 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTritonBench: Benchmarking Large Language Model Capabilities for Generating Triton Operators
Feb 20, 2025Triton, a high-level Python-like language designed for building efficient GPU kernels, is widely adopted in deep learning frameworks due to its portability, flexibility, and accessibility. However, programming and parallel optimization still require considerable trial and error from Triton developers. Despite advances in large language models (LLMs) for conventional code generation, these models struggle to generate accurate, performance-optimized Triton code, as they lack awareness of its specifications and the complexities of GPU programming. More critically, there is an urgent need for systematic evaluations tailored to Triton. In this work, we introduce TritonBench, the first comprehensive benchmark for Triton operator generation. TritonBench features two evaluation channels: a curated set of 184 real-world operators from GitHub and a collection of operators aligned with PyTorch interfaces. Unlike conventional code benchmarks prioritizing functional correctness, TritonBench also profiles efficiency performance on widely deployed GPUs aligned with industry applications. Our study reveals that current state-of-the-art code LLMs struggle to generate efficient Triton operators, highlighting a significant gap in high-performance code generation. TritonBench will be available at https://github.com/thunlp/TritonBench.
Emotional Talking Head Generation based on Memory-Sharing and Attention-Augmented Networks
Jun 06, 2023Given an audio clip and a reference face image, the goal of the talking head generation is to generate a high-fidelity talking head video. Although some audio-driven methods of generating talking head videos have made some achievements in the past, most of them only focused on lip and audio synchronization and lack the ability to reproduce the facial expressions of the target person. To this end, we propose a talking head generation model consisting of a Memory-Sharing Emotion Feature extractor (MSEF) and an Attention-Augmented Translator based on U-net (AATU). Firstly, MSEF can extract implicit emotional auxiliary features from audio to estimate more accurate emotional face landmarks.~Secondly, AATU acts as a translator between the estimated landmarks and the photo-realistic video frames. Extensive qualitative and quantitative experiments have shown the superiority of the proposed method to the previous works. Codes will be made publicly available.
MAVD: The First Open Large-Scale Mandarin Audio-Visual Dataset with Depth Information
Jun 04, 2023Audio-visual speech recognition (AVSR) gains increasing attention from researchers as an important part of human-computer interaction. However, the existing available Mandarin audio-visual datasets are limited and lack the depth information. To address this issue, this work establishes the MAVD, a new large-scale Mandarin multimodal corpus comprising 12,484 utterances spoken by 64 native Chinese speakers. To ensure the dataset covers diverse real-world scenarios, a pipeline for cleaning and filtering the raw text material has been developed to create a well-balanced reading material. In particular, the latest data acquisition device of Microsoft, Azure Kinect is used to capture depth information in addition to the traditional audio signals and RGB images during data acquisition. We also provide a baseline experiment, which could be used to evaluate the effectiveness of the dataset. The dataset and code will be released at https://github.com/SpringHuo/MAVD.
Two-Stream Joint-Training for Speaker Independent Acoustic-to-Articulatory Inversion
Feb 26, 2023Acoustic-to-articulatory inversion (AAI) aims to estimate the parameters of articulators from speech audio. There are two common challenges in AAI, which are the limited data and the unsatisfactory performance in speaker independent scenario. Most current works focus on extracting features directly from speech and ignoring the importance of phoneme information which may limit the performance of AAI. To this end, we propose a novel network called SPN that uses two different streams to carry out the AAI task. Firstly, to improve the performance of speaker-independent experiment, we propose a new phoneme stream network to estimate the articulatory parameters as the phoneme features. To the best of our knowledge, this is the first work that extracts the speaker-independent features from phonemes to improve the performance of AAI. Secondly, in order to better represent the speech information, we train a speech stream network to combine the local features and the global features. Compared with state-of-the-art (SOTA), the proposed method reduces 0.18mm on RMSE and increases 6.0% on Pearson correlation coefficient in the speaker-independent experiment. The code has been released at https://github.com/liujinyu123/AAINetwork-SPN.
MVNet: Memory Assistance and Vocal Reinforcement Network for Speech Enhancement
Sep 15, 2022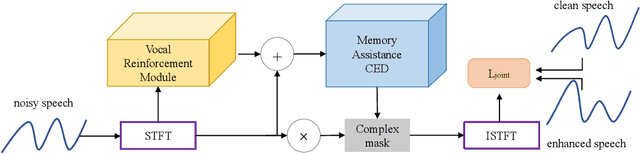
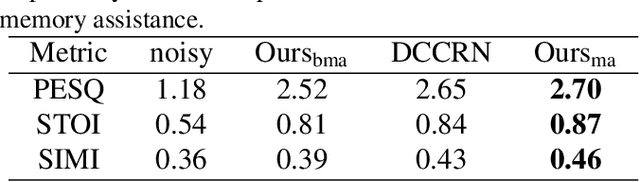
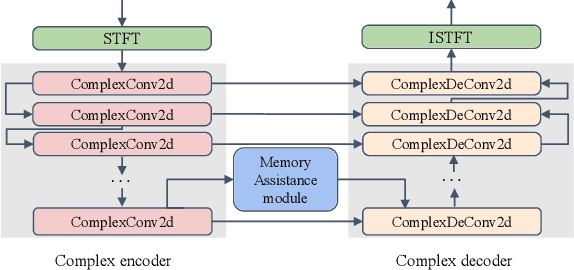
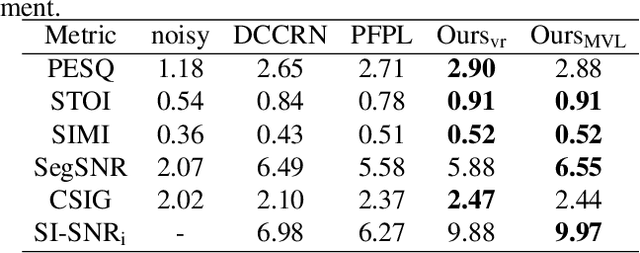
Speech enhancement improves speech quality and promotes the performance of various downstream tasks. However, most current speech enhancement work was mainly devoted to improving the performance of downstream automatic speech recognition (ASR), only a relatively small amount of work focused on the automatic speaker verification (ASV) task. In this work, we propose a MVNet consisted of a memory assistance module which improves the performance of downstream ASR and a vocal reinforcement module which boosts the performance of ASV. In addition, we design a new loss function to improve speaker vocal similarity. Experimental results on the Libri2mix dataset show that our method outperforms baseline methods in several metrics, including speech quality, intelligibility, and speaker vocal similarity et al.
Acoustic-to-articulatory Inversion based on Speech Decomposition and Auxiliary Feature
Apr 02, 2022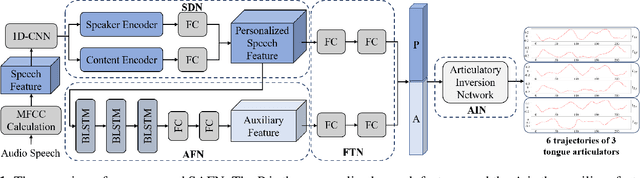
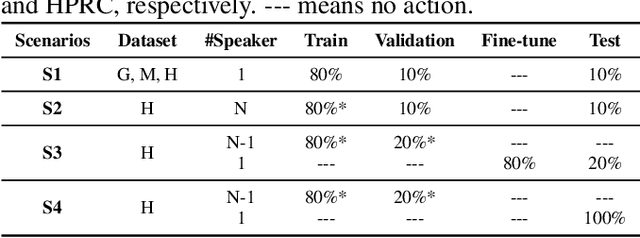
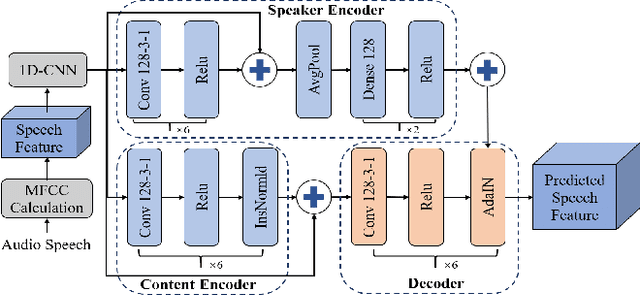
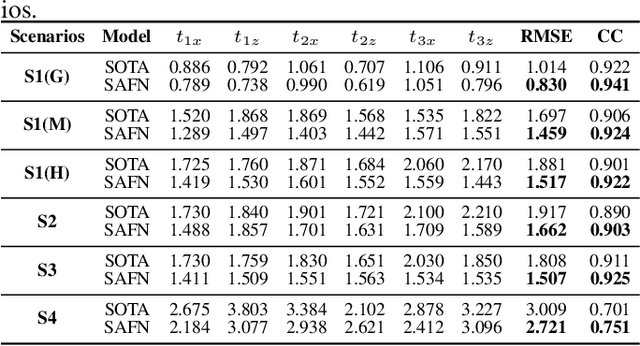
Acoustic-to-articulatory inversion (AAI) is to obtain the movement of articulators from speech signals. Until now, achieving a speaker-independent AAI remains a challenge given the limited data. Besides, most current works only use audio speech as input, causing an inevitable performance bottleneck. To solve these problems, firstly, we pre-train a speech decomposition network to decompose audio speech into speaker embedding and content embedding as the new personalized speech features to adapt to the speaker-independent case. Secondly, to further improve the AAI, we propose a novel auxiliary feature network to estimate the lip auxiliary features from the above personalized speech features. Experimental results on three public datasets show that, compared with the state-of-the-art only using the audio speech feature, the proposed method reduces the average RMSE by 0.25 and increases the average correlation coefficient by 2.0% in the speaker-dependent case. More importantly, the average RMSE decreases by 0.29 and the average correlation coefficient increases by 5.0% in the speaker-independent case.
Residual-guided Personalized Speech Synthesis based on Face Image
Apr 01, 2022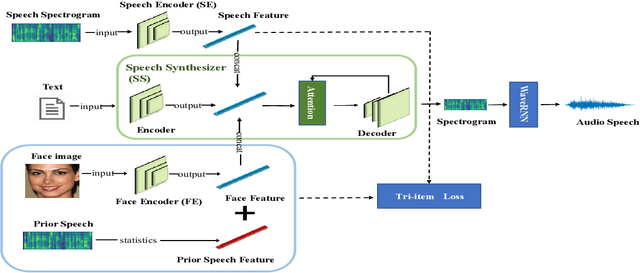

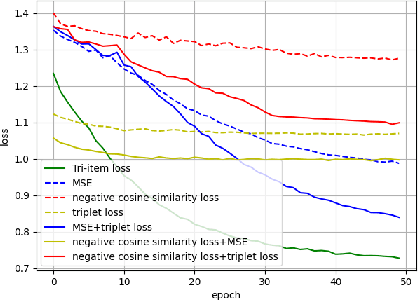

Previous works derive personalized speech features by training the model on a large dataset composed of his/her audio sounds. It was reported that face information has a strong link with the speech sound. Thus in this work, we innovatively extract personalized speech features from human faces to synthesize personalized speech using neural vocoder. A Face-based Residual Personalized Speech Synthesis Model (FR-PSS) containing a speech encoder, a speech synthesizer and a face encoder is designed for PSS. In this model, by designing two speech priors, a residual-guided strategy is introduced to guide the face feature to approach the true speech feature in the training. Moreover, considering the error of feature's absolute values and their directional bias, we formulate a novel tri-item loss function for face encoder. Experimental results show that the speech synthesized by our model is comparable to the personalized speech synthesized by training a large amount of audio data in previous works.
Cross-Modal Knowledge Distillation Method for Automatic Cued Speech Recognition
Jun 25, 2021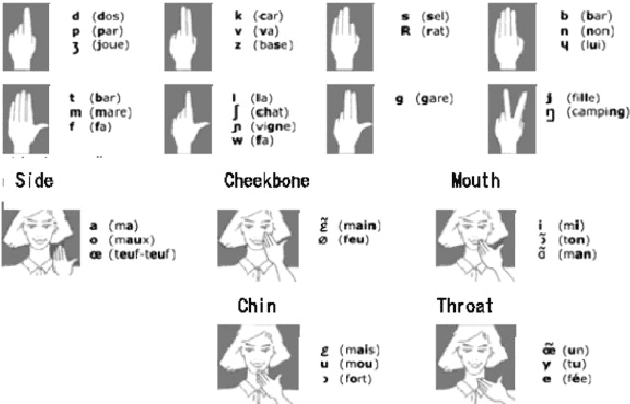
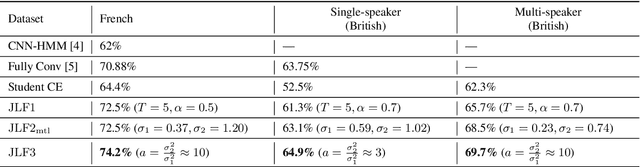
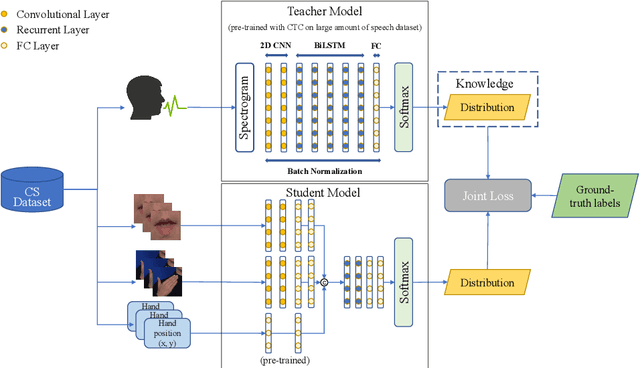
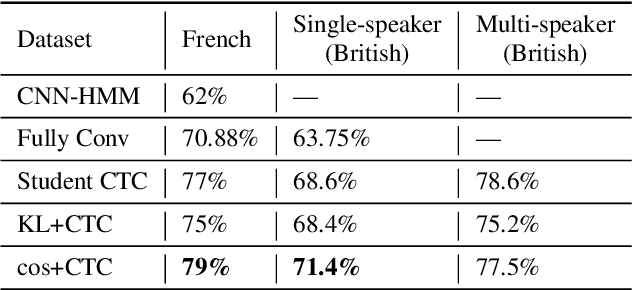
Cued Speech (CS) is a visual communication system for the deaf or hearing impaired people. It combines lip movements with hand cues to obtain a complete phonetic repertoire. Current deep learning based methods on automatic CS recognition suffer from a common problem, which is the data scarcity. Until now, there are only two public single speaker datasets for French (238 sentences) and British English (97 sentences). In this work, we propose a cross-modal knowledge distillation method with teacher-student structure, which transfers audio speech information to CS to overcome the limited data problem. Firstly, we pretrain a teacher model for CS recognition with a large amount of open source audio speech data, and simultaneously pretrain the feature extractors for lips and hands using CS data. Then, we distill the knowledge from teacher model to the student model with frame-level and sequence-level distillation strategies. Importantly, for frame-level, we exploit multi-task learning to weigh losses automatically, to obtain the balance coefficient. Besides, we establish a five-speaker British English CS dataset for the first time. The proposed method is evaluated on French and British English CS datasets, showing superior CS recognition performance to the state-of-the-art (SOTA) by a large margin.
Three-Dimensional Lip Motion Network for Text-Independent Speaker Recognition
Oct 13, 2020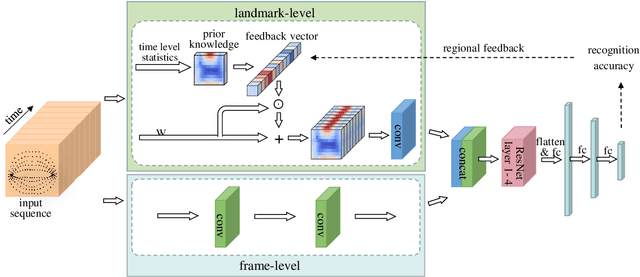
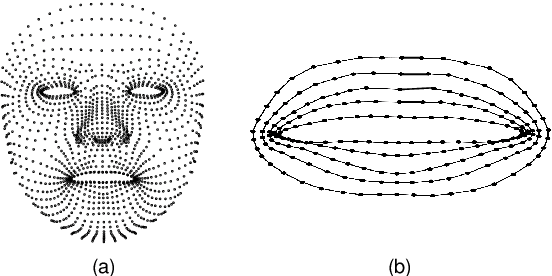

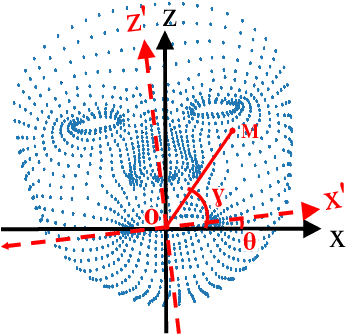
Lip motion reflects behavior characteristics of speakers, and thus can be used as a new kind of biometrics in speaker recognition. In the literature, lots of works used two-dimensional (2D) lip images to recognize speaker in a textdependent context. However, 2D lip easily suffers from various face orientations. To this end, in this work, we present a novel end-to-end 3D lip motion Network (3LMNet) by utilizing the sentence-level 3D lip motion (S3DLM) to recognize speakers in both the text-independent and text-dependent contexts. A new regional feedback module (RFM) is proposed to obtain attentions in different lip regions. Besides, prior knowledge of lip motion is investigated to complement RFM, where landmark-level and frame-level features are merged to form a better feature representation. Moreover, we present two methods, i.e., coordinate transformation and face posture correction to pre-process the LSD-AV dataset, which contains 68 speakers and 146 sentences per speaker. The evaluation results on this dataset demonstrate that our proposed 3LMNet is superior to the baseline models, i.e., LSTM, VGG-16 and ResNet-34, and outperforms the state-of-the-art using 2D lip image as well as the 3D face. The code of this work is released at https://github.com/wutong18/Three-Dimensional-Lip- Motion-Network-for-Text-Independent-Speaker-Recognition.
Attention-based Residual Speech Portrait Model for Speech to Face Generation
Jul 09, 2020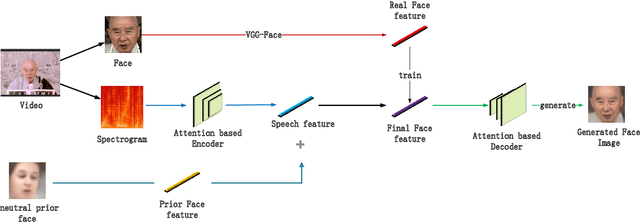

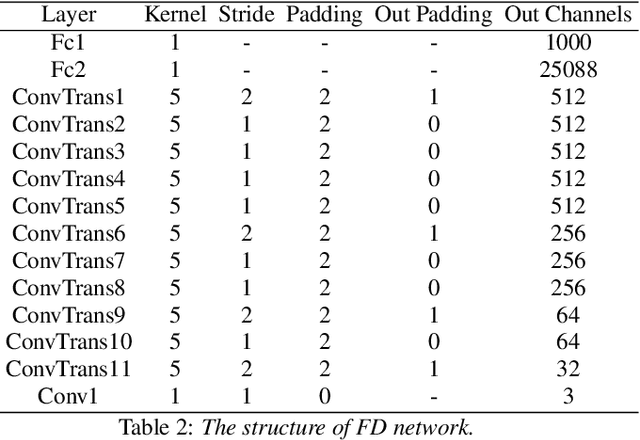

Given a speaker's speech, it is interesting to see if it is possible to generate this speaker's face. One main challenge in this task is to alleviate the natural mismatch between face and speech. To this end, in this paper, we propose a novel Attention-based Residual Speech Portrait Model (AR-SPM) by introducing the ideal of the residual into a hybrid encoder-decoder architecture, where face prior features are merged with the output of speech encoder to form the final face feature. In particular, we innovatively establish a tri-item loss function, which is a weighted linear combination of the L2-norm, L1-norm and negative cosine loss, to train our model by comparing the final face feature and true face feature. Evaluation on AVSpeech dataset shows that our proposed model accelerates the convergence of training, outperforms the state-of-the-art in terms of quality of the generated face, and achieves superior recognition accuracy of gender and age compared with the ground truth.