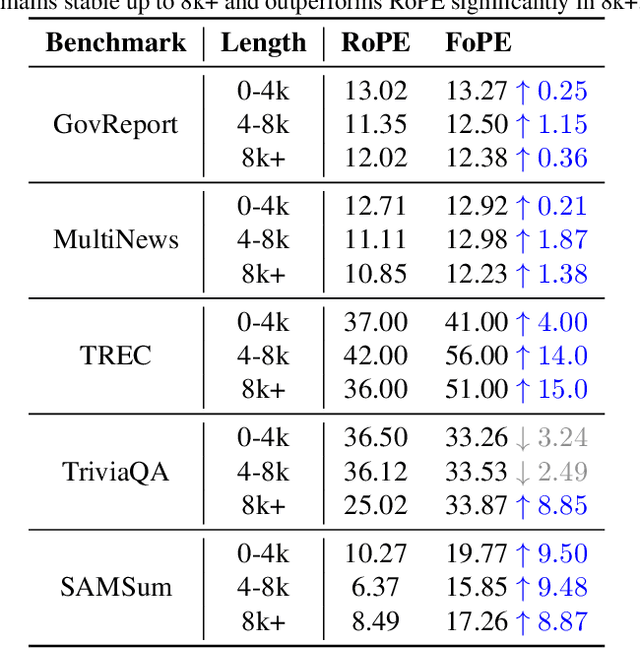
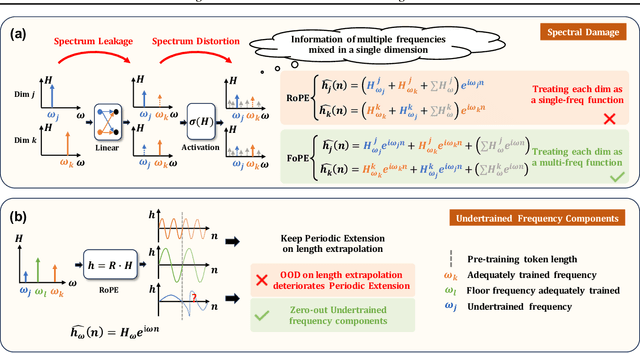
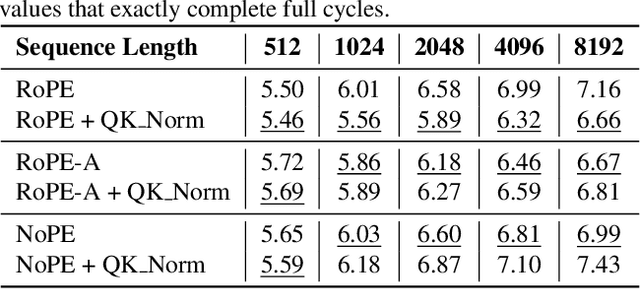
Extending the context length of Language Models (LMs) by improving Rotary Position Embedding (RoPE) has become a trend. While existing works mainly address RoPE's limitations within attention mechanism, this paper provides an analysis across nearly all parts of LMs, uncovering their adverse effects on length generalization for RoPE-based attention. Using Discrete Signal Processing theory, we show that RoPE enables periodic attention by implicitly achieving Non-Uniform Discrete Fourier Transform. However, this periodicity is undermined by the spectral damage caused by: 1) linear layers and activation functions outside of attention; 2) insufficiently trained frequency components brought by time-domain truncation. Building on our observations, we propose Fourier Position Embedding (FoPE), which enhances attention's frequency-domain properties to improve both its periodic extension and length generalization. FoPE constructs Fourier Series and zero-outs the destructive frequency components, increasing model robustness against the spectrum damage. Experiments across various model scales show that, within varying context windows, FoPE can maintain a more stable perplexity and a more consistent accuracy in a needle-in-haystack task compared to RoPE and ALiBi. Several analyses and ablations bring further support to our method and theoretical modeling.
Preference-Oriented Supervised Fine-Tuning: Favoring Target Model Over Aligned Large Language Models
Dec 17, 2024



Alignment, endowing a pre-trained Large language model (LLM) with the ability to follow instructions, is crucial for its real-world applications. Conventional supervised fine-tuning (SFT) methods formalize it as causal language modeling typically with a cross-entropy objective, requiring a large amount of high-quality instruction-response pairs. However, the quality of widely used SFT datasets can not be guaranteed due to the high cost and intensive labor for the creation and maintenance in practice. To overcome the limitations associated with the quality of SFT datasets, we introduce a novel \textbf{p}reference-\textbf{o}riented supervised \textbf{f}ine-\textbf{t}uning approach, namely PoFT. The intuition is to boost SFT by imposing a particular preference: \textit{favoring the target model over aligned LLMs on the same SFT data.} This preference encourages the target model to predict a higher likelihood than that predicted by the aligned LLMs, incorporating assessment information on data quality (i.e., predicted likelihood by the aligned LLMs) into the training process. Extensive experiments are conducted, and the results validate the effectiveness of the proposed method. PoFT achieves stable and consistent improvements over the SFT baselines across different training datasets and base models. Moreover, we prove that PoFT can be integrated with existing SFT data filtering methods to achieve better performance, and further improved by following preference optimization procedures, such as DPO.
3D Mesh Editing using Masked LRMs
Dec 11, 2024We present a novel approach to mesh shape editing, building on recent progress in 3D reconstruction from multi-view images. We formulate shape editing as a conditional reconstruction problem, where the model must reconstruct the input shape with the exception of a specified 3D region, in which the geometry should be generated from the conditional signal. To this end, we train a conditional Large Reconstruction Model (LRM) for masked reconstruction, using multi-view consistent masks rendered from a randomly generated 3D occlusion, and using one clean viewpoint as the conditional signal. During inference, we manually define a 3D region to edit and provide an edited image from a canonical viewpoint to fill in that region. We demonstrate that, in just a single forward pass, our method not only preserves the input geometry in the unmasked region through reconstruction capabilities on par with SoTA, but is also expressive enough to perform a variety of mesh edits from a single image guidance that past works struggle with, while being 10x faster than the top-performing competing prior work.
Make-A-Texture: Fast Shape-Aware Texture Generation in 3 Seconds
Dec 10, 2024



We present Make-A-Texture, a new framework that efficiently synthesizes high-resolution texture maps from textual prompts for given 3D geometries. Our approach progressively generates textures that are consistent across multiple viewpoints with a depth-aware inpainting diffusion model, in an optimized sequence of viewpoints determined by an automatic view selection algorithm. A significant feature of our method is its remarkable efficiency, achieving a full texture generation within an end-to-end runtime of just 3.07 seconds on a single NVIDIA H100 GPU, significantly outperforming existing methods. Such an acceleration is achieved by optimizations in the diffusion model and a specialized backprojection method. Moreover, our method reduces the artifacts in the backprojection phase, by selectively masking out non-frontal faces, and internal faces of open-surfaced objects. Experimental results demonstrate that Make-A-Texture matches or exceeds the quality of other state-of-the-art methods. Our work significantly improves the applicability and practicality of texture generation models for real-world 3D content creation, including interactive creation and text-guided texture editing.