 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Transformation-Isomorphic Latent Space for Accurate Hand Pose Estimation
Feb 18, 2025Vision-based regression tasks, such as hand pose estimation, have achieved higher accuracy and faster convergence through representation learning. However, existing representation learning methods often encounter the following issues: the high semantic level of features extracted from images is inadequate for regressing low-level information, and the extracted features include task-irrelevant information, reducing their compactness and interfering with regression tasks. To address these challenges, we propose TI-Net, a highly versatile visual Network backbone designed to construct a Transformation Isomorphic latent space. Specifically, we employ linear transformations to model geometric transformations in the latent space and ensure that {\rm TI-Net} aligns them with those in the image space. This ensures that the latent features capture compact, low-level information beneficial for pose estimation tasks. We evaluated TI-Net on the hand pose estimation task to demonstrate the network's superiority. On the DexYCB dataset, TI-Net achieved a 10% improvement in the PA-MPJPE metric compared to specialized state-of-the-art (SOTA) hand pose estimation methods. Our code will be released in the future.
MyPortrait: Morphable Prior-Guided Personalized Portrait Generation
Dec 05, 2023Generating realistic talking faces is an interesting and long-standing topic in the field of computer vision. Although significant progress has been made, it is still challenging to generate high-quality dynamic faces with personalized details. This is mainly due to the inability of the general model to represent personalized details and the generalization problem to unseen controllable parameters. In this work, we propose Myportrait, a simple, general, and flexible framework for neural portrait generation. We incorporate personalized prior in a monocular video and morphable prior in 3D face morphable space for generating personalized details under novel controllable parameters. Our proposed framework supports both video-driven and audio-driven face animation given a monocular video of a single person. Distinguished by whether the test data is sent to training or not, our method provides a real-time online version and a high-quality offline version. Comprehensive experiments in various metrics demonstrate the superior performance of our method over the state-of-the-art methods. The code will be publicly available.
Probabilistic Triangulation for Uncalibrated Multi-View 3D Human Pose Estimation
Sep 09, 2023



3D human pose estimation has been a long-standing challenge in computer vision and graphics, where multi-view methods have significantly progressed but are limited by the tedious calibration processes. Existing multi-view methods are restricted to fixed camera pose and therefore lack generalization ability. This paper presents a novel Probabilistic Triangulation module that can be embedded in a calibrated 3D human pose estimation method, generalizing it to uncalibration scenes. The key idea is to use a probability distribution to model the camera pose and iteratively update the distribution from 2D features instead of using camera pose. Specifically, We maintain a camera pose distribution and then iteratively update this distribution by computing the posterior probability of the camera pose through Monte Carlo sampling. This way, the gradients can be directly back-propagated from the 3D pose estimation to the 2D heatmap, enabling end-to-end training. Extensive experiments on Human3.6M and CMU Panoptic demonstrate that our method outperforms other uncalibration methods and achieves comparable results with state-of-the-art calibration methods. Thus, our method achieves a trade-off between estimation accuracy and generalizability. Our code is in https://github.com/bymaths/probabilistic_triangulation
AttT2M: Text-Driven Human Motion Generation with Multi-Perspective Attention Mechanism
Sep 02, 2023Generating 3D human motion based on textual descriptions has been a research focus in recent years. It requires the generated motion to be diverse, natural, and conform to the textual description. Due to the complex spatio-temporal nature of human motion and the difficulty in learning the cross-modal relationship between text and motion, text-driven motion generation is still a challenging problem. To address these issues, we propose \textbf{AttT2M}, a two-stage method with multi-perspective attention mechanism: \textbf{body-part attention} and \textbf{global-local motion-text attention}. The former focuses on the motion embedding perspective, which means introducing a body-part spatio-temporal encoder into VQ-VAE to learn a more expressive discrete latent space. The latter is from the cross-modal perspective, which is used to learn the sentence-level and word-level motion-text cross-modal relationship. The text-driven motion is finally generated with a generative transformer. Extensive experiments conducted on HumanML3D and KIT-ML demonstrate that our method outperforms the current state-of-the-art works in terms of qualitative and quantitative evaluation, and achieve fine-grained synthesis and action2motion. Our code is in https://github.com/ZcyMonkey/AttT2M
Unpaired Multi-domain Attribute Translation of 3D Facial Shapes with a Square and Symmetric Geometric Map
Aug 25, 2023
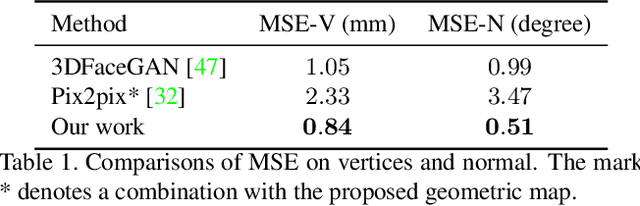
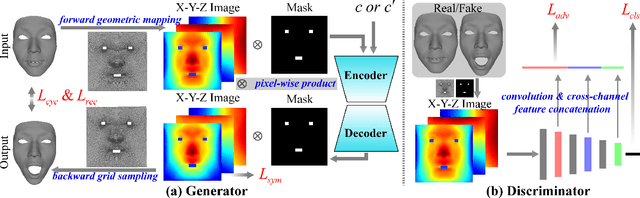
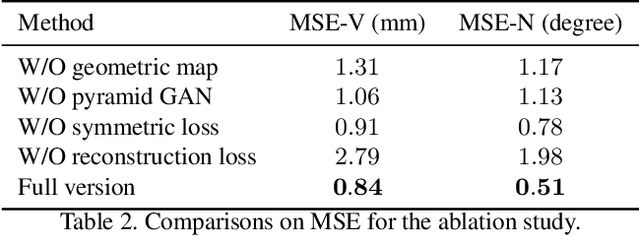
While impressive progress has recently been made in image-oriented facial attribute translation, shape-oriented 3D facial attribute translation remains an unsolved issue. This is primarily limited by the lack of 3D generative models and ineffective usage of 3D facial data. We propose a learning framework for 3D facial attribute translation to relieve these limitations. Firstly, we customize a novel geometric map for 3D shape representation and embed it in an end-to-end generative adversarial network. The geometric map represents 3D shapes symmetrically on a square image grid, while preserving the neighboring relationship of 3D vertices in a local least-square sense. This enables effective learning for the latent representation of data with different attributes. Secondly, we employ a unified and unpaired learning framework for multi-domain attribute translation. It not only makes effective usage of data correlation from multiple domains, but also mitigates the constraint for hardly accessible paired data. Finally, we propose a hierarchical architecture for the discriminator to guarantee robust results against both global and local artifacts. We conduct extensive experiments to demonstrate the advantage of the proposed framework over the state-of-the-art in generating high-fidelity facial shapes. Given an input 3D facial shape, the proposed framework is able to synthesize novel shapes of different attributes, which covers some downstream applications, such as expression transfer, gender translation, and aging. Code at https://github.com/NaughtyZZ/3D_facial_shape_attribute_translation_ssgmap.
Pose-aware Attention Network for Flexible Motion Retargeting by Body Part
Jun 13, 2023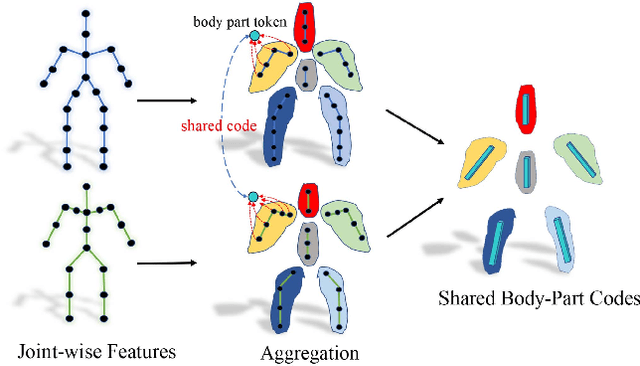
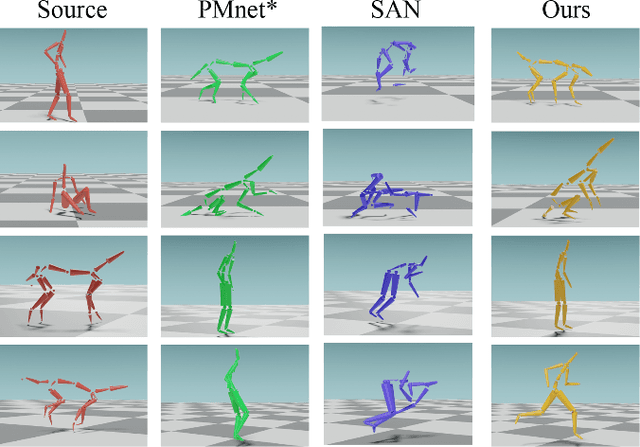
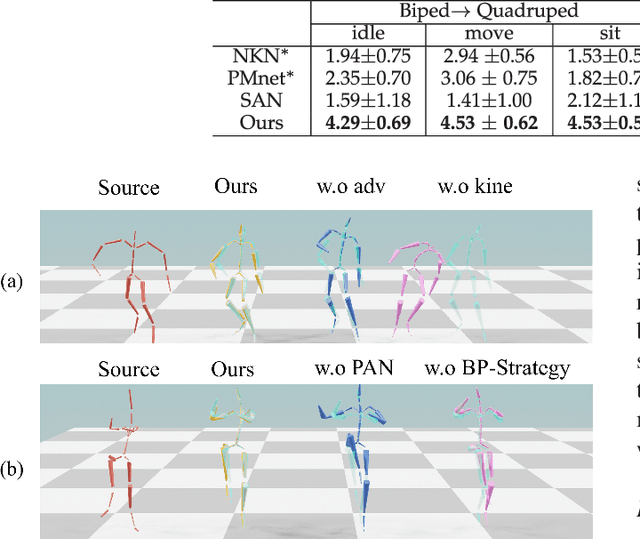
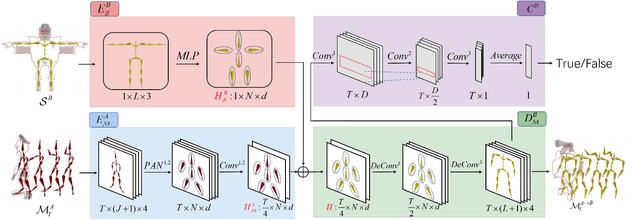
Motion retargeting is a fundamental problem in computer graphics and computer vision. Existing approaches usually have many strict requirements, such as the source-target skeletons needing to have the same number of joints or share the same topology. To tackle this problem, we note that skeletons with different structure may have some common body parts despite the differences in joint numbers. Following this observation, we propose a novel, flexible motion retargeting framework. The key idea of our method is to regard the body part as the basic retargeting unit rather than directly retargeting the whole body motion. To enhance the spatial modeling capability of the motion encoder, we introduce a pose-aware attention network (PAN) in the motion encoding phase. The PAN is pose-aware since it can dynamically predict the joint weights within each body part based on the input pose, and then construct a shared latent space for each body part by feature pooling. Extensive experiments show that our approach can generate better motion retargeting results both qualitatively and quantitatively than state-of-the-art methods. Moreover, we also show that our framework can generate reasonable results even for a more challenging retargeting scenario, like retargeting between bipedal and quadrupedal skeletons because of the body part retargeting strategy and PAN. Our code is publicly available.
Spatial-Temporal Gating-Adjacency GCN for Human Motion Prediction
Mar 03, 2022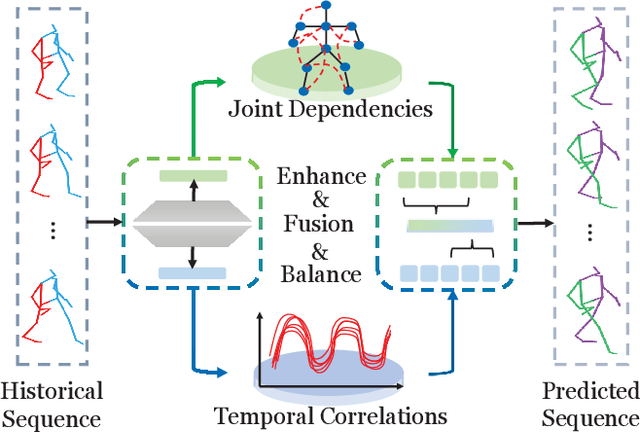
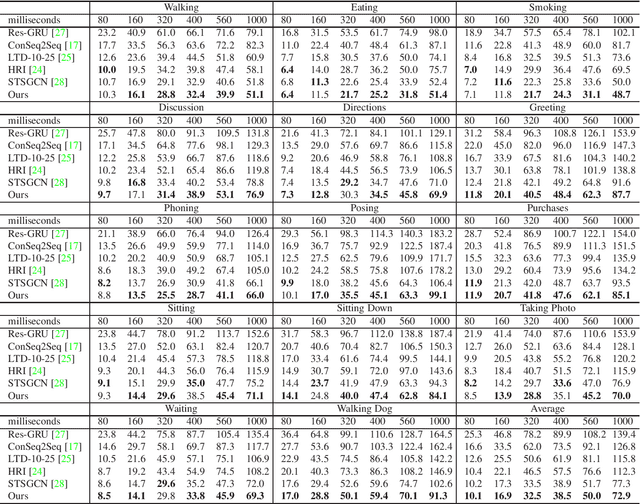
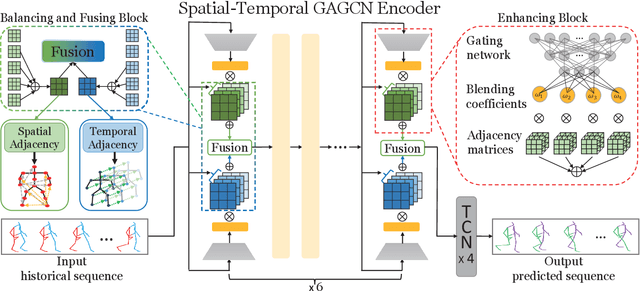
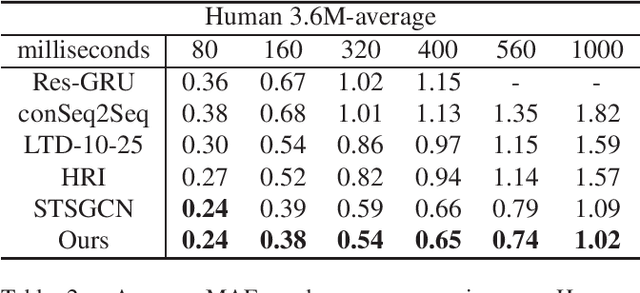
Predicting future motion based on historical motion sequence is a fundamental problem in computer vision, and it has wide applications in autonomous driving and robotics. Some recent works have shown that Graph Convolutional Networks(GCN) are instrumental in modeling the relationship between different joints. However, considering the variants and diverse action types in human motion data, the cross-dependency of the spatial-temporal relationships will be difficult to depict due to the decoupled modeling strategy, which may also exacerbate the problem of insufficient generalization. Therefore, we propose the Spatial-Temporal Gating-Adjacency GCN(GAGCN) to learn the complex spatial-temporal dependencies over diverse action types. Specifically, we adopt gating networks to enhance the generalization of GCN via the trainable adaptive adjacency matrix obtained by blending the candidate spatial-temporal adjacency matrices. Moreover, GAGCN addresses the cross-dependency of space and time by balancing the weights of spatial-temporal modeling and fusing the decoupled spatial-temporal features. Extensive experiments on Human 3.6M, AMASS, and 3DPW demonstrate that GAGCN achieves state-of-the-art performance in both short-term and long-term predictions. Our code will be released in the future.
Towards Fine-grained 3D Face Dense Registration: An Optimal Dividing and Diffusing Method
Sep 23, 2021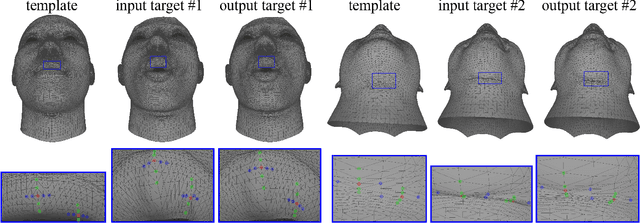
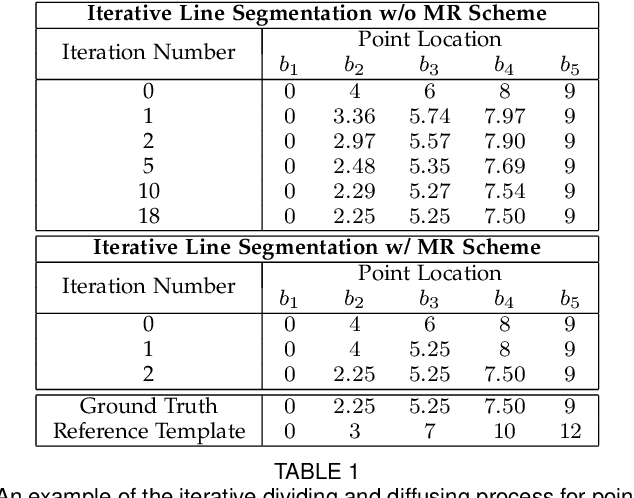
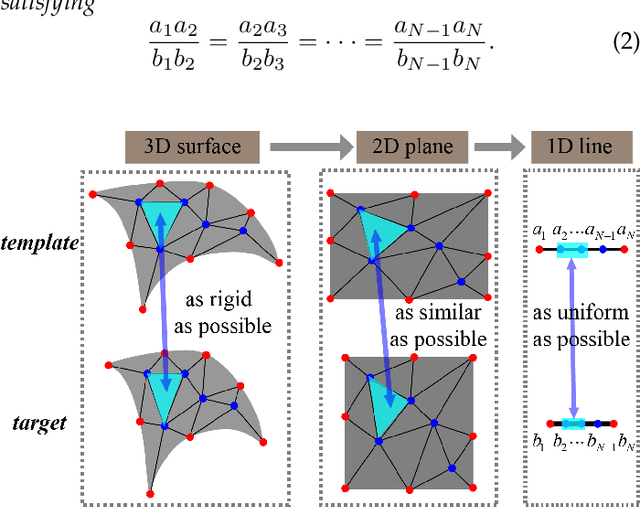

Dense vertex-to-vertex correspondence between 3D faces is a fundamental and challenging issue for 3D&2D face analysis. While the sparse landmarks have anatomically ground-truth correspondence, the dense vertex correspondences on most facial regions are unknown. In this view, the current literatures commonly result in reasonable but diverse solutions, which deviate from the optimum to the 3D face dense registration problem. In this paper, we revisit dense registration by a dimension-degraded problem, i.e. proportional segmentation of a line, and employ an iterative dividing and diffusing method to reach the final solution uniquely. This method is then extended to 3D surface by formulating a local registration problem for dividing and a linear least-square problem for diffusing, with constraints on fixed features. On this basis, we further propose a multi-resolution algorithm to accelerate the computational process. The proposed method is linked to a novel local scaling metric, where we illustrate the physical meaning as smooth rearrangement for local cells of 3D facial shapes. Extensive experiments on public datasets demonstrate the effectiveness of the proposed method in various aspects. Generally, the proposed method leads to coherent local registrations and elegant mesh grid routines for fine-grained 3D face dense registrations, which benefits many downstream applications significantly. It can also be applied to dense correspondence for other format of data which are not limited to face. The core code will be publicly available at https://github.com/NaughtyZZ/3D_face_dense_registration.
3D-TalkEmo: Learning to Synthesize 3D Emotional Talking Head
Apr 25, 2021
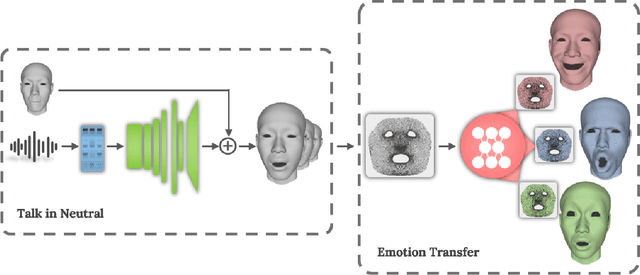


Impressive progress has been made in audio-driven 3D facial animation recently, but synthesizing 3D talking-head with rich emotion is still unsolved. This is due to the lack of 3D generative models and available 3D emotional dataset with synchronized audios. To address this, we introduce 3D-TalkEmo, a deep neural network that generates 3D talking head animation with various emotions. We also create a large 3D dataset with synchronized audios and videos, rich corpus, as well as various emotion states of different persons with the sophisticated 3D face reconstruction methods. In the emotion generation network, we propose a novel 3D face representation structure - geometry map by classical multi-dimensional scaling analysis. It maps the coordinates of vertices on a 3D face to a canonical image plane, while preserving the vertex-to-vertex geodesic distance metric in a least-square sense. This maintains the adjacency relationship of each vertex and holds the effective convolutional structure for the 3D facial surface. Taking a neutral 3D mesh and a speech signal as inputs, the 3D-TalkEmo is able to generate vivid facial animations. Moreover, it provides access to change the emotion state of the animated speaker. We present extensive quantitative and qualitative evaluation of our method, in addition to user studies, demonstrating the generated talking-heads of significantly higher quality compared to previous state-of-the-art methods.
Multiscale Mesh Deformation Component Analysis with Attention-based Autoencoders
Dec 04, 2020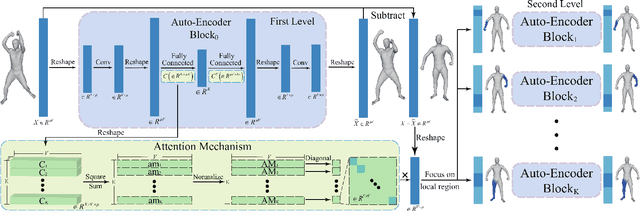
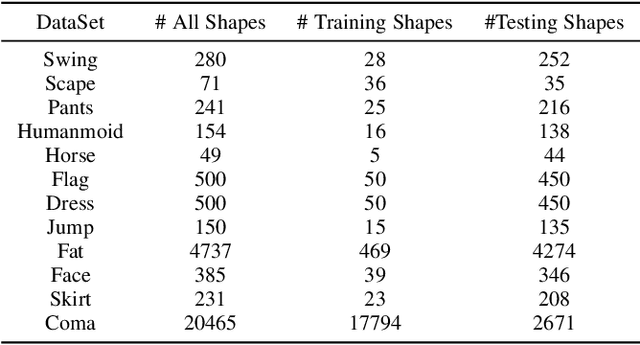

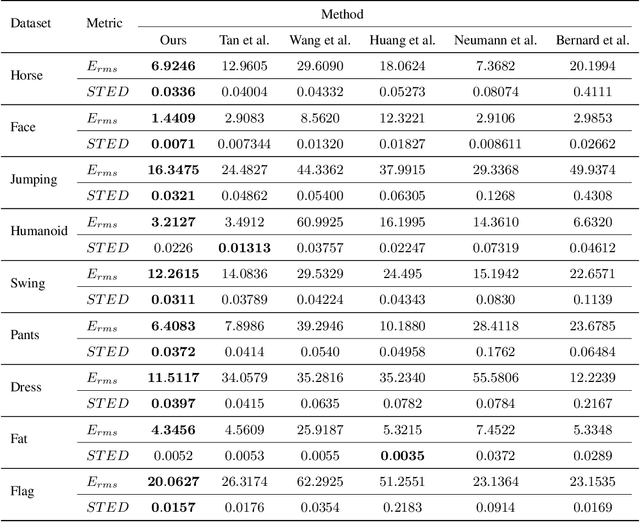
Deformation component analysis is a fundamental problem in geometry processing and shape understanding. Existing approaches mainly extract deformation components in local regions at a similar scale while deformations of real-world objects are usually distributed in a multi-scale manner. In this paper, we propose a novel method to exact multiscale deformation components automatically with a stacked attention-based autoencoder. The attention mechanism is designed to learn to softly weight multi-scale deformation components in active deformation regions, and the stacked attention-based autoencoder is learned to represent the deformation components at different scales. Quantitative and qualitative evaluations show that our method outperforms state-of-the-art methods. Furthermore, with the multiscale deformation components extracted by our method, the user can edit shapes in a coarse-to-fine fashion which facilitates effective modeling of new shapes.