 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffStyle3D: Consistent 3D Gaussian Stylization via Attention Optimization
Jan 27, 20263D style transfer enables the creation of visually expressive 3D content, enriching the visual appearance of 3D scenes and objects. However, existing VGG- and CLIP-based methods struggle to model multi-view consistency within the model itself, while diffusion-based approaches can capture such consistency but rely on denoising directions, leading to unstable training. To address these limitations, we propose DiffStyle3D, a novel diffusion-based paradigm for 3DGS style transfer that directly optimizes in the latent space. Specifically, we introduce an Attention-Aware Loss that performs style transfer by aligning style features in the self-attention space, while preserving original content through content feature alignment. Inspired by the geometric invariance of 3D stylization, we propose a Geometry-Guided Multi-View Consistency method that integrates geometric information into self-attention to enable cross-view correspondence modeling. Based on geometric information, we additionally construct a geometry-aware mask to prevent redundant optimization in overlapping regions across views, which further improves multi-view consistency. Extensive experiments show that DiffStyle3D outperforms state-of-the-art methods, achieving higher stylization quality and visual realism.
Semi-supervised Text-based Person Search
Apr 28, 2024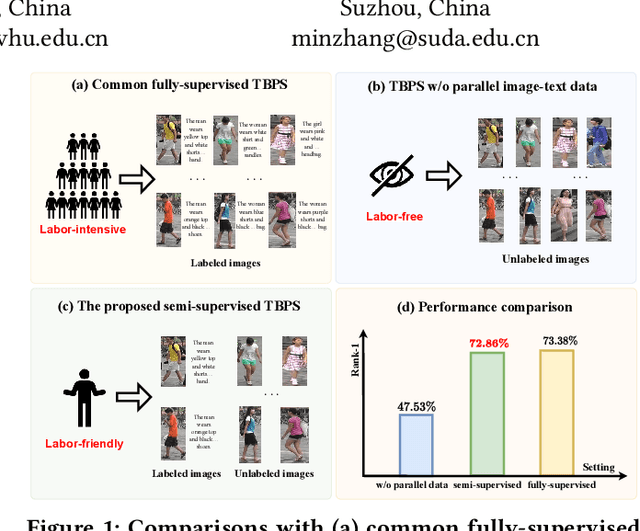
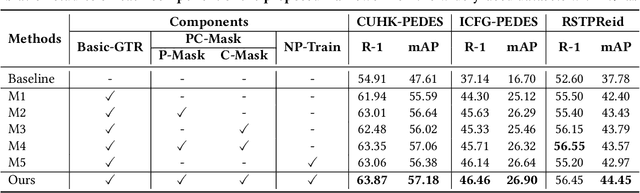
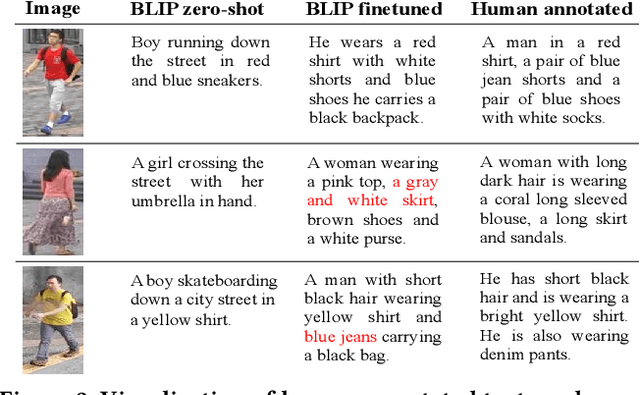
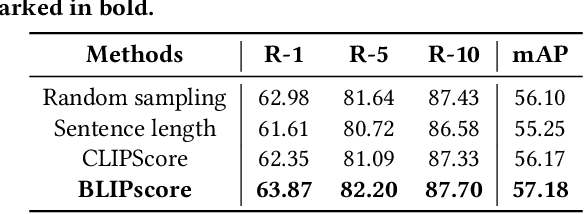
Text-based person search (TBPS) aims to retrieve images of a specific person from a large image gallery based on a natural language description. Existing methods rely on massive annotated image-text data to achieve satisfactory performance in fully-supervised learning. It poses a significant challenge in practice, as acquiring person images from surveillance videos is relatively easy, while obtaining annotated texts is challenging. The paper undertakes a pioneering initiative to explore TBPS under the semi-supervised setting, where only a limited number of person images are annotated with textual descriptions while the majority of images lack annotations. We present a two-stage basic solution based on generation-then-retrieval for semi-supervised TBPS. The generation stage enriches annotated data by applying an image captioning model to generate pseudo-texts for unannotated images. Later, the retrieval stage performs fully-supervised retrieval learning using the augmented data. Significantly, considering the noise interference of the pseudo-texts on retrieval learning, we propose a noise-robust retrieval framework that enhances the ability of the retrieval model to handle noisy data. The framework integrates two key strategies: Hybrid Patch-Channel Masking (PC-Mask) to refine the model architecture, and Noise-Guided Progressive Training (NP-Train) to enhance the training process. PC-Mask performs masking on the input data at both the patch-level and the channel-level to prevent overfitting noisy supervision. NP-Train introduces a progressive training schedule based on the noise level of pseudo-texts to facilitate noise-robust learning. Extensive experiments on multiple TBPS benchmarks show that the proposed framework achieves promising performance under the semi-supervised setting.
Progressive Bilateral-Context Driven Model for Post-Processing Person Re-Identification
Sep 07, 2020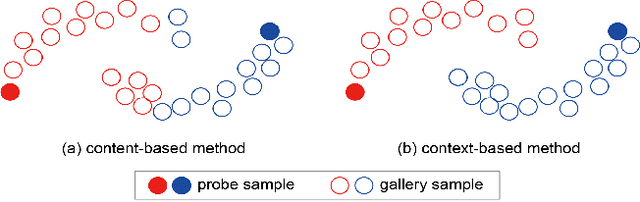
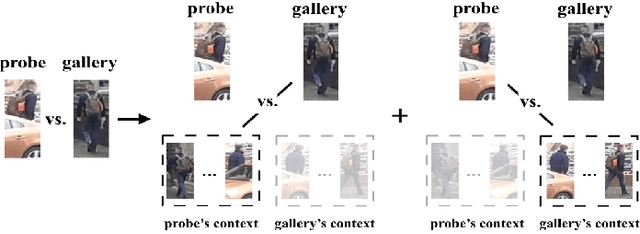

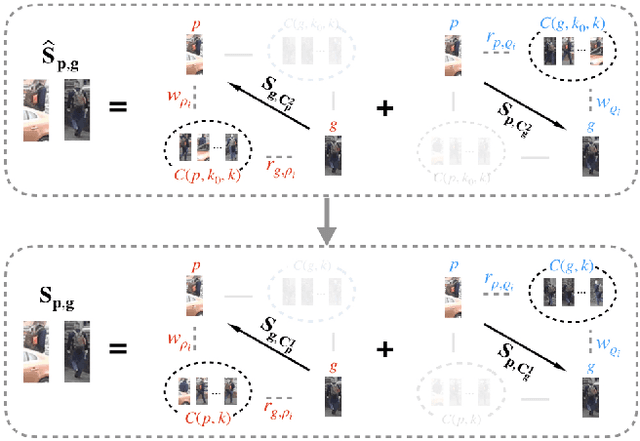
Most existing person re-identification methods compute pairwise similarity by extracting robust visual features and learning the discriminative metric. Owing to visual ambiguities, these content-based methods that determine the pairwise relationship only based on the similarity between them, inevitably produce a suboptimal ranking list. Instead, the pairwise similarity can be estimated more accurately along the geodesic path of the underlying data manifold by exploring the rich contextual information of the sample. In this paper, we propose a lightweight post-processing person re-identification method in which the pairwise measure is determined by the relationship between the sample and the counterpart's context in an unsupervised way. We translate the point-to-point comparison into the bilateral point-to-set comparison. The sample's context is composed of its neighbor samples with two different definition ways: the first order context and the second order context, which are used to compute the pairwise similarity in sequence, resulting in a progressive post-processing model. The experiments on four large-scale person re-identification benchmark datasets indicate that (1) the proposed method can consistently achieve higher accuracies by serving as a post-processing procedure after the content-based person re-identification methods, showing its state-of-the-art results, (2) the proposed lightweight method only needs about 6 milliseconds for optimizing the ranking results of one sample, showing its high-efficiency. Code is available at: https://github.com/123ci/PBCmodel.
PCA-SRGAN: Incremental Orthogonal Projection Discrimination for Face Super-resolution
May 01, 2020

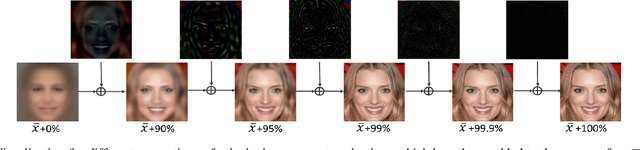
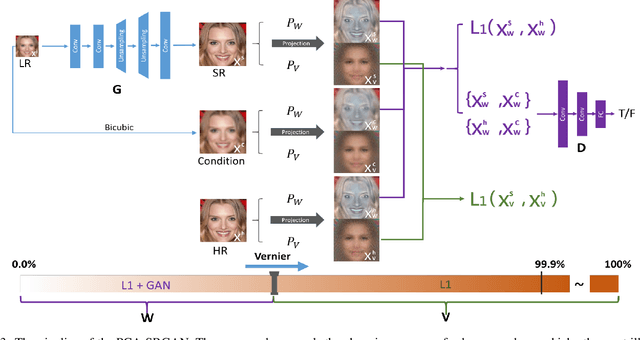
Generative Adversarial Networks (GAN) have been employed for face super resolution but they bring distorted facial details easily and still have weakness on recovering realistic texture. To further improve the performance of GAN based models on super-resolving face images, we propose PCA-SRGAN which pays attention to the cumulative discrimination in the orthogonal projection space spanned by PCA projection matrix of face data. By feeding the principal component projections ranging from structure to details into the discriminator, the discrimination difficulty will be greatly alleviated and the generator can be enhanced to reconstruct clearer contour and finer texture, helpful to achieve the high perception and low distortion eventually. This incremental orthogonal projection discrimination has ensured a precise optimization procedure from coarse to fine and avoids the dependence on the perceptual regularization. We conduct experiments on CelebA and FFHQ face datasets. The qualitative visual effect and quantitative evaluation have demonstrated the overwhelming performance of our model over related works.