 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoLLaVA-8K: Scaling Remote-Sensing Multimodal Large Language Models to 8K Resolution
May 27, 2025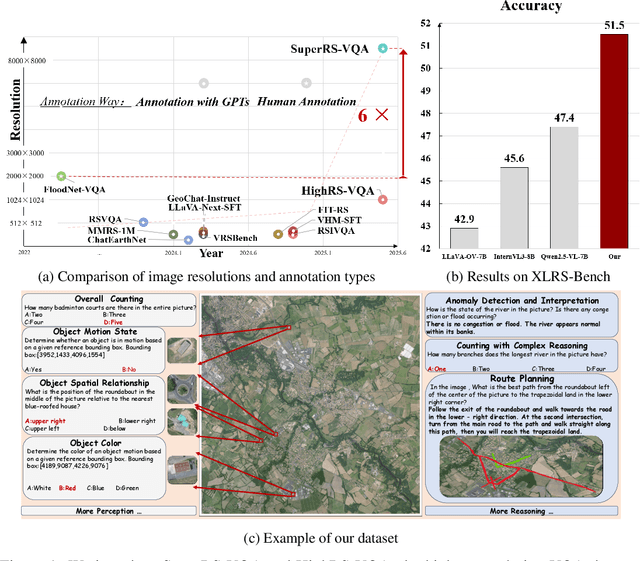
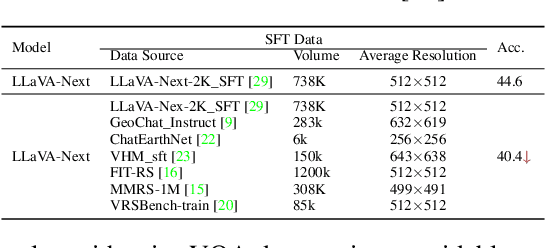
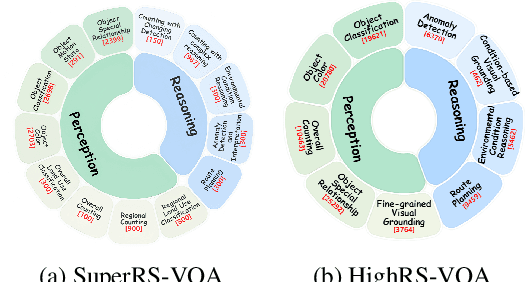
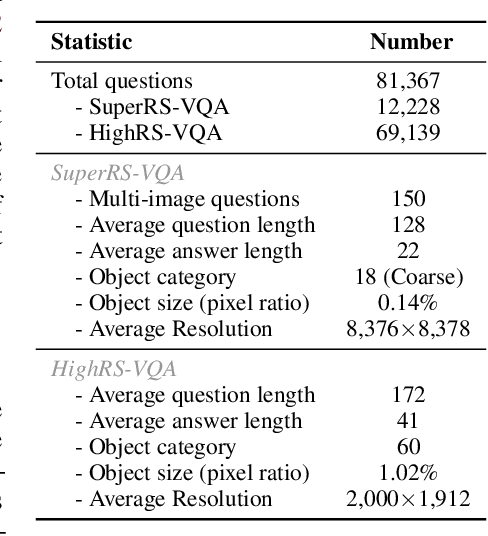
Ultra-high-resolution (UHR) remote sensing (RS) imagery offers valuable data for Earth observation but pose challenges for existing multimodal foundation models due to two key bottlenecks: (1) limited availability of UHR training data, and (2) token explosion caused by the large image size. To address data scarcity, we introduce SuperRS-VQA (avg. 8,376$\times$8,376) and HighRS-VQA (avg. 2,000$\times$1,912), the highest-resolution vision-language datasets in RS to date, covering 22 real-world dialogue tasks. To mitigate token explosion, our pilot studies reveal significant redundancy in RS images: crucial information is concentrated in a small subset of object-centric tokens, while pruning background tokens (e.g., ocean or forest) can even improve performance. Motivated by these findings, we propose two strategies: Background Token Pruning and Anchored Token Selection, to reduce the memory footprint while preserving key semantics.Integrating these techniques, we introduce GeoLLaVA-8K, the first RS-focused multimodal large language model capable of handling inputs up to 8K$\times$8K resolution, built on the LLaVA framework. Trained on SuperRS-VQA and HighRS-VQA, GeoLLaVA-8K sets a new state-of-the-art on the XLRS-Bench.
TritonBench: Benchmarking Large Language Model Capabilities for Generating Triton Operators
Feb 20, 2025Triton, a high-level Python-like language designed for building efficient GPU kernels, is widely adopted in deep learning frameworks due to its portability, flexibility, and accessibility. However, programming and parallel optimization still require considerable trial and error from Triton developers. Despite advances in large language models (LLMs) for conventional code generation, these models struggle to generate accurate, performance-optimized Triton code, as they lack awareness of its specifications and the complexities of GPU programming. More critically, there is an urgent need for systematic evaluations tailored to Triton. In this work, we introduce TritonBench, the first comprehensive benchmark for Triton operator generation. TritonBench features two evaluation channels: a curated set of 184 real-world operators from GitHub and a collection of operators aligned with PyTorch interfaces. Unlike conventional code benchmarks prioritizing functional correctness, TritonBench also profiles efficiency performance on widely deployed GPUs aligned with industry applications. Our study reveals that current state-of-the-art code LLMs struggle to generate efficient Triton operators, highlighting a significant gap in high-performance code generation. TritonBench will be available at https://github.com/thunlp/TritonBench.
Process Reinforcement through Implicit Rewards
Feb 03, 2025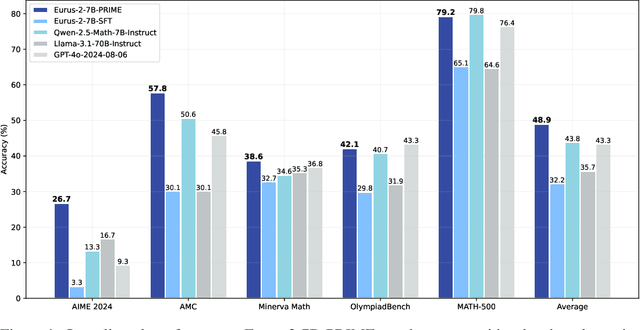

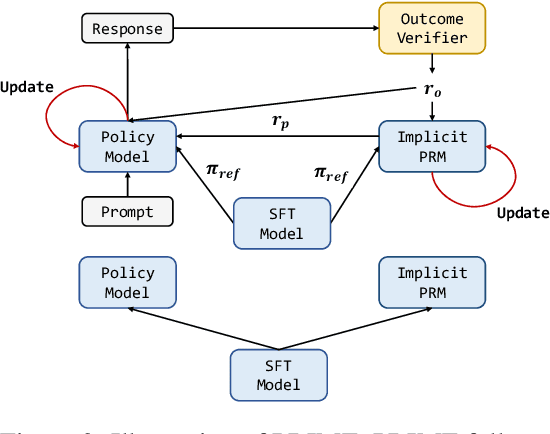
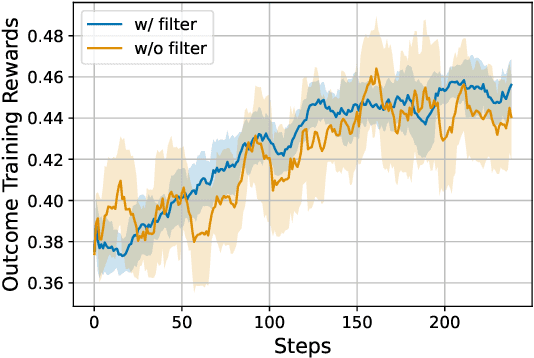
Dense process rewards have proven a more effective alternative to the sparse outcome-level rewards in the inference-time scaling of large language models (LLMs), particularly in tasks requiring complex multi-step reasoning. While dense rewards also offer an appealing choice for the reinforcement learning (RL) of LLMs since their fine-grained rewards have the potential to address some inherent issues of outcome rewards, such as training efficiency and credit assignment, this potential remains largely unrealized. This can be primarily attributed to the challenges of training process reward models (PRMs) online, where collecting high-quality process labels is prohibitively expensive, making them particularly vulnerable to reward hacking. To address these challenges, we propose PRIME (Process Reinforcement through IMplicit rEwards), which enables online PRM updates using only policy rollouts and outcome labels through implict process rewards. PRIME combines well with various advantage functions and forgoes the dedicated reward model training phrase that existing approaches require, substantially reducing the development overhead. We demonstrate PRIME's effectiveness on competitional math and coding. Starting from Qwen2.5-Math-7B-Base, PRIME achieves a 15.1% average improvement across several key reasoning benchmarks over the SFT model. Notably, our resulting model, Eurus-2-7B-PRIME, surpasses Qwen2.5-Math-7B-Instruct on seven reasoning benchmarks with 10% of its training data.
Graph Neural Patching for Cold-Start Recommendations
Oct 18, 2024



The cold start problem in recommender systems remains a critical challenge. Current solutions often train hybrid models on auxiliary data for both cold and warm users/items, potentially degrading the experience for the latter. This drawback limits their viability in practical scenarios where the satisfaction of existing warm users/items is paramount. Although graph neural networks (GNNs) excel at warm recommendations by effective collaborative signal modeling, they haven't been effectively leveraged for the cold-start issue within a user-item graph, which is largely due to the lack of initial connections for cold user/item entities. Addressing this requires a GNN adept at cold-start recommendations without sacrificing performance for existing ones. To this end, we introduce Graph Neural Patching for Cold-Start Recommendations (GNP), a customized GNN framework with dual functionalities: GWarmer for modeling collaborative signal on existing warm users/items and Patching Networks for simulating and enhancing GWarmer's performance on cold-start recommendations. Extensive experiments on three benchmark datasets confirm GNP's superiority in recommending both warm and cold users/items.
Protecting Your LLMs with Information Bottleneck
Apr 22, 2024



The advent of large language models (LLMs) has revolutionized the field of natural language processing, yet they might be attacked to produce harmful content. Despite efforts to ethically align LLMs, these are often fragile and can be circumvented by jailbreaking attacks through optimized or manual adversarial prompts. To address this, we introduce the Information Bottleneck Protector (IBProtector), a defense mechanism grounded in the information bottleneck principle, and we modify the objective to avoid trivial solutions. The IBProtector selectively compresses and perturbs prompts, facilitated by a lightweight and trainable extractor, preserving only essential information for the target LLMs to respond with the expected answer. Moreover, we further consider a situation where the gradient is not visible to be compatible with any LLM. Our empirical evaluations show that IBProtector outperforms current defense methods in mitigating jailbreak attempts, without overly affecting response quality or inference speed. Its effectiveness and adaptability across various attack methods and target LLMs underscore the potential of IBProtector as a novel, transferable defense that bolsters the security of LLMs without requiring modifications to the underlying models.
Explaining Time Series via Contrastive and Locally Sparse Perturbations
Jan 29, 2024



Explaining multivariate time series is a compound challenge, as it requires identifying important locations in the time series and matching complex temporal patterns. Although previous saliency-based methods addressed the challenges, their perturbation may not alleviate the distribution shift issue, which is inevitable especially in heterogeneous samples. We present ContraLSP, a locally sparse model that introduces counterfactual samples to build uninformative perturbations but keeps distribution using contrastive learning. Furthermore, we incorporate sample-specific sparse gates to generate more binary-skewed and smooth masks, which easily integrate temporal trends and select the salient features parsimoniously. Empirical studies on both synthetic and real-world datasets show that ContraLSP outperforms state-of-the-art models, demonstrating a substantial improvement in explanation quality for time series data. The source code is available at \url{https://github.com/zichuan-liu/ContraLSP}.
RCAgent: Cloud Root Cause Analysis by Autonomous Agents with Tool-Augmented Large Language Models
Oct 25, 2023



Large language model (LLM) applications in cloud root cause analysis (RCA) have been actively explored recently. However, current methods are still reliant on manual workflow settings and do not unleash LLMs' decision-making and environment interaction capabilities. We present RCAgent, a tool-augmented LLM autonomous agent framework for practical and privacy-aware industrial RCA usage. Running on an internally deployed model rather than GPT families, RCAgent is capable of free-form data collection and comprehensive analysis with tools. Our framework combines a variety of enhancements, including a unique Self-Consistency for action trajectories, and a suite of methods for context management, stabilization, and importing domain knowledge. Our experiments show RCAgent's evident and consistent superiority over ReAct across all aspects of RCA -- predicting root causes, solutions, evidence, and responsibilities -- and tasks covered or uncovered by current rules, as validated by both automated metrics and human evaluations. Furthermore, RCAgent has already been integrated into the diagnosis and issue discovery workflow of the Real-time Compute Platform for Apache Flink of Alibaba Cloud.
Multi-factor Sequential Re-ranking with Perception-Aware Diversification
May 21, 2023
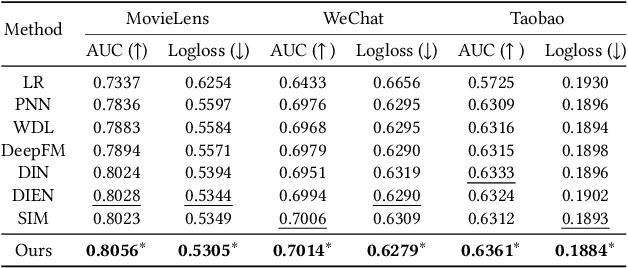
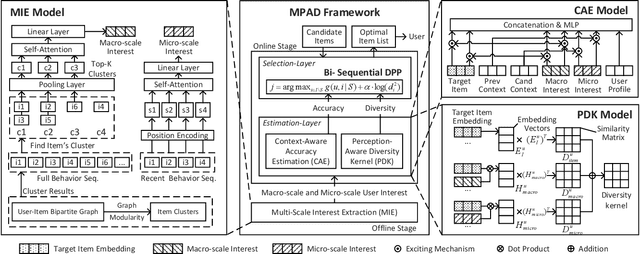
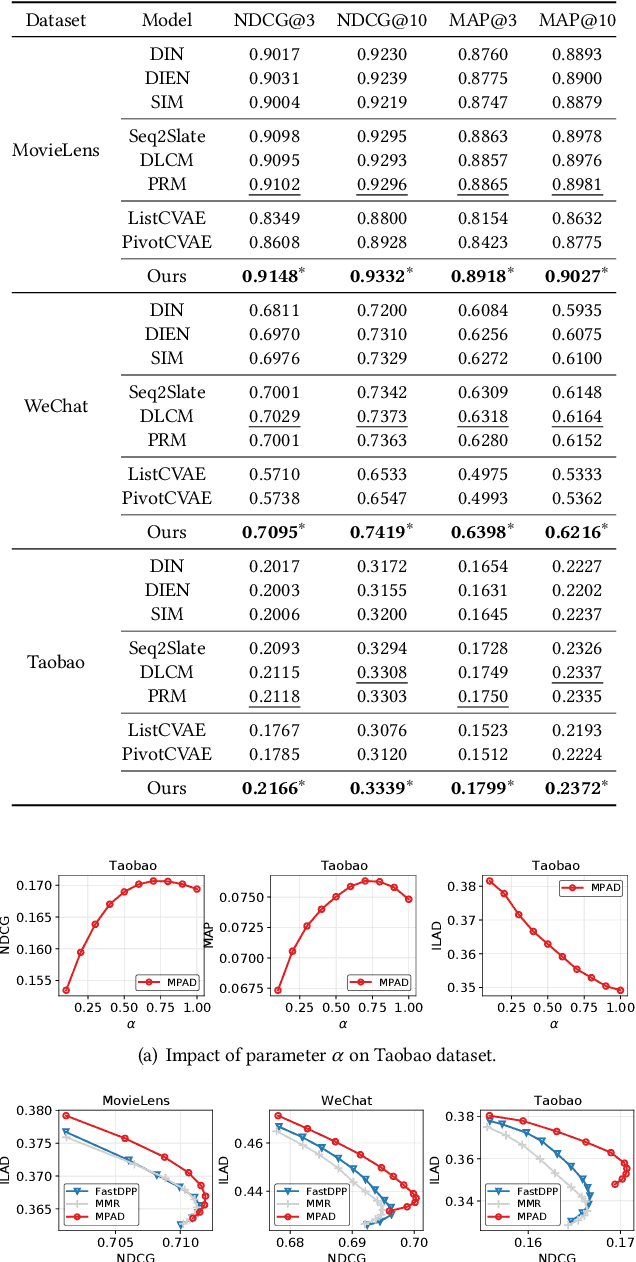
Feed recommendation systems, which recommend a sequence of items for users to browse and interact with, have gained significant popularity in practical applications. In feed products, users tend to browse a large number of items in succession, so the previously viewed items have a significant impact on users' behavior towards the following items. Therefore, traditional methods that mainly focus on improving the accuracy of recommended items are suboptimal for feed recommendations because they may recommend highly similar items. For feed recommendation, it is crucial to consider both the accuracy and diversity of the recommended item sequences in order to satisfy users' evolving interest when consecutively viewing items. To this end, this work proposes a general re-ranking framework named Multi-factor Sequential Re-ranking with Perception-Aware Diversification (MPAD) to jointly optimize accuracy and diversity for feed recommendation in a sequential manner. Specifically, MPAD first extracts users' different scales of interests from their behavior sequences through graph clustering-based aggregations. Then, MPAD proposes two sub-models to respectively evaluate the accuracy and diversity of a given item by capturing users' evolving interest due to the ever-changing context and users' personal perception of diversity from an item sequence perspective. This is consistent with the browsing nature of the feed scenario. Finally, MPAD generates the return list by sequentially selecting optimal items from the candidate set to maximize the joint benefits of accuracy and diversity of the entire list. MPAD has been implemented in Taobao's homepage feed to serve the main traffic and provide services to recommend billions of items to hundreds of millions of users every day.
GPatch: Patching Graph Neural Networks for Cold-Start Recommendations
Sep 25, 2022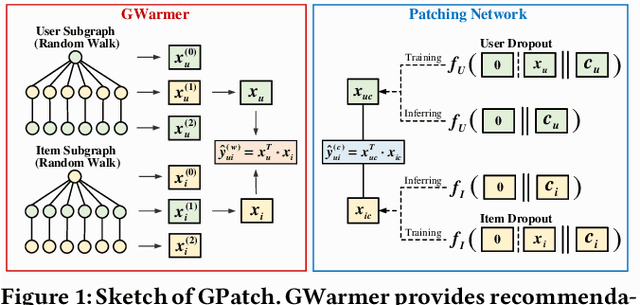
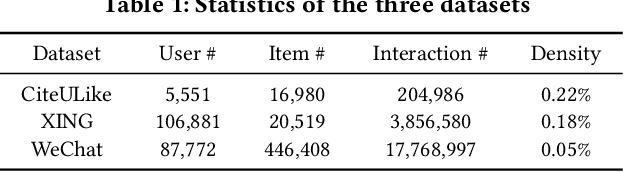

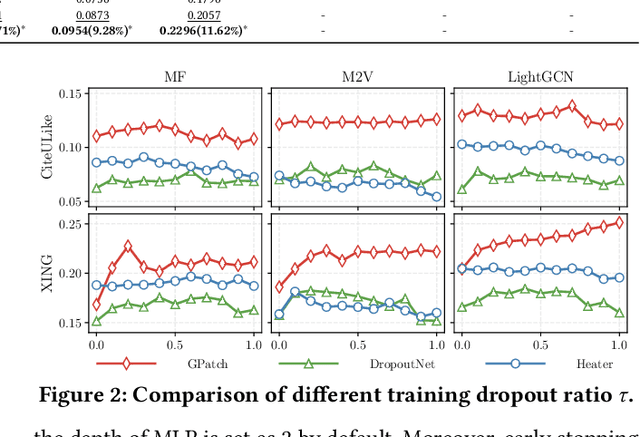
Cold start is an essential and persistent problem in recommender systems. State-of-the-art solutions rely on training hybrid models for both cold-start and existing users/items, based on the auxiliary information. Such a hybrid model would compromise the performance of existing users/items, which might make these solutions not applicable in real-worlds recommender systems where the experience of existing users/items must be guaranteed. Meanwhile, graph neural networks (GNNs) have been demonstrated to perform effectively warm (non-cold-start) recommendations. However, they have never been applied to handle the cold-start problem in a user-item bipartite graph. This is a challenging but rewarding task since cold-start users/items do not have links. Besides, it is nontrivial to design an appropriate GNN to conduct cold-start recommendations while maintaining the performance for existing users/items. To bridge the gap, we propose a tailored GNN-based framework (GPatch) that contains two separate but correlated components. First, an efficient GNN architecture -- GWarmer, is designed to model the warm users/items. Second, we construct correlated Patching Networks to simulate and patch GWarmer by conducting cold-start recommendations. Experiments on benchmark and large-scale commercial datasets demonstrate that GPatch is significantly superior in providing recommendations for both existing and cold-start users/items.