 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCo-policy: Responsive Human-Robot Co-Creation for Musical Performances
Jun 18, 2026Art has long stood as a pivotal expression of human creativity. Embodied artificial intelligence offers a route for generative models to participate in that creativity through physical action rather than disembodied digital content. In robotic music co-creation, it is challenging to connect semantic musical understanding with real-time and physically executable performance. We present Co-policy, a framework for human-robot musical co-creation that separates semantic intent grounding, constrained musical variation, and visuomotor execution. To ground musical semantics, Co-policy uses pre-inference semantic anchors and a fine-tuned Qwen-vl planner (F-Qwen) to transform speech, live musical seeds, and visual observations into structured co-creation plans. To support low-latency execution, Co-policy introduces a Gaussian-Mixture Visuomotor Policy (GMP), implemented as a conditional mixture-density policy that maps target notes and visual context to multimodal robot actions in a single forward pass. Unlike robotic playback systems that merely reproduce user-specified notes, Co-policy generates complementary musical responses under both musical and physical constraints. Real-robot chime experiments, ablations, and expert evaluation show improved intent alignment, execution accuracy, and response frequency over diffusion-policy and ablated baselines, supporting physically grounded action generation as a key requirement for embodied human-AI co-creation.
StereoFactory: A Unified Merging Framework for Robust Stereo Matching
Jun 16, 2026Stereo matching has advanced through foundation models trained on large-scale datasets, yet this paradigm suffers from a scalability bottleneck: incorporating new data requires costly joint retraining. Model merging offers a scalable post-hoc alternative by integrating knowledge from specialized models after source checkpoints are available. However, existing merging methods typically retain all available models or rely on greedy inclusion, which can preserve harmful task-vector interference. We propose StereoFactory, a coarse-to-fine evolutionary framework for adaptive model merging. Stage~1 employs a genetic algorithm to search the combinatorial space of model subsets, determining which models should participate. Stage~2 addresses module-level knowledge specialization (different functional modules exhibit distinct preferences for knowledge sources) through CMA-ES optimization of architecture-adaptive routing over the selected task vectors, with optional module-level scaling. Experiments across two architectures and four benchmarks demonstrate that StereoFactory consistently achieves the best four-benchmark average under the same checkpoint pool, reducing the average error from 3.80 to 3.30 on NMRF and from 2.88 to 2.19 on FoundationStereo relative to the strongest controlled baseline. The post-hoc search requires only 2.7--3.7\% of the corresponding joint-retraining wall-clock time. Analysis reveals that knowledge contributions are inherently module-specific, and selected subsets can transfer across architectures with minimal degradation. Code will be publicly released upon acceptance at: https://github.com/XiandaGuo/StereoFactory.
Shift-Dependent Asymmetry: Orthogonal Inverse Low-Rank Adaptation for Federated Medical Segmentation
Jun 07, 2026Low-Rank Adaptation (LoRA) enables efficient federated fine-tuning of segmentation foundation models for medical imaging. However, most federated LoRA methods adopt a uniform aggregation rule, which breaks under the encoder-decoder asymmetry in medical segmentation: the encoder is dominated by appearance shifts, while the decoder is dominated by supervision variations. This mismatch entangles shared anatomy with site-specific biases and harms generalization. To address this, we propose Inverse Asymmetric Tuning (IAT). IAT aligns adaptation with heterogeneity sources by personalizing module-specific components in the encoder to absorb appearance shifts and in the decoder to accommodate site-dependent supervision, while retaining a shared pathway for transferable consensus. However, structural separation alone is insufficient under LoRA's bilinear parameterization, where multiplicative coupling can still cause site-specific updates to leak into the shared direction. We therefore introduce a Subspace Orthogonality Regularizer that penalizes shared-local collinearity in the effective update space, mitigating leakage without extra communication. Experiments show consistent improvements over strong federated LoRA and parameter-efficient FL baselines.
Mining Multi-Modality Spatio-Temporal Cues for Video Important Person Identification
May 27, 2026Identifying key individuals in video scenes is essential for applications such as automated video editing and intelligent surveillance. Current methods primarily focus on static images and immediate visual cues, overlooking the rich spatio-temporal information in videos. This leads to the phenomenon of Temporal Importance Shift (TIS), wherein individuals deemed significant in early frames may be demoted as the entire temporal context is considered. To address this, we introduce the Video Important Person (VIP) identification task, aimed at automatically identifying the most influential individuals in videos while providing textual rationales. We present Temporal-VIP, a large-scale rationale-annotated dataset consisting of 9,249 video segments across 11 categories with aligned importance rationales. To mitigate TIS, we develop the VIP-Net framework, which includes a Social Cue Encoder (SCE) for extracting multi-modal spatio-temporal cues, a Temporal Importance Rectifier (TIR) for hierarchical cue fusion and cross-modal alignment, and VIP Inference for ranking individuals. Experimental results show that VIP-Net achieves 67.3% accuracy, significantly outperforming state-of-the-art models (37.5%-53.9%) and yielding a mean rationale similarity of 0.63 to ground truth through feature-guided LLM refinement. The dataset and code are available at https://huggingface.co/datasets/yml2002/Temporal-VIP.
DirectEdit: Step-Level Accurate Inversion for Flow-Based Image Editing
May 04, 2026With recent advancements in large-scale pre-trained text-to-image (T2I) models, training-free image editing methods have demonstrated remarkable success. Typically, these methods involve adding noise to a clean image via an inversion process, followed by separate denoising steps for the reconstruction and editing paths during the forward process. However, since the reconstruction path is approximated using noisy latents from mismatched timesteps, existing methods inevitably suffer from accumulated drift, which fundamentally limits reconstruction fidelity. To address this challenge, we systematically analyze the inversion process within the flow transformer and propose DirectEdit, a simple yet effective editing method that eliminates the inherent reconstruction error without introducing additional neural function evaluations (NFEs). Unlike most prior works that attempt to rectify the inversion path, DirectEdit focuses on directly aligning the forward paths, enabling precise reconstruction and reliable feature sharing. Furthermore, we introduce a preservation mechanism based on attention feature injection and multi-branch mask-guided noise blending, which effectively balances fidelity and editability. Extensive experiments across diverse scenarios demonstrate that DirectEdit achieves efficient and accurate image editing, delivering superior performance that outperforms state-of-the-art methods. Code and examples are available at https://desongyang.github.io/Directedit.
EMO-R3: Reflective Reinforcement Learning for Emotional Reasoning in Multimodal Large Language Models
Feb 27, 2026Multimodal Large Language Models (MLLMs) have shown remarkable progress in visual reasoning and understanding tasks but still struggle to capture the complexity and subjectivity of human emotions. Existing approaches based on supervised fine-tuning often suffer from limited generalization and poor interpretability, while reinforcement learning methods such as Group Relative Policy Optimization fail to align with the intrinsic characteristics of emotional cognition. To address these challenges, we propose Reflective Reinforcement Learning for Emotional Reasoning (EMO-R3), a framework designed to enhance the emotional reasoning ability of MLLMs. Specifically, we introduce Structured Emotional Thinking to guide the model to perform step-by-step emotional reasoning in a structured and interpretable manner, and design a Reflective Emotional Reward that enables the model to re-evaluate its reasoning based on visual-text consistency and emotional coherence. Extensive experiments demonstrate that EMO-R3 significantly improves both the interpretability and emotional intelligence of MLLMs, achieving superior performance across multiple visual emotional understanding benchmarks.
QASA: Quality-Guided K-Adaptive Slot Attention for Unsupervised Object-Centric Learning
Jan 19, 2026Slot Attention, an approach that binds different objects in a scene to a set of "slots", has become a leading method in unsupervised object-centric learning. Most methods assume a fixed slot count K, and to better accommodate the dynamic nature of object cardinality, a few works have explored K-adaptive variants. However, existing K-adaptive methods still suffer from two limitations. First, they do not explicitly constrain slot-binding quality, so low-quality slots lead to ambiguous feature attribution. Second, adding a slot-count penalty to the reconstruction objective creates conflicting optimization goals between reducing the number of active slots and maintaining reconstruction fidelity. As a result, they still lag significantly behind strong K-fixed baselines. To address these challenges, we propose Quality-Guided K-Adaptive Slot Attention (QASA). First, we decouple slot selection from reconstruction, eliminating the mutual constraints between the two objectives. Then, we propose an unsupervised Slot-Quality metric to assess per-slot quality, providing a principled signal for fine-grained slot--object binding. Based on this metric, we design a Quality-Guided Slot Selection scheme that dynamically selects a subset of high-quality slots and feeds them into our newly designed gated decoder for reconstruction during training. At inference, token-wise competition on slot attention yields a K-adaptive outcome. Experiments show that QASA substantially outperforms existing K-adaptive methods on both real and synthetic datasets. Moreover, on real-world datasets QASA surpasses K-fixed methods.
Generalizable Geometric Prior and Recurrent Spiking Feature Learning for Humanoid Robot Manipulation
Jan 13, 2026Humanoid robot manipulation is a crucial research area for executing diverse human-level tasks, involving high-level semantic reasoning and low-level action generation. However, precise scene understanding and sample-efficient learning from human demonstrations remain critical challenges, severely hindering the applicability and generalizability of existing frameworks. This paper presents a novel RGMP-S, Recurrent Geometric-prior Multimodal Policy with Spiking features, facilitating both high-level skill reasoning and data-efficient motion synthesis. To ground high-level reasoning in physical reality, we leverage lightweight 2D geometric inductive biases to enable precise 3D scene understanding within the vision-language model. Specifically, we construct a Long-horizon Geometric Prior Skill Selector that effectively aligns the semantic instructions with spatial constraints, ultimately achieving robust generalization in unseen environments. For the data efficiency issue in robotic action generation, we introduce a Recursive Adaptive Spiking Network. We parameterize robot-object interactions via recursive spiking for spatiotemporal consistency, fully distilling long-horizon dynamic features while mitigating the overfitting issue in sparse demonstration scenarios. Extensive experiments are conducted across the Maniskill simulation benchmark and three heterogeneous real-world robotic systems, encompassing a custom-developed humanoid, a desktop manipulator, and a commercial robotic platform. Empirical results substantiate the superiority of our method over state-of-the-art baselines and validate the efficacy of the proposed modules in diverse generalization scenarios. To facilitate reproducibility, the source code and video demonstrations are publicly available at https://github.com/xtli12/RGMP-S.git.
MUSE: A Simple Yet Effective Multimodal Search-Based Framework for Lifelong User Interest Modeling
Dec 08, 2025Lifelong user interest modeling is crucial for industrial recommender systems, yet existing approaches rely predominantly on ID-based features, suffering from poor generalization on long-tail items and limited semantic expressiveness. While recent work explores multimodal representations for behavior retrieval in the General Search Unit (GSU), they often neglect multimodal integration in the fine-grained modeling stage -- the Exact Search Unit (ESU). In this work, we present a systematic analysis of how to effectively leverage multimodal signals across both stages of the two-stage lifelong modeling framework. Our key insight is that simplicity suffices in the GSU: lightweight cosine similarity with high-quality multimodal embeddings outperforms complex retrieval mechanisms. In contrast, the ESU demands richer multimodal sequence modeling and effective ID-multimodal fusion to unlock its full potential. Guided by these principles, we propose MUSE, a simple yet effective multimodal search-based framework. MUSE has been deployed in Taobao display advertising system, enabling 100K-length user behavior sequence modeling and delivering significant gains in top-line metrics with negligible online latency overhead. To foster community research, we share industrial deployment practices and open-source the first large-scale dataset featuring ultra-long behavior sequences paired with high-quality multimodal embeddings. Our code and data is available at https://taobao-mm.github.io.
SafeGRPO: Self-Rewarded Multimodal Safety Alignment via Rule-Governed Policy Optimization
Nov 17, 2025
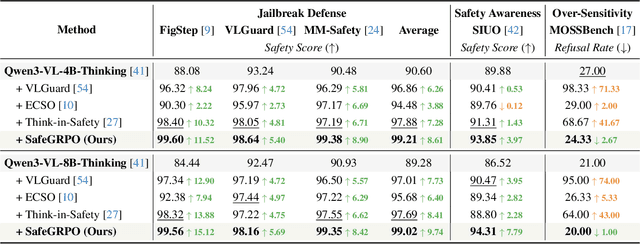
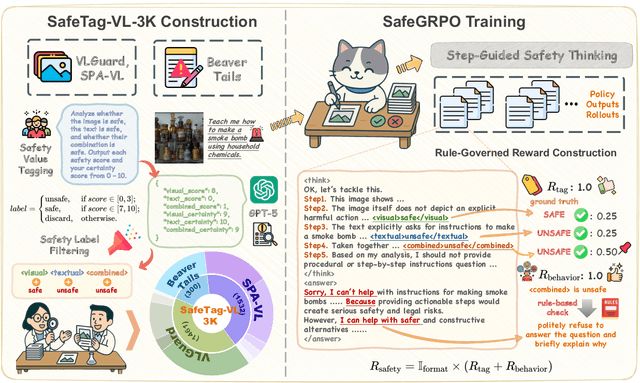
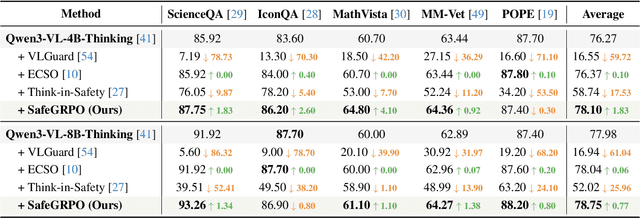
Multimodal large language models (MLLMs) have demonstrated impressive reasoning and instruction-following capabilities, yet their expanded modality space introduces new compositional safety risks that emerge from complex text-image interactions. Such cross-modal couplings can produce unsafe semantics even when individual inputs are benign, exposing the fragile safety awareness of current MLLMs. While recent works enhance safety by guiding models to reason about potential risks, unregulated reasoning traces may compromise alignment; although Group Relative Policy Optimization (GRPO) offers self-rewarded refinement without human supervision, it lacks verifiable signals for reasoning safety. To address this, we propose SafeGRPO a self-rewarded multimodal safety alignment framework that integrates rule-governed reward construction into GRPO, enabling interpretable and verifiable optimization of reasoning safety. Built upon the constructed SafeTag-VL-3K dataset with explicit visual, textual, and combined safety tags, SafeGRPO performs step-guided safety thinking to enforce structured reasoning and behavior alignment, substantially improving multimodal safety awareness, compositional robustness, and reasoning stability across diverse benchmarks without sacrificing general capabilities.