 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRISM: Self-Pruning Intrinsic Selection Method for Training-Free Multimodal Data Selection
Feb 17, 2025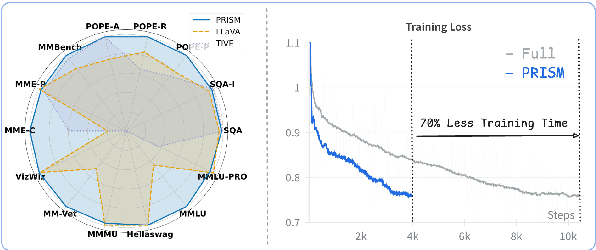
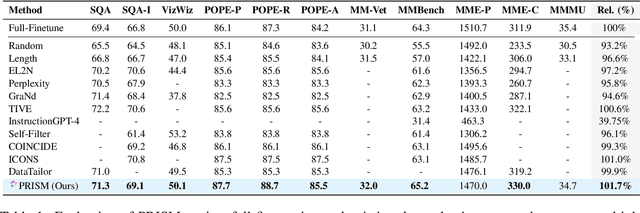
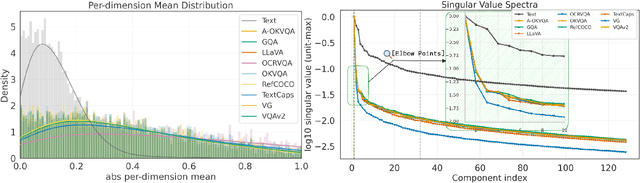
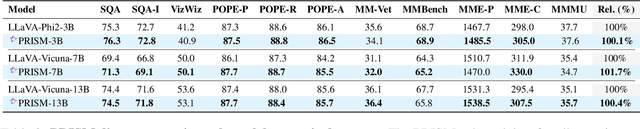
Visual instruction tuning refines pre-trained Multimodal Large Language Models (MLLMs) to enhance their real-world task performance. However, the rapid expansion of visual instruction datasets introduces significant data redundancy, leading to excessive computational costs. Existing data selection methods predominantly rely on proxy models or loss-based metrics, both of which impose substantial computational overheads due to the necessity of model inference and backpropagation. To address this challenge, we propose PRISM, a novel training-free approach for efficient multimodal data selection. Unlike existing methods, PRISM eliminates the reliance on proxy models, warm-up pretraining, and gradient-based optimization. Instead, it leverages Pearson correlation analysis to quantify the intrinsic visual encoding properties of MLLMs, computing a task-specific correlation score to identify high-value instances. This not only enbles data-efficient selection,but maintains the original performance. Empirical evaluations across multiple MLLMs demonstrate that PRISM reduces the overall time required for visual instruction tuning and data selection to just 30% of conventional methods, while surpassing fully fine-tuned models across eight multimodal and three language understanding benchmarks, achieving a 101.7% relative improvement in final performance.
Visual Instruction Tuning with 500x Fewer Parameters through Modality Linear Representation-Steering
Dec 16, 2024



Multimodal Large Language Models (MLLMs) have significantly advanced visual tasks by integrating visual representations into large language models (LLMs). The textual modality, inherited from LLMs, equips MLLMs with abilities like instruction following and in-context learning. In contrast, the visual modality enhances performance in downstream tasks by leveraging rich semantic content, spatial information, and grounding capabilities. These intrinsic modalities work synergistically across various visual tasks. Our research initially reveals a persistent imbalance between these modalities, with text often dominating output generation during visual instruction tuning. This imbalance occurs when using both full fine-tuning and parameter-efficient fine-tuning (PEFT) methods. We then found that re-balancing these modalities can significantly reduce the number of trainable parameters required, inspiring a direction for further optimizing visual instruction tuning. We introduce Modality Linear Representation-Steering (MoReS) to achieve the goal. MoReS effectively re-balances the intrinsic modalities throughout the model, where the key idea is to steer visual representations through linear transformations in the visual subspace across each model layer. To validate our solution, we composed LLaVA Steering, a suite of models integrated with the proposed MoReS method. Evaluation results show that the composed LLaVA Steering models require, on average, 500 times fewer trainable parameters than LoRA needs while still achieving comparable performance across three visual benchmarks and eight visual question-answering tasks. Last, we present the LLaVA Steering Factory, an in-house developed platform that enables researchers to quickly customize various MLLMs with component-based architecture for seamlessly integrating state-of-the-art models, and evaluate their intrinsic modality imbalance.
Multi-Agent Reinforcement Learning for Long-Term Network Resource Allocation through Auction: a V2X Application
Jul 29, 2022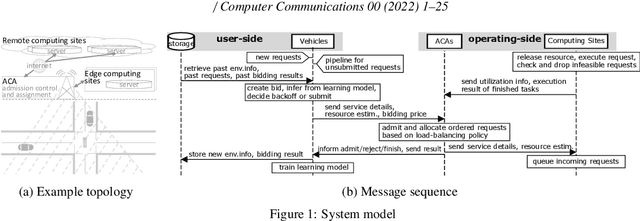



We formulate offloading of computational tasks from a dynamic group of mobile agents (e.g., cars) as decentralized decision making among autonomous agents. We design an interaction mechanism that incentivizes such agents to align private and system goals by balancing between competition and cooperation. In the static case, the mechanism provably has Nash equilibria with optimal resource allocation. In a dynamic environment, this mechanism's requirement of complete information is impossible to achieve. For such environments, we propose a novel multi-agent online learning algorithm that learns with partial, delayed and noisy state information, thus greatly reducing information need. Our algorithm is also capable of learning from long-term and sparse reward signals with varying delay. Empirical results from the simulation of a V2X application confirm that through learning, agents with the learning algorithm significantly improve both system and individual performance, reducing up to 30% of offloading failure rate, communication overhead and load variation, increasing computation resource utilization and fairness. Results also confirm the algorithm's good convergence and generalization property in different environments.
Multi-Agent Distributed Reinforcement Learning for Making Decentralized Offloading Decisions
Apr 05, 2022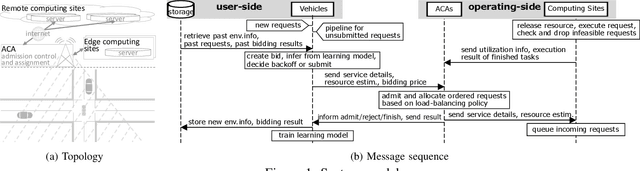
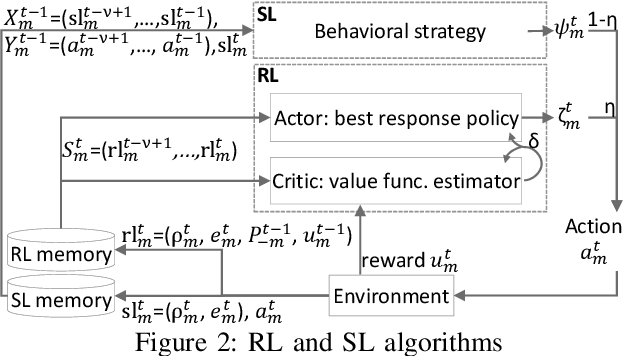
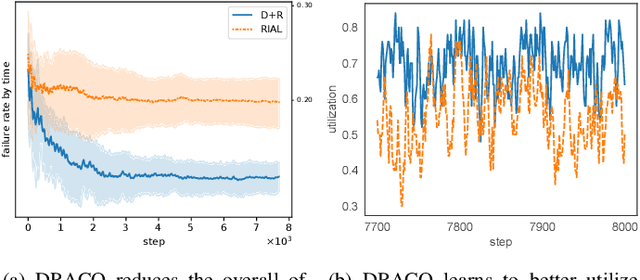

We formulate computation offloading as a decentralized decision-making problem with autonomous agents. We design an interaction mechanism that incentivizes agents to align private and system goals by balancing between competition and cooperation. The mechanism provably has Nash equilibria with optimal resource allocation in the static case. For a dynamic environment, we propose a novel multi-agent online learning algorithm that learns with partial, delayed and noisy state information, and a reward signal that reduces information need to a great extent. Empirical results confirm that through learning, agents significantly improve both system and individual performance, e.g., 40% offloading failure rate reduction, 32% communication overhead reduction, up to 38% computation resource savings in low contention, 18% utilization increase with reduced load variation in high contention, and improvement in fairness. Results also confirm the algorithm's good convergence and generalization property in significantly different environments.
Towards Runtime Verification of Programmable Switches
Apr 26, 2020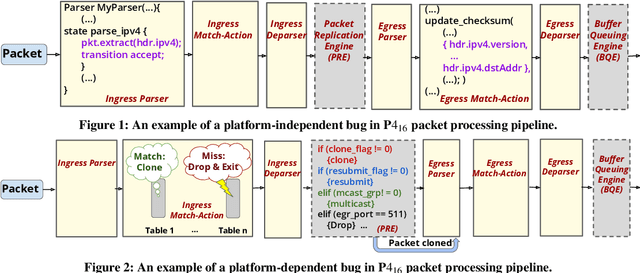

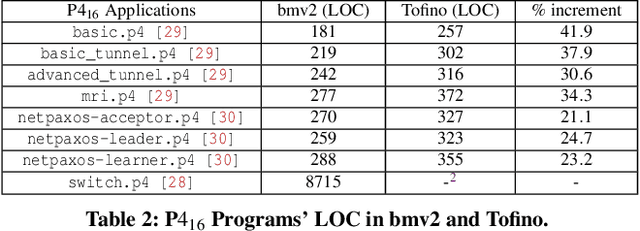
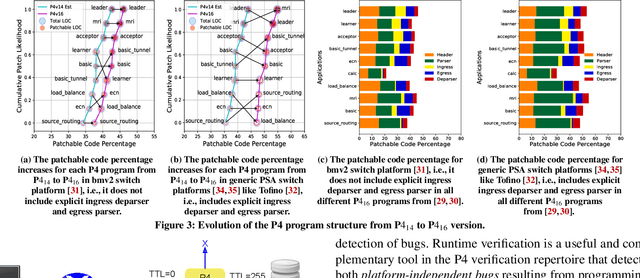
Is it possible to patch software bugs in P4 programs without human involvement? We show that this is partially possible in many cases due to advances in software testing and the structure of P4 programs. Our insight is that runtime verification can detect bugs, even those that are not detected at compile-time, with machine learning-guided fuzzing. This enables a more automated and real-time localization of bugs in P4 programs using software testing techniques like Tarantula. Once the bug in a P4 program is localized, the faulty code can be patched due to the programmable nature of P4. In addition, platform-dependent bugs can be detected. From P4_14 to P4_16 (latest version), our observation is that as the programmable blocks increase, the patchability of P4 programs increases accordingly. To this end, we design, develop, and evaluate P6 that (a) detects, (b) localizes, and (c) patches bugs in P4 programs with minimal human interaction. P6 tests P4 switch non-intrusively, i.e., requires no modification to the P4 program for detecting and localizing bugs. We used a P6 prototype to detect and patch seven existing bugs in eight publicly available P4 application programs deployed on two different switch platforms: behavioral model (bmv2) and Tofino. Our evaluation shows that P6 significantly outperforms bug detection baselines while generating fewer packets and patches bugs in P4 programs such as switch.p4 without triggering any regressions.