 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHalluClean: A Unified Framework to Combat Hallucinations in LLMs
Nov 19, 2025Large language models (LLMs) have achieved impressive performance across a wide range of natural language processing tasks, yet they often produce hallucinated content that undermines factual reliability. To address this challenge, we introduce HalluClean, a lightweight and task-agnostic framework for detecting and correcting hallucinations in LLM-generated text. HalluClean adopts a reasoning-enhanced paradigm, explicitly decomposing the process into planning, execution, and revision stages to identify and refine unsupported claims. It employs minimal task-routing prompts to enable zero-shot generalization across diverse domains, without relying on external knowledge sources or supervised detectors. We conduct extensive evaluations on five representative tasks-question answering, dialogue, summarization, math word problems, and contradiction detection. Experimental results show that HalluClean significantly improves factual consistency and outperforms competitive baselines, demonstrating its potential to enhance the trustworthiness of LLM outputs in real-world applications.
Emotional Talking Head Generation based on Memory-Sharing and Attention-Augmented Networks
Jun 06, 2023Given an audio clip and a reference face image, the goal of the talking head generation is to generate a high-fidelity talking head video. Although some audio-driven methods of generating talking head videos have made some achievements in the past, most of them only focused on lip and audio synchronization and lack the ability to reproduce the facial expressions of the target person. To this end, we propose a talking head generation model consisting of a Memory-Sharing Emotion Feature extractor (MSEF) and an Attention-Augmented Translator based on U-net (AATU). Firstly, MSEF can extract implicit emotional auxiliary features from audio to estimate more accurate emotional face landmarks.~Secondly, AATU acts as a translator between the estimated landmarks and the photo-realistic video frames. Extensive qualitative and quantitative experiments have shown the superiority of the proposed method to the previous works. Codes will be made publicly available.
MANet: Multimodal Attention Network based Point- View fusion for 3D Shape Recognition
Feb 28, 2020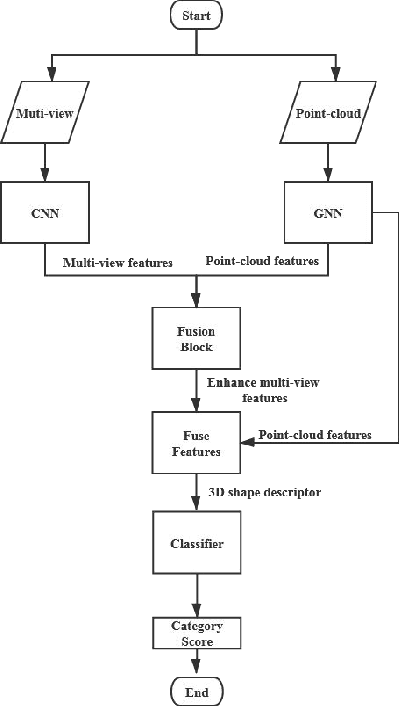
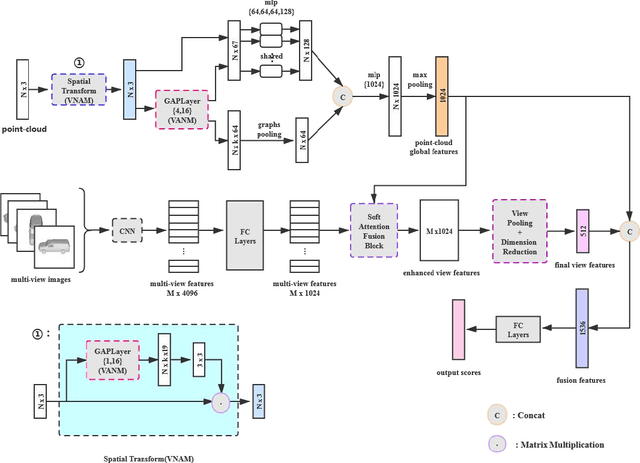
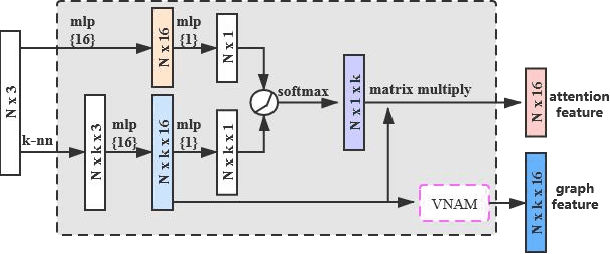
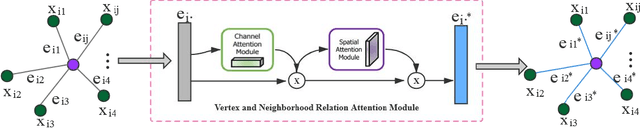
3D shape recognition has attracted more and more attention as a task of 3D vision research. The proliferation of 3D data encourages various deep learning methods based on 3D data. Now there have been many deep learning models based on point-cloud data or multi-view data alone. However, in the era of big data, integrating data of two different modals to obtain a unified 3D shape descriptor is bound to improve the recognition accuracy. Therefore, this paper proposes a fusion network based on multimodal attention mechanism for 3D shape recognition. Considering the limitations of multi-view data, we introduce a soft attention scheme, which can use the global point-cloud features to filter the multi-view features, and then realize the effective fusion of the two features. More specifically, we obtain the enhanced multi-view features by mining the contribution of each multi-view image to the overall shape recognition, and then fuse the point-cloud features and the enhanced multi-view features to obtain a more discriminative 3D shape descriptor. We have performed relevant experiments on the ModelNet40 dataset, and experimental results verify the effectiveness of our method.