 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Subtitle Feature Enhanced Video Outline Generation
Sep 01, 2022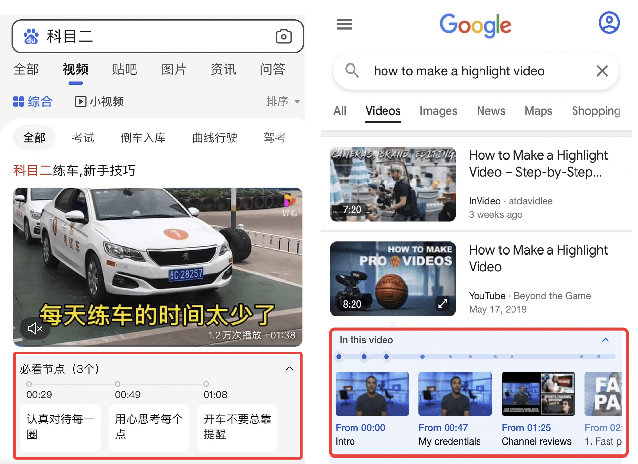
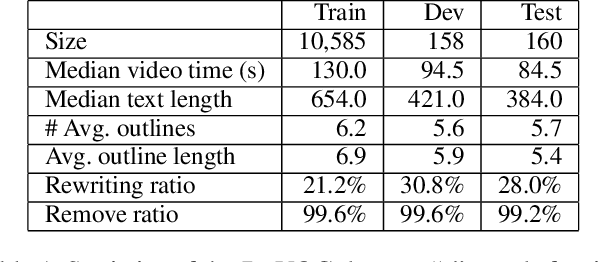

With the tremendously increasing number of videos, there is a great demand for techniques that help people quickly navigate to the video segments they are interested in. However, current works on video understanding mainly focus on video content summarization, while little effort has been made to explore the structure of a video. Inspired by textual outline generation, we introduce a novel video understanding task, namely video outline generation (VOG). This task is defined to contain two sub-tasks: (1) first segmenting the video according to the content structure and then (2) generating a heading for each segment. To learn and evaluate VOG, we annotate a 10k+ dataset, called DuVOG. Specifically, we use OCR tools to recognize subtitles of videos. Then annotators are asked to divide subtitles into chapters and title each chapter. In videos, highlighted text tends to be the headline since it is more likely to attract attention. Therefore we propose a Visual Subtitle feature Enhanced video outline generation model (VSENet) which takes as input the textual subtitles together with their visual font sizes and positions. We consider the VOG task as a sequence tagging problem that extracts spans where the headings are located and then rewrites them to form the final outlines. Furthermore, based on the similarity between video outlines and textual outlines, we use a large number of articles with chapter headings to pretrain our model. Experiments on DuVOG show that our model largely outperforms other baseline methods, achieving 77.1 of F1-score for the video segmentation level and 85.0 of ROUGE-L_F0.5 for the headline generation level.
MANet: Multimodal Attention Network based Point- View fusion for 3D Shape Recognition
Feb 28, 2020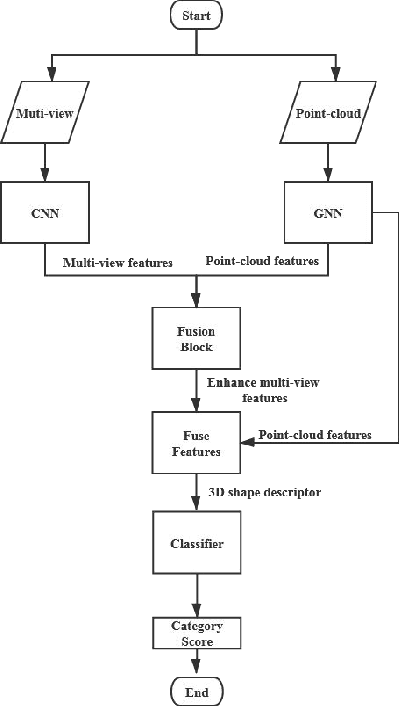
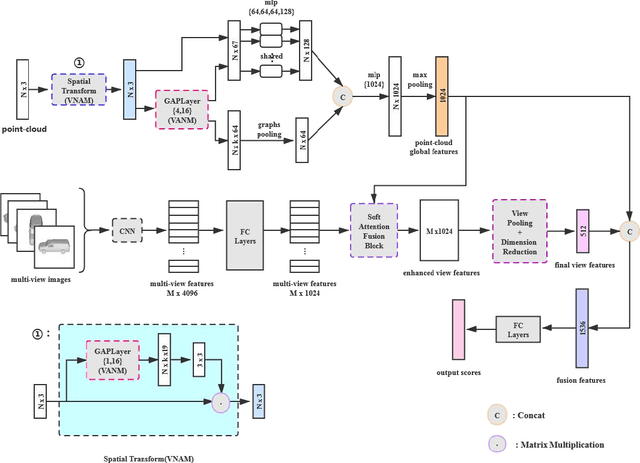
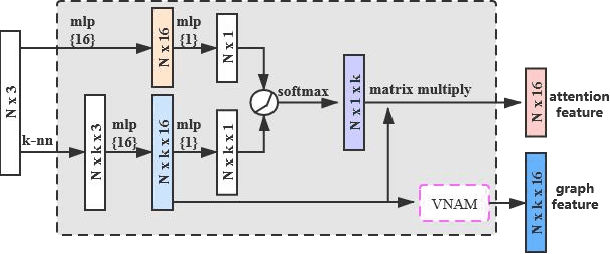
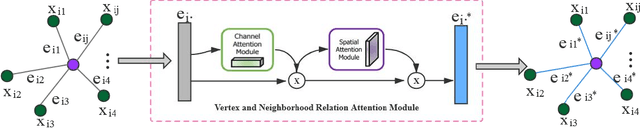
3D shape recognition has attracted more and more attention as a task of 3D vision research. The proliferation of 3D data encourages various deep learning methods based on 3D data. Now there have been many deep learning models based on point-cloud data or multi-view data alone. However, in the era of big data, integrating data of two different modals to obtain a unified 3D shape descriptor is bound to improve the recognition accuracy. Therefore, this paper proposes a fusion network based on multimodal attention mechanism for 3D shape recognition. Considering the limitations of multi-view data, we introduce a soft attention scheme, which can use the global point-cloud features to filter the multi-view features, and then realize the effective fusion of the two features. More specifically, we obtain the enhanced multi-view features by mining the contribution of each multi-view image to the overall shape recognition, and then fuse the point-cloud features and the enhanced multi-view features to obtain a more discriminative 3D shape descriptor. We have performed relevant experiments on the ModelNet40 dataset, and experimental results verify the effectiveness of our method.