 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBounded-Compute Multimodal Regression for Product-Rating Prediction
May 26, 2026Vision-language models (VLMs) are increasingly attractive for multimodal quality assessment, but their default reliance on autoregressive text generation and dynamic visual processing is poorly matched to scalar regression under strict latency budgets. We present a bounded-compute adaptation of SmolVLM2-256M-Video-Instruct for product-rating prediction in the LoViF 2026 Efficient VLM challenge. Motivated by recent multimodal engagement-prediction results showing that feature-based regression can outperform token-based score generation, we replace the language-modeling head with a lightweight two-layer MLP fed by pooled decoder states, and we enforce deterministic inputs through fixed 384x384 images and truncated metadata. Across controlled ablations, static global image processing slightly outperforms dynamic tiling, and scaling from 100K to 16M training examples substantially improves validation correlation. Under the official held-out evaluation, our 228M-parameter model achieves 0.39 PLCC and 0.40 CES, providing a strong and reproducible baseline for resource-constrained multimodal regression.
ProCrit: Self-Elicited Multi-Perspective Reasoning with Critic-Guided Revision for Multimodal Sarcasm Detection
May 20, 2026Multimodal sarcasm detection requires reasoning over cross-modal incongruities between literal expression and intended meaning, yet the specific analytical perspectives needed vary across samples due to the diversity of sarcastic mechanisms. While recent methods make this analytical process explicit, they still rely on fixed, predefined perspectives that operate independently under hand-crafted routing rules. We argue that multimodal sarcasm detection instead calls for self-elicited multi-perspective reasoning, where a model autonomously generates the perspectives needed for each sample and progressively integrates them into a coherent analysis. To realize this goal, we propose ProCrit, a Proposal-Critic two-agent framework with a proposal agent for multi-perspective reasoning and a critic agent for external evaluation and targeted revision guidance. First, to overcome the lack of process-level supervision in existing sarcasm datasets, ProCrit synthesizes process-level reasoning annotations through a dynamic-role agentic rollout: a strong vision-language model sequentially spawns analytical roles within a shared context, and the resulting multi-role trajectories are flattened into sequences that preserve cross-perspective dependencies while enabling efficient autoregressive generation. Second, to improve reasoning reliability, ProCrit adopts a draft-critique-revise paradigm in which an independent critic identifies reasoning deficiencies and provides targeted natural-language feedback for directed revision. Finally, we develop a mutual-refinement training framework that jointly optimizes proposal drafting and feedback-guided revision via dual-stage reinforcement learning, while refining the critic agent according to the actual effectiveness of its feedback. Experiments on three widely used benchmarks demonstrate the effectiveness of ProCrit.
VISOR: Agentic Visual Retrieval-Augmented Generation via Iterative Search and Over-horizon Reasoning
Apr 10, 2026Visual Retrieval-Augmented Generation (VRAG) empowers Vision-Language Models to retrieve and reason over visually rich documents. To tackle complex queries requiring multi-step reasoning, agentic VRAG systems interleave reasoning with iterative retrieval.. However, existing agentic VRAG faces two critical bottlenecks. (1) Visual Evidence Sparsity: key evidence is scattered across pages yet processed in isolation, hindering cross-page reasoning; moreover, fine-grained intra-image evidence often requires precise visual actions, whose misuse degrades retrieval quality; (2) Search Drift in Long Horizons: the accumulation of visual tokens across retrieved pages dilutes context and causes cognitive overload, leading agents to deviate from their search objective. To address these challenges, we propose VISOR (Visual Retrieval-Augmented Generation via Iterative Search and Over-horizon Reasoning), a unified single-agent framework. VISOR features a structured Evidence Space for progressive cross-page reasoning, coupled with a Visual Action Evaluation and Correction mechanism to manage visual actions. Additionally, we introduce a Dynamic Trajectory with Sliding Window and Intent Injection to mitigate search drift. They anchor the evidence space while discarding earlier raw interactions, preventing context from being overwhelmed by visual tokens. We train VISOR using a Group Relative Policy Optimization-based Reinforcement Learning (GRPO-based RL) pipeline with state masking and credit assignment tailored for dynamic context reconstruction. Extensive experiments on ViDoSeek, SlideVQA, and MMLongBench demonstrate that VISOR achieves state-of-the-art performance with superior efficiency for long-horizon visual reasoning tasks.
GigaWorld-Policy: An Efficient Action-Centered World--Action Model
Mar 18, 2026World-Action Models (WAM) initialized from pre-trained video generation backbones have demonstrated remarkable potential for robot policy learning. However, existing approaches face two critical bottlenecks that hinder performance and deployment. First, jointly reasoning over future visual dynamics and corresponding actions incurs substantial inference overhead. Second, joint modeling often entangles visual and motion representations, making motion prediction accuracy heavily dependent on the quality of future video forecasts. To address these issues, we introduce GigaWorld-Policy, an action-centered WAM that learns 2D pixel-action dynamics while enabling efficient action decoding, with optional video generation. Specifically, we formulate policy training into two coupled components: the model predicts future action sequences conditioned on the current observation, and simultaneously generates future videos conditioned on the predicted actions and the same observation. The policy is supervised by both action prediction and video generation, providing richer learning signals and encouraging physically plausible actions through visual-dynamics constraints. With a causal design that prevents future-video tokens from influencing action tokens, explicit future-video generation is optional at inference time, allowing faster action prediction during deployment. To support this paradigm, we curate a diverse, large-scale robot dataset to pre-train an action-centered video generation model, which is then adapted as the backbone for robot policy learning. Experimental results on real-world robotic platforms show that GigaWorld-Policy runs 9x faster than the leading WAM baseline, Motus, while improving task success rates by 7%. Moreover, compared with pi-0.5, GigaWorld-Policy improves performance by 95% on RoboTwin 2.0.
Facial-R1: Aligning Reasoning and Recognition for Facial Emotion Analysis
Nov 13, 2025
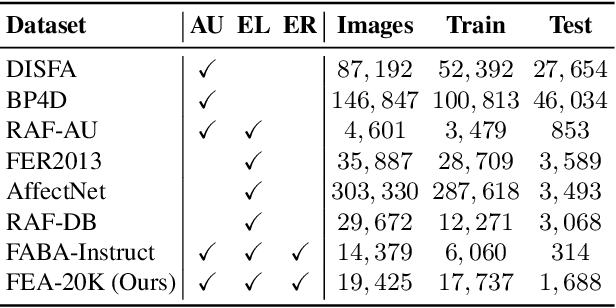
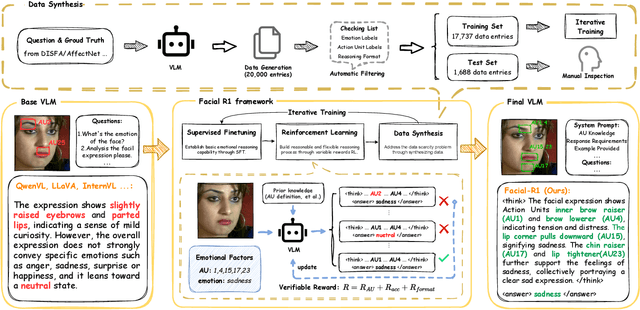
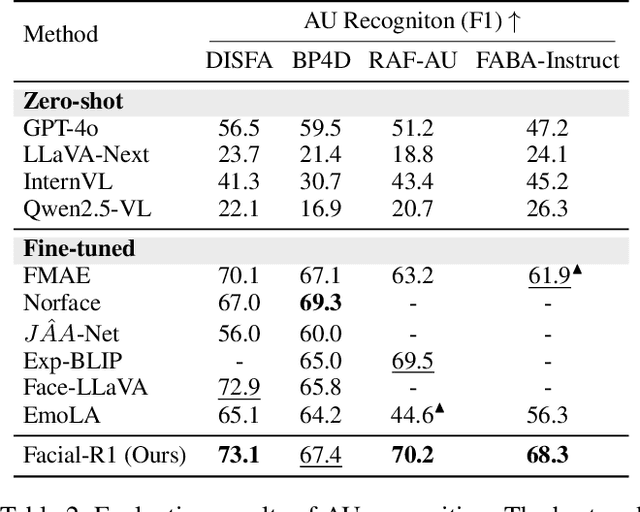
Facial Emotion Analysis (FEA) extends traditional facial emotion recognition by incorporating explainable, fine-grained reasoning. The task integrates three subtasks: emotion recognition, facial Action Unit (AU) recognition, and AU-based emotion reasoning to model affective states jointly. While recent approaches leverage Vision-Language Models (VLMs) and achieve promising results, they face two critical limitations: (1) hallucinated reasoning, where VLMs generate plausible but inaccurate explanations due to insufficient emotion-specific knowledge; and (2) misalignment between emotion reasoning and recognition, caused by fragmented connections between observed facial features and final labels. We propose Facial-R1, a three-stage alignment framework that effectively addresses both challenges with minimal supervision. First, we employ instruction fine-tuning to establish basic emotional reasoning capability. Second, we introduce reinforcement training guided by emotion and AU labels as reward signals, which explicitly aligns the generated reasoning process with the predicted emotion. Third, we design a data synthesis pipeline that iteratively leverages the prior stages to expand the training dataset, enabling scalable self-improvement of the model. Built upon this framework, we introduce FEA-20K, a benchmark dataset comprising 17,737 training and 1,688 test samples with fine-grained emotion analysis annotations. Extensive experiments across eight standard benchmarks demonstrate that Facial-R1 achieves state-of-the-art performance in FEA, with strong generalization and robust interpretability.
Text-based Aerial-Ground Person Retrieval
Nov 11, 2025This work introduces Text-based Aerial-Ground Person Retrieval (TAG-PR), which aims to retrieve person images from heterogeneous aerial and ground views with textual descriptions. Unlike traditional Text-based Person Retrieval (T-PR), which focuses solely on ground-view images, TAG-PR introduces greater practical significance and presents unique challenges due to the large viewpoint discrepancy across images. To support this task, we contribute: (1) TAG-PEDES dataset, constructed from public benchmarks with automatically generated textual descriptions, enhanced by a diversified text generation paradigm to ensure robustness under view heterogeneity; and (2) TAG-CLIP, a novel retrieval framework that addresses view heterogeneity through a hierarchically-routed mixture of experts module to learn view-specific and view-agnostic features and a viewpoint decoupling strategy to decouple view-specific features for better cross-modal alignment. We evaluate the effectiveness of TAG-CLIP on both the proposed TAG-PEDES dataset and existing T-PR benchmarks. The dataset and code are available at https://github.com/Flame-Chasers/TAG-PR.
SA-Person: Text-Based Person Retrieval with Scene-aware Re-ranking
May 30, 2025Text-based person retrieval aims to identify a target individual from a gallery of images based on a natural language description. It presents a significant challenge due to the complexity of real-world scenes and the ambiguity of appearance-related descriptions. Existing methods primarily emphasize appearance-based cross-modal retrieval, often neglecting the contextual information embedded within the scene, which can offer valuable complementary insights for retrieval. To address this, we introduce SCENEPERSON-13W, a large-scale dataset featuring over 100,000 scenes with rich annotations covering both pedestrian appearance and environmental cues. Based on this, we propose SA-Person, a two-stage retrieval framework. In the first stage, it performs discriminative appearance grounding by aligning textual cues with pedestrian-specific regions. In the second stage, it introduces SceneRanker, a training-free, scene-aware re-ranking method leveraging multimodal large language models to jointly reason over pedestrian appearance and the global scene context. Experiments on SCENEPERSON-13W validate the effectiveness of our framework in challenging scene-level retrieval scenarios. The code and dataset will be made publicly available.
MAIR: A Massive Benchmark for Evaluating Instructed Retrieval
Oct 14, 2024



Recent information retrieval (IR) models are pre-trained and instruction-tuned on massive datasets and tasks, enabling them to perform well on a wide range of tasks and potentially generalize to unseen tasks with instructions. However, existing IR benchmarks focus on a limited scope of tasks, making them insufficient for evaluating the latest IR models. In this paper, we propose MAIR (Massive Instructed Retrieval Benchmark), a heterogeneous IR benchmark that includes 126 distinct IR tasks across 6 domains, collected from existing datasets. We benchmark state-of-the-art instruction-tuned text embedding models and re-ranking models. Our experiments reveal that instruction-tuned models generally achieve superior performance compared to non-instruction-tuned models on MAIR. Additionally, our results suggest that current instruction-tuned text embedding models and re-ranking models still lack effectiveness in specific long-tail tasks. MAIR is publicly available at https://github.com/sunnweiwei/Mair.
Semi-supervised Text-based Person Search
Apr 28, 2024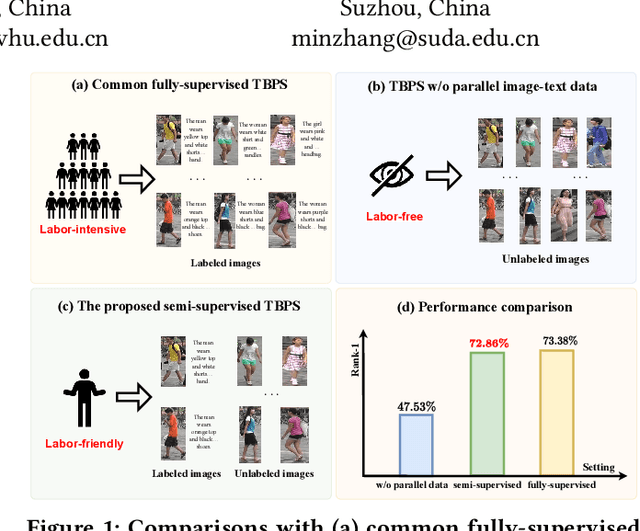
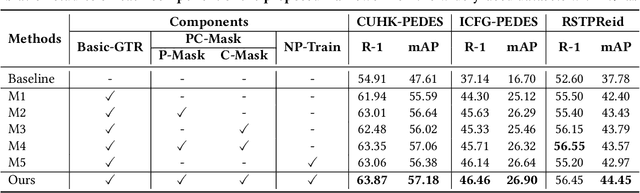
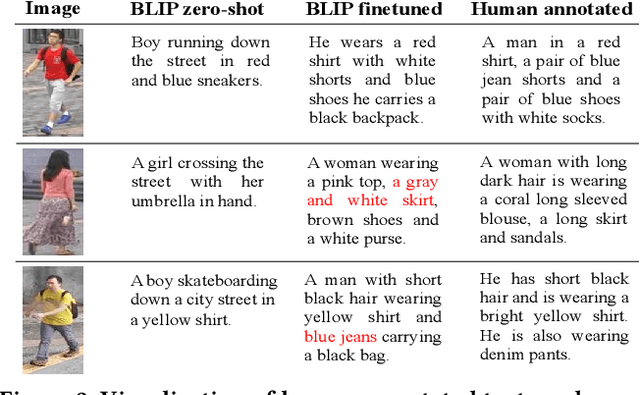
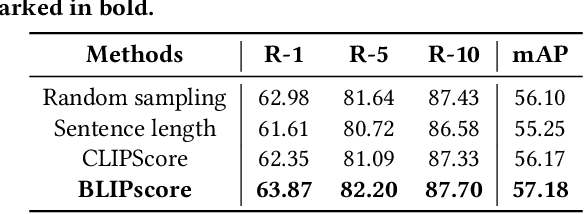
Text-based person search (TBPS) aims to retrieve images of a specific person from a large image gallery based on a natural language description. Existing methods rely on massive annotated image-text data to achieve satisfactory performance in fully-supervised learning. It poses a significant challenge in practice, as acquiring person images from surveillance videos is relatively easy, while obtaining annotated texts is challenging. The paper undertakes a pioneering initiative to explore TBPS under the semi-supervised setting, where only a limited number of person images are annotated with textual descriptions while the majority of images lack annotations. We present a two-stage basic solution based on generation-then-retrieval for semi-supervised TBPS. The generation stage enriches annotated data by applying an image captioning model to generate pseudo-texts for unannotated images. Later, the retrieval stage performs fully-supervised retrieval learning using the augmented data. Significantly, considering the noise interference of the pseudo-texts on retrieval learning, we propose a noise-robust retrieval framework that enhances the ability of the retrieval model to handle noisy data. The framework integrates two key strategies: Hybrid Patch-Channel Masking (PC-Mask) to refine the model architecture, and Noise-Guided Progressive Training (NP-Train) to enhance the training process. PC-Mask performs masking on the input data at both the patch-level and the channel-level to prevent overfitting noisy supervision. NP-Train introduces a progressive training schedule based on the noise level of pseudo-texts to facilitate noise-robust learning. Extensive experiments on multiple TBPS benchmarks show that the proposed framework achieves promising performance under the semi-supervised setting.
An Empirical Study of Frame Selection for Text-to-Video Retrieval
Nov 01, 2023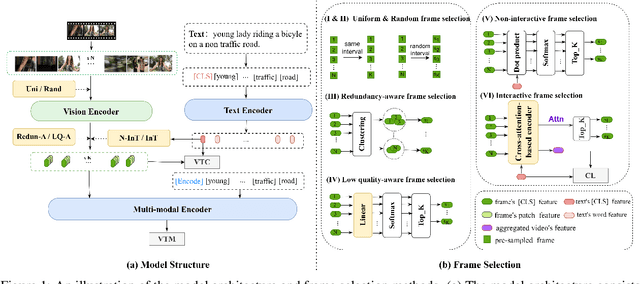
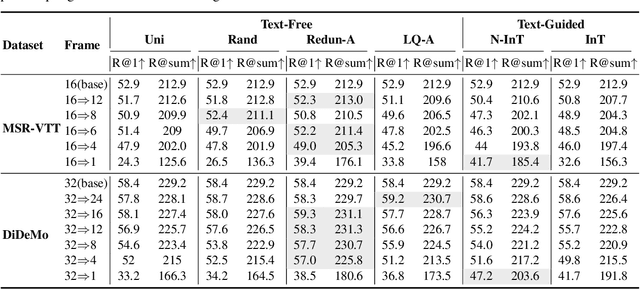
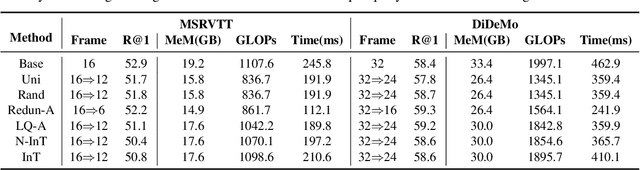

Text-to-video retrieval (TVR) aims to find the most relevant video in a large video gallery given a query text. The intricate and abundant context of the video challenges the performance and efficiency of TVR. To handle the serialized video contexts, existing methods typically select a subset of frames within a video to represent the video content for TVR. How to select the most representative frames is a crucial issue, whereby the selected frames are required to not only retain the semantic information of the video but also promote retrieval efficiency by excluding temporally redundant frames. In this paper, we make the first empirical study of frame selection for TVR. We systemically classify existing frame selection methods into text-free and text-guided ones, under which we detailedly analyze six different frame selections in terms of effectiveness and efficiency. Among them, two frame selections are first developed in this paper. According to the comprehensive analysis on multiple TVR benchmarks, we empirically conclude that the TVR with proper frame selections can significantly improve the retrieval efficiency without sacrificing the retrieval performance.