 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBalanced Knowledge Distillation for Long-tailed Learning
Apr 21, 2021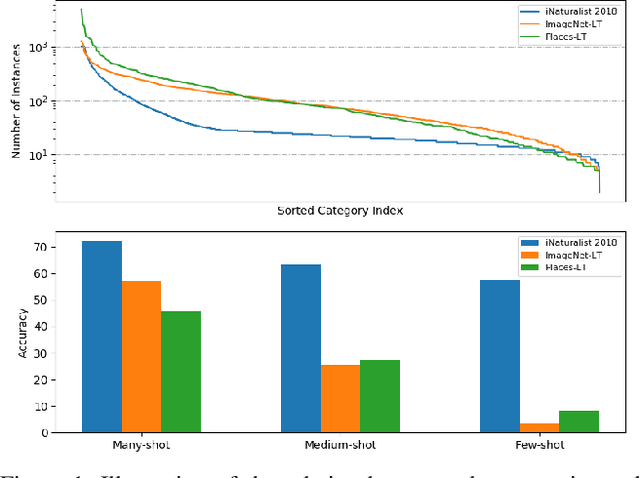
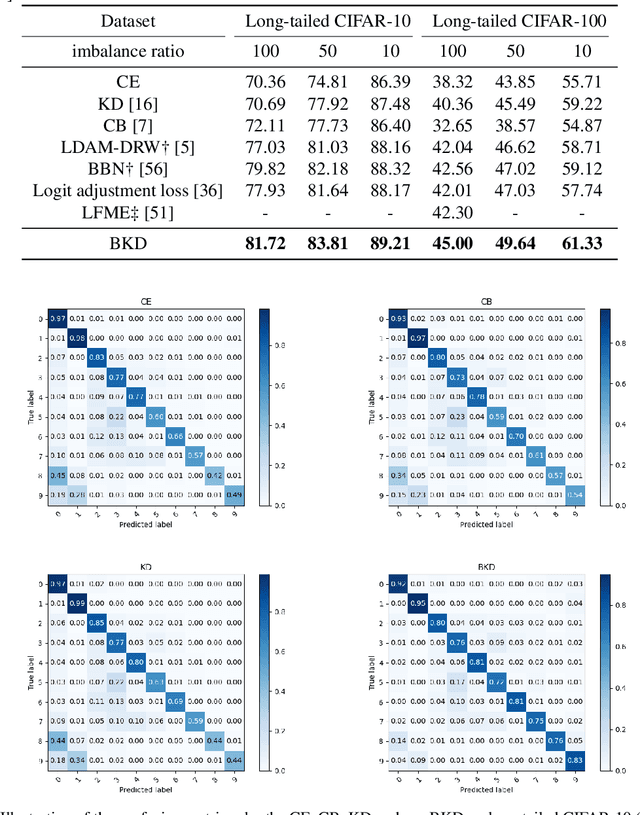
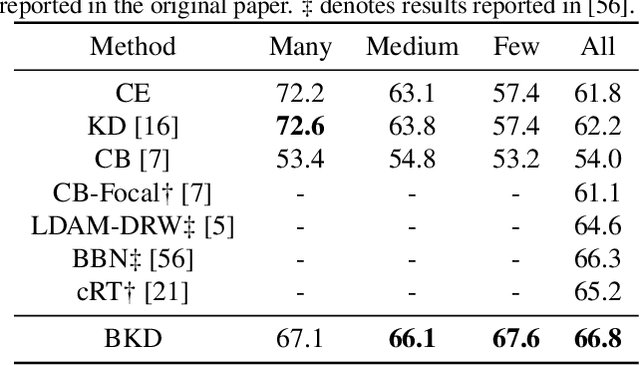
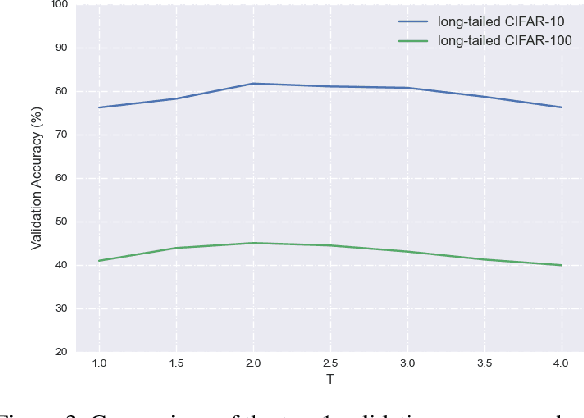
Deep models trained on long-tailed datasets exhibit unsatisfactory performance on tail classes. Existing methods usually modify the classification loss to increase the learning focus on tail classes, which unexpectedly sacrifice the performance on head classes. In fact, this scheme leads to a contradiction between the two goals of long-tailed learning, i.e., learning generalizable representations and facilitating learning for tail classes. In this work, we explore knowledge distillation in long-tailed scenarios and propose a novel distillation framework, named Balanced Knowledge Distillation (BKD), to disentangle the contradiction between the two goals and achieve both simultaneously. Specifically, given a vanilla teacher model, we train the student model by minimizing the combination of an instance-balanced classification loss and a class-balanced distillation loss. The former benefits from the sample diversity and learns generalizable representation, while the latter considers the class priors and facilitates learning mainly for tail classes. The student model trained with BKD obtains significant performance gain even compared with its teacher model. We conduct extensive experiments on several long-tailed benchmark datasets and demonstrate that the proposed BKD is an effective knowledge distillation framework in long-tailed scenarios, as well as a new state-of-the-art method for long-tailed learning. Code is available at https://github.com/EricZsy/BalancedKnowledgeDistillation .
Progressive Bilateral-Context Driven Model for Post-Processing Person Re-Identification
Sep 07, 2020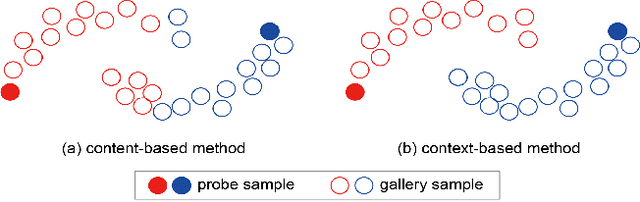
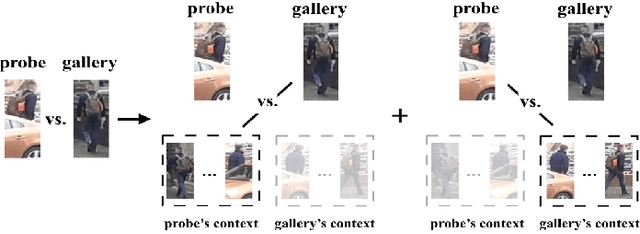

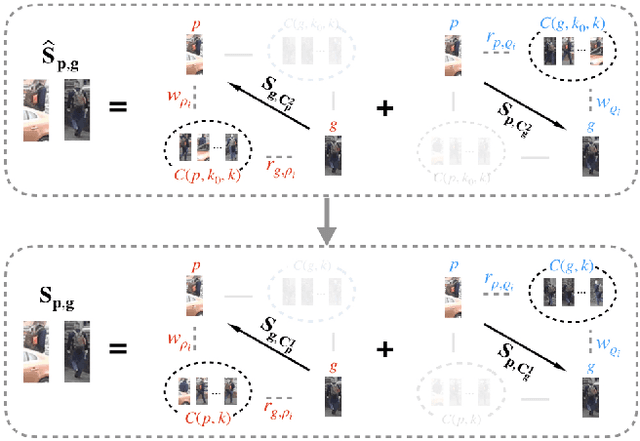
Most existing person re-identification methods compute pairwise similarity by extracting robust visual features and learning the discriminative metric. Owing to visual ambiguities, these content-based methods that determine the pairwise relationship only based on the similarity between them, inevitably produce a suboptimal ranking list. Instead, the pairwise similarity can be estimated more accurately along the geodesic path of the underlying data manifold by exploring the rich contextual information of the sample. In this paper, we propose a lightweight post-processing person re-identification method in which the pairwise measure is determined by the relationship between the sample and the counterpart's context in an unsupervised way. We translate the point-to-point comparison into the bilateral point-to-set comparison. The sample's context is composed of its neighbor samples with two different definition ways: the first order context and the second order context, which are used to compute the pairwise similarity in sequence, resulting in a progressive post-processing model. The experiments on four large-scale person re-identification benchmark datasets indicate that (1) the proposed method can consistently achieve higher accuracies by serving as a post-processing procedure after the content-based person re-identification methods, showing its state-of-the-art results, (2) the proposed lightweight method only needs about 6 milliseconds for optimizing the ranking results of one sample, showing its high-efficiency. Code is available at: https://github.com/123ci/PBCmodel.
PCA-SRGAN: Incremental Orthogonal Projection Discrimination for Face Super-resolution
May 01, 2020

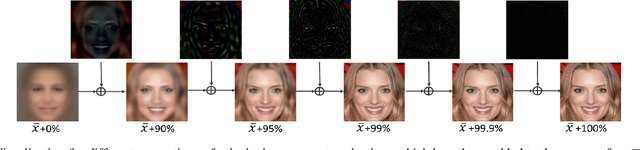
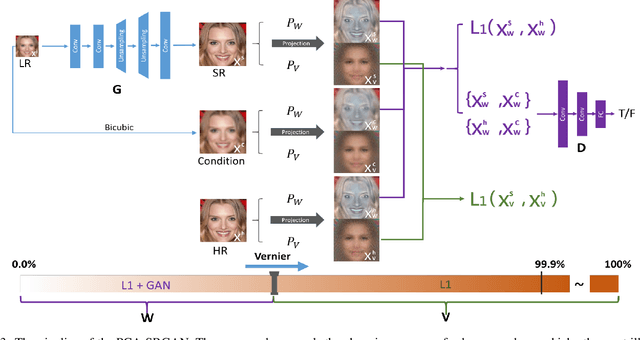
Generative Adversarial Networks (GAN) have been employed for face super resolution but they bring distorted facial details easily and still have weakness on recovering realistic texture. To further improve the performance of GAN based models on super-resolving face images, we propose PCA-SRGAN which pays attention to the cumulative discrimination in the orthogonal projection space spanned by PCA projection matrix of face data. By feeding the principal component projections ranging from structure to details into the discriminator, the discrimination difficulty will be greatly alleviated and the generator can be enhanced to reconstruct clearer contour and finer texture, helpful to achieve the high perception and low distortion eventually. This incremental orthogonal projection discrimination has ensured a precise optimization procedure from coarse to fine and avoids the dependence on the perceptual regularization. We conduct experiments on CelebA and FFHQ face datasets. The qualitative visual effect and quantitative evaluation have demonstrated the overwhelming performance of our model over related works.
Key Person Aided Re-identification in Partially Ordered Pedestrian Set
May 25, 2018
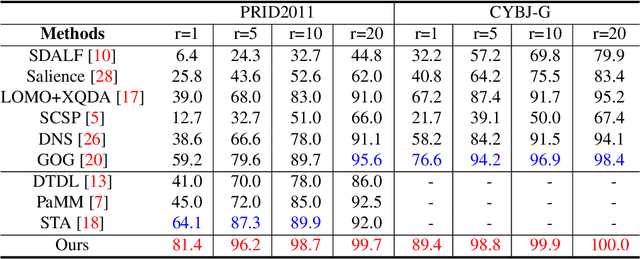
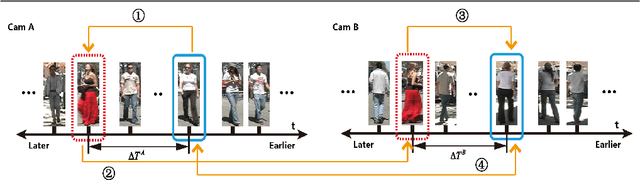

Ideally person re-identification seeks for perfect feature representation and metric model that re-identify all various pedestrians well in non-overlapping views at different locations with different camera configurations, which is very challenging. However, in most pedestrian sets, there always are some outstanding persons who are relatively easy to re-identify. Inspired by the existence of such data division, we propose a novel key person aided person re-identification framework based on the re-defined partially ordered pedestrian sets. The outstanding persons, namely "key persons", are selected by the K-nearest neighbor based saliency measurement. The partial order defined by pedestrian entering time in surveillance associates the key persons with the query person temporally and helps to locate the possible candidates. Experiments conducted on two video datasets show that the proposed key person aided framework outperforms the state-of-the-art methods and improves the matching accuracy greatly at all ranks.