 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBackdoor Cleaning without External Guidance in MLLM Fine-tuning
May 22, 2025Multimodal Large Language Models (MLLMs) are increasingly deployed in fine-tuning-as-a-service (FTaaS) settings, where user-submitted datasets adapt general-purpose models to downstream tasks. This flexibility, however, introduces serious security risks, as malicious fine-tuning can implant backdoors into MLLMs with minimal effort. In this paper, we observe that backdoor triggers systematically disrupt cross-modal processing by causing abnormal attention concentration on non-semantic regions--a phenomenon we term attention collapse. Based on this insight, we propose Believe Your Eyes (BYE), a data filtering framework that leverages attention entropy patterns as self-supervised signals to identify and filter backdoor samples. BYE operates via a three-stage pipeline: (1) extracting attention maps using the fine-tuned model, (2) computing entropy scores and profiling sensitive layers via bimodal separation, and (3) performing unsupervised clustering to remove suspicious samples. Unlike prior defenses, BYE equires no clean supervision, auxiliary labels, or model modifications. Extensive experiments across various datasets, models, and diverse trigger types validate BYE's effectiveness: it achieves near-zero attack success rates while maintaining clean-task performance, offering a robust and generalizable solution against backdoor threats in MLLMs.
CoT-Kinetics: A Theoretical Modeling Assessing LRM Reasoning Process
May 19, 2025Recent Large Reasoning Models significantly improve the reasoning ability of Large Language Models by learning to reason, exhibiting the promising performance in solving complex tasks. LRMs solve tasks that require complex reasoning by explicitly generating reasoning trajectories together with answers. Nevertheless, judging the quality of such an output answer is not easy because only considering the correctness of the answer is not enough and the soundness of the reasoning trajectory part matters as well. Logically, if the soundness of the reasoning part is poor, even if the answer is correct, the confidence of the derived answer should be low. Existing methods did consider jointly assessing the overall output answer by taking into account the reasoning part, however, their capability is still not satisfactory as the causal relationship of the reasoning to the concluded answer cannot properly reflected. In this paper, inspired by classical mechanics, we present a novel approach towards establishing a CoT-Kinetics energy equation. Specifically, our CoT-Kinetics energy equation formulates the token state transformation process, which is regulated by LRM internal transformer layers, as like a particle kinetics dynamics governed in a mechanical field. Our CoT-Kinetics energy assigns a scalar score to evaluate specifically the soundness of the reasoning phase, telling how confident the derived answer could be given the evaluated reasoning. As such, the LRM's overall output quality can be accurately measured, rather than a coarse judgment (e.g., correct or incorrect) anymore.
Embodied Neuromorphic Control Applied on a 7-DOF Robotic Manipulator
Apr 17, 2025



The development of artificial intelligence towards real-time interaction with the environment is a key aspect of embodied intelligence and robotics. Inverse dynamics is a fundamental robotics problem, which maps from joint space to torque space of robotic systems. Traditional methods for solving it rely on direct physical modeling of robots which is difficult or even impossible due to nonlinearity and external disturbance. Recently, data-based model-learning algorithms are adopted to address this issue. However, they often require manual parameter tuning and high computational costs. Neuromorphic computing is inherently suitable to process spatiotemporal features in robot motion control at extremely low costs. However, current research is still in its infancy: existing works control only low-degree-of-freedom systems and lack performance quantification and comparison. In this paper, we propose a neuromorphic control framework to control 7 degree-of-freedom robotic manipulators. We use Spiking Neural Network to leverage the spatiotemporal continuity of the motion data to improve control accuracy, and eliminate manual parameters tuning. We validated the algorithm on two robotic platforms, which reduces torque prediction error by at least 60% and performs a target position tracking task successfully. This work advances embodied neuromorphic control by one step forward from proof of concept to applications in complex real-world tasks.
PRISM: Self-Pruning Intrinsic Selection Method for Training-Free Multimodal Data Selection
Feb 17, 2025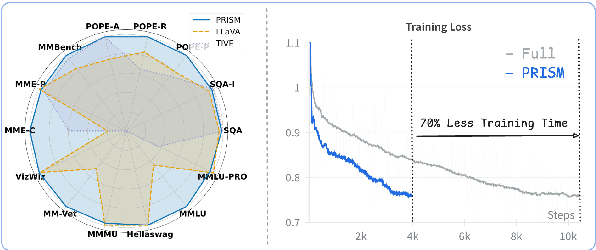
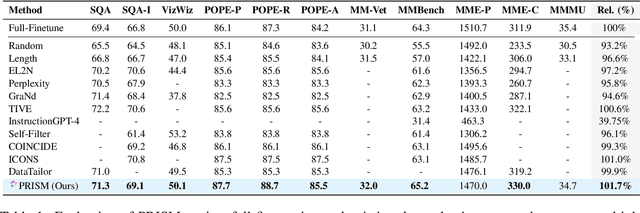
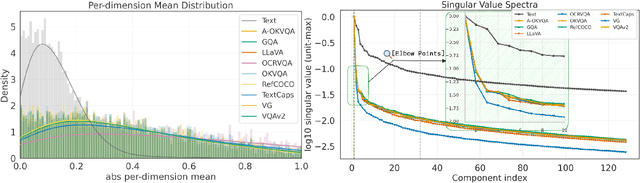
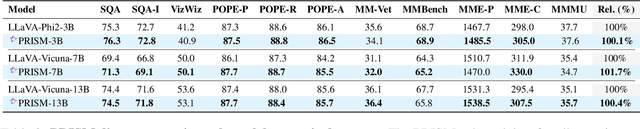
Visual instruction tuning refines pre-trained Multimodal Large Language Models (MLLMs) to enhance their real-world task performance. However, the rapid expansion of visual instruction datasets introduces significant data redundancy, leading to excessive computational costs. Existing data selection methods predominantly rely on proxy models or loss-based metrics, both of which impose substantial computational overheads due to the necessity of model inference and backpropagation. To address this challenge, we propose PRISM, a novel training-free approach for efficient multimodal data selection. Unlike existing methods, PRISM eliminates the reliance on proxy models, warm-up pretraining, and gradient-based optimization. Instead, it leverages Pearson correlation analysis to quantify the intrinsic visual encoding properties of MLLMs, computing a task-specific correlation score to identify high-value instances. This not only enbles data-efficient selection,but maintains the original performance. Empirical evaluations across multiple MLLMs demonstrate that PRISM reduces the overall time required for visual instruction tuning and data selection to just 30% of conventional methods, while surpassing fully fine-tuned models across eight multimodal and three language understanding benchmarks, achieving a 101.7% relative improvement in final performance.
Visual Instruction Tuning with 500x Fewer Parameters through Modality Linear Representation-Steering
Dec 16, 2024



Multimodal Large Language Models (MLLMs) have significantly advanced visual tasks by integrating visual representations into large language models (LLMs). The textual modality, inherited from LLMs, equips MLLMs with abilities like instruction following and in-context learning. In contrast, the visual modality enhances performance in downstream tasks by leveraging rich semantic content, spatial information, and grounding capabilities. These intrinsic modalities work synergistically across various visual tasks. Our research initially reveals a persistent imbalance between these modalities, with text often dominating output generation during visual instruction tuning. This imbalance occurs when using both full fine-tuning and parameter-efficient fine-tuning (PEFT) methods. We then found that re-balancing these modalities can significantly reduce the number of trainable parameters required, inspiring a direction for further optimizing visual instruction tuning. We introduce Modality Linear Representation-Steering (MoReS) to achieve the goal. MoReS effectively re-balances the intrinsic modalities throughout the model, where the key idea is to steer visual representations through linear transformations in the visual subspace across each model layer. To validate our solution, we composed LLaVA Steering, a suite of models integrated with the proposed MoReS method. Evaluation results show that the composed LLaVA Steering models require, on average, 500 times fewer trainable parameters than LoRA needs while still achieving comparable performance across three visual benchmarks and eight visual question-answering tasks. Last, we present the LLaVA Steering Factory, an in-house developed platform that enables researchers to quickly customize various MLLMs with component-based architecture for seamlessly integrating state-of-the-art models, and evaluate their intrinsic modality imbalance.
Stop Reasoning! When Multimodal LLMs with Chain-of-Thought Reasoning Meets Adversarial Images
Feb 22, 2024


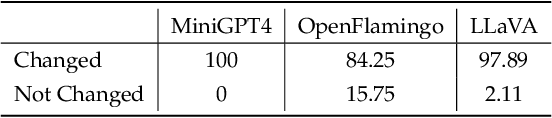
Recently, Multimodal LLMs (MLLMs) have shown a great ability to understand images. However, like traditional vision models, they are still vulnerable to adversarial images. Meanwhile, Chain-of-Thought (CoT) reasoning has been widely explored on MLLMs, which not only improves model's performance, but also enhances model's explainability by giving intermediate reasoning steps. Nevertheless, there is still a lack of study regarding MLLMs' adversarial robustness with CoT and an understanding of what the rationale looks like when MLLMs infer wrong answers with adversarial images. Our research evaluates the adversarial robustness of MLLMs when employing CoT reasoning, finding that CoT marginally improves adversarial robustness against existing attack methods. Moreover, we introduce a novel stop-reasoning attack technique that effectively bypasses the CoT-induced robustness enhancements. Finally, we demonstrate the alterations in CoT reasoning when MLLMs confront adversarial images, shedding light on their reasoning process under adversarial attacks.
Functional Split of In-Network Deep Learning for 6G: A Feasibility Study
Nov 14, 2022



In existing mobile network systems, the data plane (DP) is mainly considered a pipeline consisting of network elements end-to-end forwarding user data traffics. With the rapid maturity of programmable network devices, however, mobile network infrastructure mutates towards a programmable computing platform. Therefore, such a programmable DP can provide in-network computing capability for many application services. In this paper, we target to enhance the data plane with in-network deep learning (DL) capability. However, in-network intelligence can be a significant load for network devices. Then, the paradigm of the functional split is applied so that the deep neural network (DNN) is decomposed into sub-elements of the data plane for making machine learning inference jobs more efficient. As a proof-of-concept, we take a Blind Source Separation (BSS) problem as an example to exhibit the benefits of such an approach. We implement the proposed enhancement in a full-stack emulator and we provide a quantitative evaluation with professional datasets. As an initial trial, our study provides insightful guidelines for the design of the future mobile network system, employing in-network intelligence (e.g., 6G).