 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabel-Occurrence-Balanced Mixup for Long-tailed Recognition
Oct 11, 2021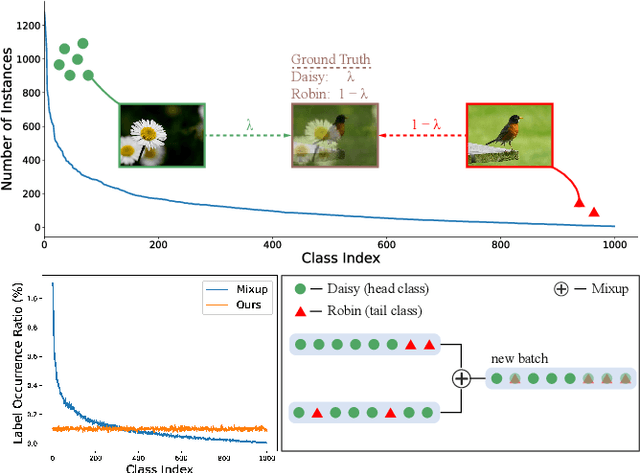
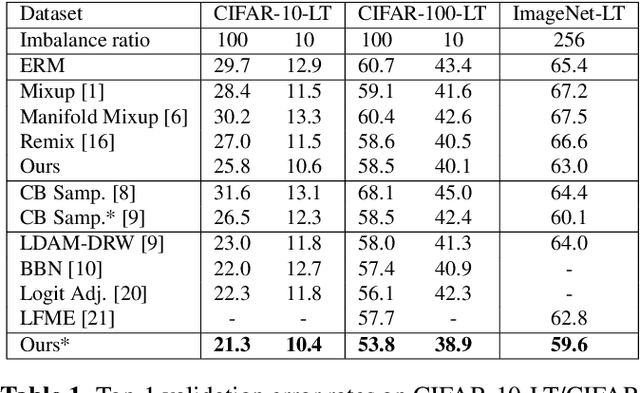
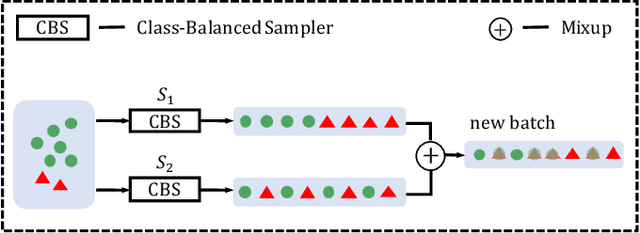
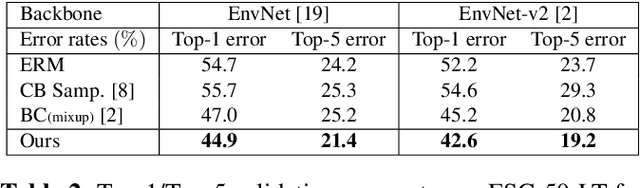
Mixup is a popular data augmentation method, with many variants subsequently proposed. These methods mainly create new examples via convex combination of random data pairs and their corresponding one-hot labels. However, most of them adhere to a random sampling and mixing strategy, without considering the frequency of label occurrence in the mixing process. When applying mixup to long-tailed data, a label suppression issue arises, where the frequency of label occurrence for each class is imbalanced and most of the new examples will be completely or partially assigned with head labels. The suppression effect may further aggravate the problem of data imbalance and lead to a poor performance on tail classes. To address this problem, we propose Label-Occurrence-Balanced Mixup to augment data while keeping the label occurrence for each class statistically balanced. In a word, we employ two independent class-balanced samplers to select data pairs and mix them to generate new data. We test our method on several long-tailed vision and sound recognition benchmarks. Experimental results show that our method significantly promotes the adaptability of mixup method to imbalanced data and achieves superior performance compared with state-of-the-art long-tailed learning methods.
RSDet++: Point-based Modulated Loss for More Accurate Rotated Object Detection
Sep 24, 2021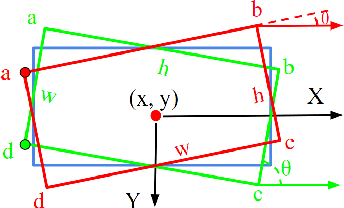
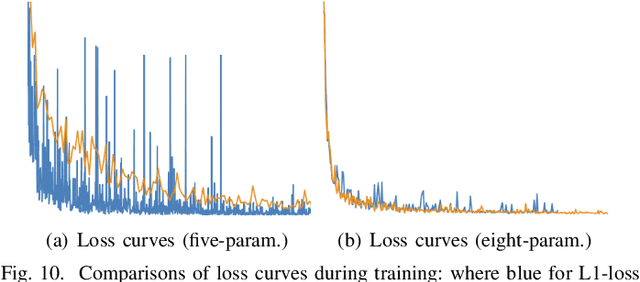

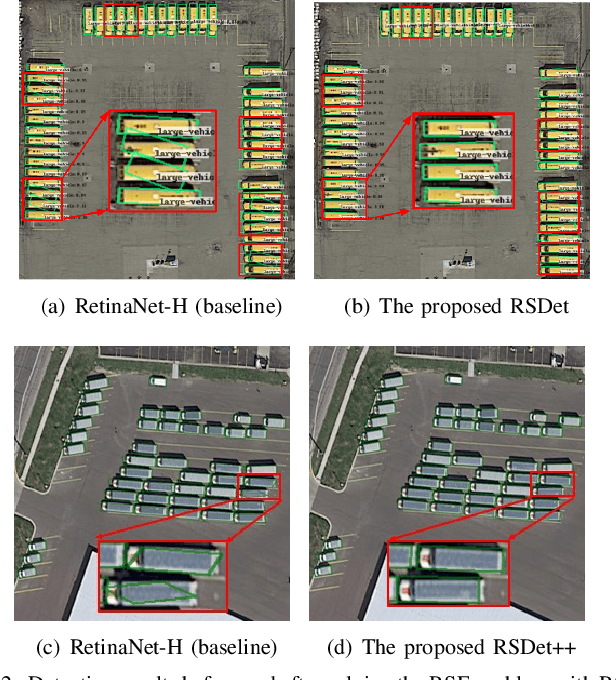
We classify the discontinuity of loss in both five-param and eight-param rotated object detection methods as rotation sensitivity error (RSE) which will result in performance degeneration. We introduce a novel modulated rotation loss to alleviate the problem and propose a rotation sensitivity detection network (RSDet) which is consists of an eight-param single-stage rotated object detector and the modulated rotation loss. Our proposed RSDet has several advantages: 1) it reformulates the rotated object detection problem as predicting the corners of objects while most previous methods employ a five-para-based regression method with different measurement units. 2) modulated rotation loss achieves consistent improvement on both five-param and eight-param rotated object detection methods by solving the discontinuity of loss. To further improve the accuracy of our method on objects smaller than 10 pixels, we introduce a novel RSDet++ which is consists of a point-based anchor-free rotated object detector and a modulated rotation loss. Extensive experiments demonstrate the effectiveness of both RSDet and RSDet++, which achieve competitive results on rotated object detection in the challenging benchmarks DOTA1.0, DOTA1.5, and DOTA2.0. We hope the proposed method can provide a new perspective for designing algorithms to solve rotated object detection and pay more attention to tiny objects. The codes and models are available at: https://github.com/yangxue0827/RotationDetection.
Towards Fine-grained 3D Face Dense Registration: An Optimal Dividing and Diffusing Method
Sep 23, 2021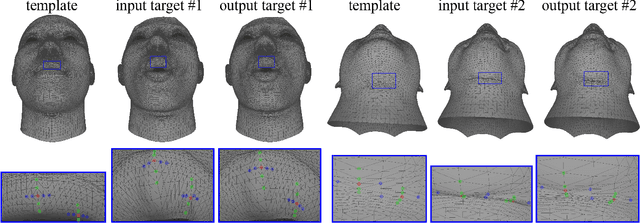
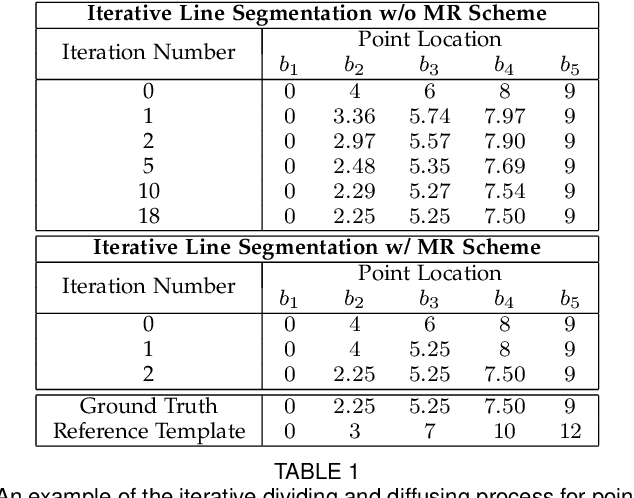
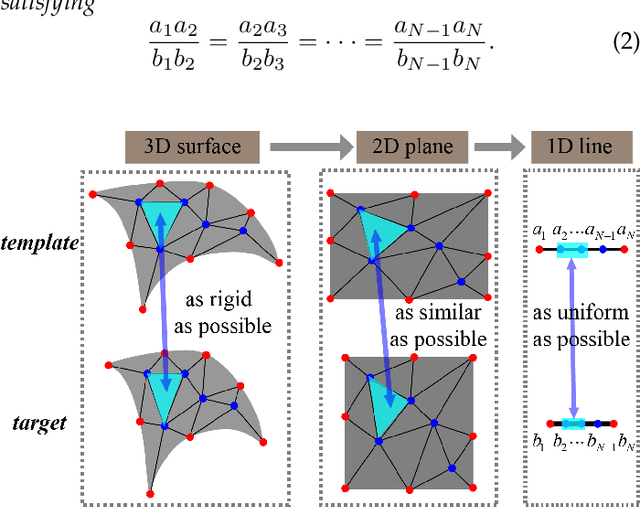

Dense vertex-to-vertex correspondence between 3D faces is a fundamental and challenging issue for 3D&2D face analysis. While the sparse landmarks have anatomically ground-truth correspondence, the dense vertex correspondences on most facial regions are unknown. In this view, the current literatures commonly result in reasonable but diverse solutions, which deviate from the optimum to the 3D face dense registration problem. In this paper, we revisit dense registration by a dimension-degraded problem, i.e. proportional segmentation of a line, and employ an iterative dividing and diffusing method to reach the final solution uniquely. This method is then extended to 3D surface by formulating a local registration problem for dividing and a linear least-square problem for diffusing, with constraints on fixed features. On this basis, we further propose a multi-resolution algorithm to accelerate the computational process. The proposed method is linked to a novel local scaling metric, where we illustrate the physical meaning as smooth rearrangement for local cells of 3D facial shapes. Extensive experiments on public datasets demonstrate the effectiveness of the proposed method in various aspects. Generally, the proposed method leads to coherent local registrations and elegant mesh grid routines for fine-grained 3D face dense registrations, which benefits many downstream applications significantly. It can also be applied to dense correspondence for other format of data which are not limited to face. The core code will be publicly available at https://github.com/NaughtyZZ/3D_face_dense_registration.
Balanced Knowledge Distillation for Long-tailed Learning
Apr 21, 2021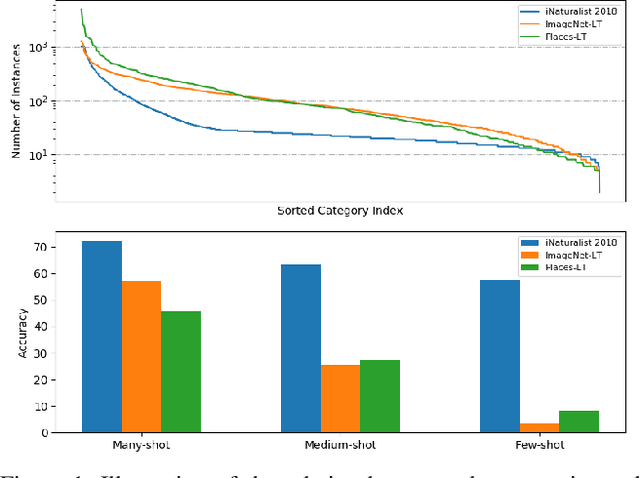
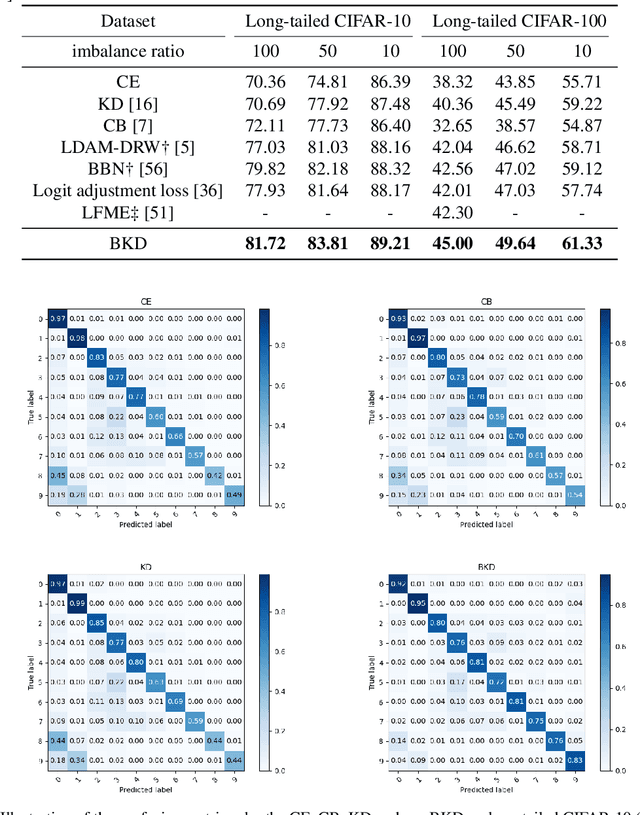
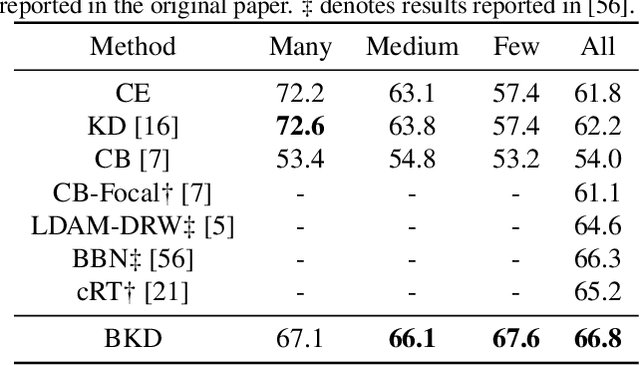
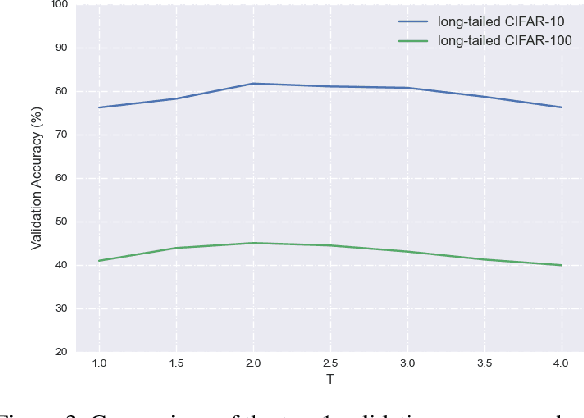
Deep models trained on long-tailed datasets exhibit unsatisfactory performance on tail classes. Existing methods usually modify the classification loss to increase the learning focus on tail classes, which unexpectedly sacrifice the performance on head classes. In fact, this scheme leads to a contradiction between the two goals of long-tailed learning, i.e., learning generalizable representations and facilitating learning for tail classes. In this work, we explore knowledge distillation in long-tailed scenarios and propose a novel distillation framework, named Balanced Knowledge Distillation (BKD), to disentangle the contradiction between the two goals and achieve both simultaneously. Specifically, given a vanilla teacher model, we train the student model by minimizing the combination of an instance-balanced classification loss and a class-balanced distillation loss. The former benefits from the sample diversity and learns generalizable representation, while the latter considers the class priors and facilitates learning mainly for tail classes. The student model trained with BKD obtains significant performance gain even compared with its teacher model. We conduct extensive experiments on several long-tailed benchmark datasets and demonstrate that the proposed BKD is an effective knowledge distillation framework in long-tailed scenarios, as well as a new state-of-the-art method for long-tailed learning. Code is available at https://github.com/EricZsy/BalancedKnowledgeDistillation .
Progressive Bilateral-Context Driven Model for Post-Processing Person Re-Identification
Sep 07, 2020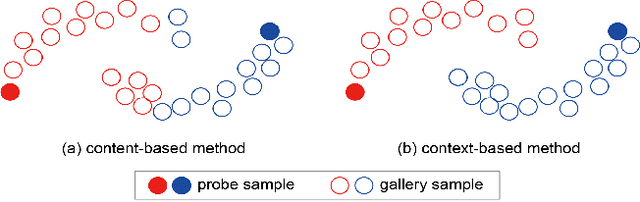
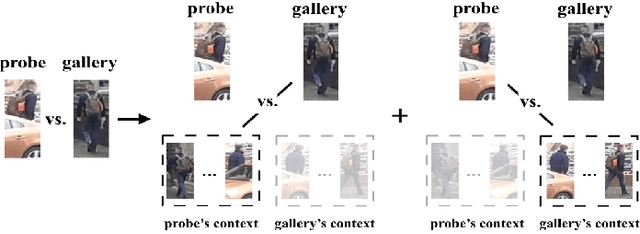

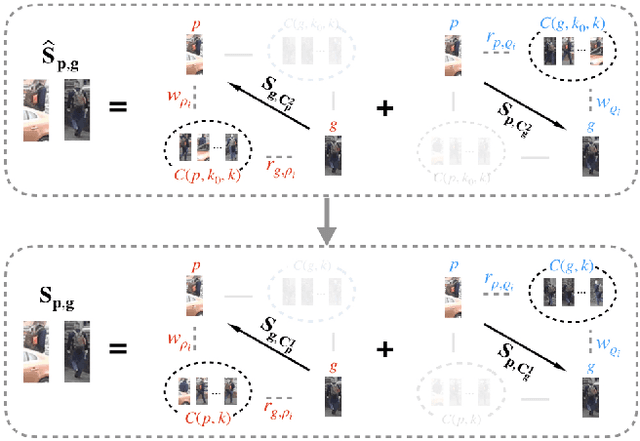
Most existing person re-identification methods compute pairwise similarity by extracting robust visual features and learning the discriminative metric. Owing to visual ambiguities, these content-based methods that determine the pairwise relationship only based on the similarity between them, inevitably produce a suboptimal ranking list. Instead, the pairwise similarity can be estimated more accurately along the geodesic path of the underlying data manifold by exploring the rich contextual information of the sample. In this paper, we propose a lightweight post-processing person re-identification method in which the pairwise measure is determined by the relationship between the sample and the counterpart's context in an unsupervised way. We translate the point-to-point comparison into the bilateral point-to-set comparison. The sample's context is composed of its neighbor samples with two different definition ways: the first order context and the second order context, which are used to compute the pairwise similarity in sequence, resulting in a progressive post-processing model. The experiments on four large-scale person re-identification benchmark datasets indicate that (1) the proposed method can consistently achieve higher accuracies by serving as a post-processing procedure after the content-based person re-identification methods, showing its state-of-the-art results, (2) the proposed lightweight method only needs about 6 milliseconds for optimizing the ranking results of one sample, showing its high-efficiency. Code is available at: https://github.com/123ci/PBCmodel.
PCA-SRGAN: Incremental Orthogonal Projection Discrimination for Face Super-resolution
May 01, 2020

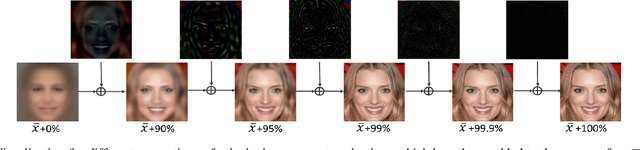
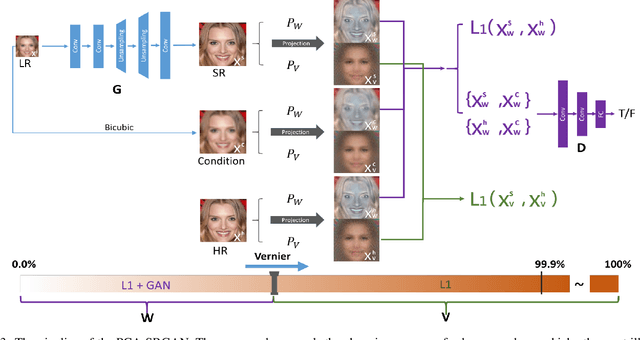
Generative Adversarial Networks (GAN) have been employed for face super resolution but they bring distorted facial details easily and still have weakness on recovering realistic texture. To further improve the performance of GAN based models on super-resolving face images, we propose PCA-SRGAN which pays attention to the cumulative discrimination in the orthogonal projection space spanned by PCA projection matrix of face data. By feeding the principal component projections ranging from structure to details into the discriminator, the discrimination difficulty will be greatly alleviated and the generator can be enhanced to reconstruct clearer contour and finer texture, helpful to achieve the high perception and low distortion eventually. This incremental orthogonal projection discrimination has ensured a precise optimization procedure from coarse to fine and avoids the dependence on the perceptual regularization. We conduct experiments on CelebA and FFHQ face datasets. The qualitative visual effect and quantitative evaluation have demonstrated the overwhelming performance of our model over related works.
Identification of splicing edges in tampered image based on Dichromatic Reflection Model
Apr 09, 2020Imaging is a sophisticated process combining a plenty of photovoltaic conversions, which lead to some spectral signatures beyond visual perception in the final images. Any manipulation against an original image will destroy these signatures and inevitably leave some traces in the final forgery. Therefore we present a novel optic-physical method to discriminate splicing edges from natural edges in a tampered image. First, we transform the forensic image from RGB into color space of S and o1o2. Then on the assumption of Dichromatic Reflection Model, edges in the image are discovered by composite gradient and classified into different types based on their different photometric properties. Finally, splicing edges are reserved against natural ones by a simple logical algorithm. Experiment results show the efficacy of the proposed method.
Learning Modulated Loss for Rotated Object Detection
Dec 20, 2019

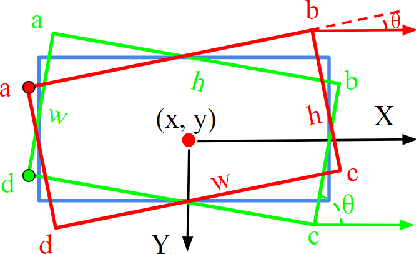

Popular rotated detection methods usually use five parameters (coordinates of the central point, width, height, and rotation angle) to describe the rotated bounding box and l1-loss as the loss function. In this paper, we argue that the aforementioned integration can cause training instability and performance degeneration, due to the loss discontinuity resulted from the inherent periodicity of angles and the associated sudden exchange of width and height. This problem is further pronounced given the regression inconsistency among five parameters with different measurement units. We refer to the above issues as rotation sensitivity error (RSE) and propose a modulated rotation loss to dismiss the loss discontinuity. Our new loss is combined with the eight-parameter regression to further solve the problem of inconsistent parameter regression. Experiments show the state-of-art performances of our method on the public aerial image benchmark DOTA and UCAS-AOD. Its generalization abilities are also verified on ICDAR2015, HRSC2016, and FDDB. Qualitative improvements can be seen in Fig 1, and the source code will be released with the publication of the paper.
Key Person Aided Re-identification in Partially Ordered Pedestrian Set
May 25, 2018
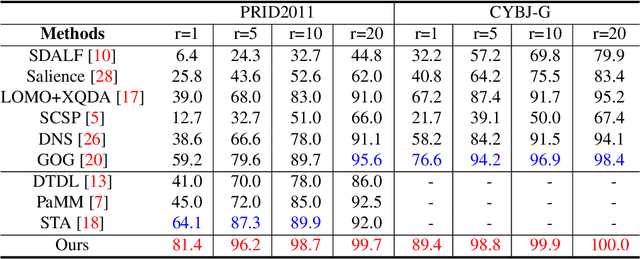
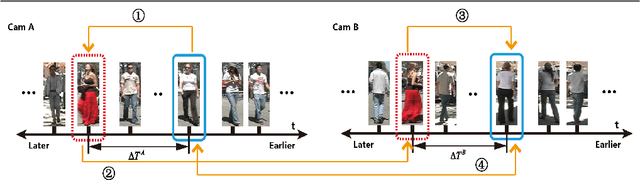

Ideally person re-identification seeks for perfect feature representation and metric model that re-identify all various pedestrians well in non-overlapping views at different locations with different camera configurations, which is very challenging. However, in most pedestrian sets, there always are some outstanding persons who are relatively easy to re-identify. Inspired by the existence of such data division, we propose a novel key person aided person re-identification framework based on the re-defined partially ordered pedestrian sets. The outstanding persons, namely "key persons", are selected by the K-nearest neighbor based saliency measurement. The partial order defined by pedestrian entering time in surveillance associates the key persons with the query person temporally and helps to locate the possible candidates. Experiments conducted on two video datasets show that the proposed key person aided framework outperforms the state-of-the-art methods and improves the matching accuracy greatly at all ranks.