 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUtility Function is All You Need: LLM-based Congestion Control
Mar 11, 2026Congestion is a critical and challenging problem in communication networks. Congestion control protocols allow network applications to tune their sending rate in a way that optimizes their performance and the network utilization. In the common distributed setting, the applications cannot collaborate with each other directly but instead obtain similar estimations about the state of the network using latency and loss measurements. These measurements can be fed into analytical functions, referred to by utility functions, whose gradients help each and all distributed senders to converge to a desired state. The above process becomes extremely complicated when each application has different optimization goals and requirements. Crafting these utilization functions has been a research subject for over a decade, with small incremental changes requiring rigorous mathematical analysis as well as real-world experiments. In this work, we present GenCC, a framework leveraging the code generation capabilities of large language models (LLMs) coupled with realistic network testbed, to design congestion control utility functions. Using GenCC, we analyze the impact of different guidance strategies on the performance of the generated protocols, considering application-specific requirements and network capacity. Our results show that LLMs, guided by either a generative code evolution strategy or mathematical chain-of-thought (CoT), can obtain close to optimal results, improving state-of-the-art congestion control protocols by 37%-142%, depending on the scenario.
Online Algorithms with Unreliable Guidance
Feb 24, 2026This paper introduces a new model for ML-augmented online decision making, called online algorithms with unreliable guidance (OAG). This model completely separates between the predictive and algorithmic components, thus offering a single well-defined analysis framework that relies solely on the considered problem. Formulated through the lens of request-answer games, an OAG algorithm receives, with each incoming request, a piece of guidance which is taken from the problem's answer space; ideally, this guidance is the optimal answer for the current request, however with probability $β$, the guidance is adversarially corrupted. The goal is to develop OAG algorithms that admit good competitiveness when $β= 0$ (a.k.a. consistency) as well as when $β= 1$ (a.k.a. robustness); the appealing notion of smoothness, that in most prior work required a dedicated loss function, now arises naturally as $β$ shifts from $0$ to $1$. We then describe a systematic method, called the drop or trust blindly (DTB) compiler, which transforms any online algorithm into a learning-augmented online algorithm in the OAG model. Given a prediction-oblivious online algorithm, its learning-augmented counterpart produced by applying the DTB compiler either follows the incoming guidance blindly or ignores it altogether and proceeds as the initial algorithm would have; the choice between these two alternatives is based on the outcome of a (biased) coin toss. As our main technical contribution, we prove (rigorously) that although remarkably simple, the class of algorithms produced via the DTB compiler includes algorithms with attractive consistency-robustness guarantees for three classic online problems: for caching and uniform metrical task systems our algorithms are optimal, whereas for bipartite matching (with adversarial arrival order), our algorithm outperforms the state-of-the-art.
Enhancing Manufacturing Knowledge Access with LLMs and Context-aware Prompting
Jul 30, 2025



Knowledge graphs (KGs) have transformed data management within the manufacturing industry, offering effective means for integrating disparate data sources through shared and structured conceptual schemas. However, harnessing the power of KGs can be daunting for non-experts, as it often requires formulating complex SPARQL queries to retrieve specific information. With the advent of Large Language Models (LLMs), there is a growing potential to automatically translate natural language queries into the SPARQL format, thus bridging the gap between user-friendly interfaces and the sophisticated architecture of KGs. The challenge remains in adequately informing LLMs about the relevant context and structure of domain-specific KGs, e.g., in manufacturing, to improve the accuracy of generated queries. In this paper, we evaluate multiple strategies that use LLMs as mediators to facilitate information retrieval from KGs. We focus on the manufacturing domain, particularly on the Bosch Line Information System KG and the I40 Core Information Model. In our evaluation, we compare various approaches for feeding relevant context from the KG to the LLM and analyze their proficiency in transforming real-world questions into SPARQL queries. Our findings show that LLMs can significantly improve their performance on generating correct and complete queries when provided only the adequate context of the KG schema. Such context-aware prompting techniques help LLMs to focus on the relevant parts of the ontology and reduce the risk of hallucination. We anticipate that the proposed techniques help LLMs to democratize access to complex data repositories and empower informed decision-making in manufacturing settings.
Centroid Approximation for Byzantine-Tolerant Federated Learning
Jun 18, 2025Federated learning allows each client to keep its data locally when training machine learning models in a distributed setting. Significant recent research established the requirements that the input must satisfy in order to guarantee convergence of the training loop. This line of work uses averaging as the aggregation rule for the training models. In particular, we are interested in whether federated learning is robust to Byzantine behavior, and observe and investigate a tradeoff between the average/centroid and the validity conditions from distributed computing. We show that the various validity conditions alone do not guarantee a good approximation of the average. Furthermore, we show that reaching good approximation does not give good results in experimental settings due to possible Byzantine outliers. Our main contribution is the first lower bound of $\min\{\frac{n-t}{t},\sqrt{d}\}$ on the centroid approximation under box validity that is often considered in the literature, where $n$ is the number of clients, $t$ the upper bound on the number of Byzantine faults, and $d$ is the dimension of the machine learning model. We complement this lower bound by an upper bound of $2\min\{n,\sqrt{d}\}$, by providing a new analysis for the case $n<d$. In addition, we present a new algorithm that achieves a $\sqrt{2d}$-approximation under convex validity, which also proves that the existing lower bound in the literature is tight. We show that all presented bounds can also be achieved in the distributed peer-to-peer setting. We complement our analytical results with empirical evaluations in federated stochastic gradient descent and federated averaging settings.
MultiADS: Defect-aware Supervision for Multi-type Anomaly Detection and Segmentation in Zero-Shot Learning
Apr 09, 2025Precise optical inspection in industrial applications is crucial for minimizing scrap rates and reducing the associated costs. Besides merely detecting if a product is anomalous or not, it is crucial to know the distinct type of defect, such as a bent, cut, or scratch. The ability to recognize the "exact" defect type enables automated treatments of the anomalies in modern production lines. Current methods are limited to solely detecting whether a product is defective or not without providing any insights on the defect type, nevertheless detecting and identifying multiple defects. We propose MultiADS, a zero-shot learning approach, able to perform Multi-type Anomaly Detection and Segmentation. The architecture of MultiADS comprises CLIP and extra linear layers to align the visual- and textual representation in a joint feature space. To the best of our knowledge, our proposal, is the first approach to perform a multi-type anomaly segmentation task in zero-shot learning. Contrary to the other baselines, our approach i) generates specific anomaly masks for each distinct defect type, ii) learns to distinguish defect types, and iii) simultaneously identifies multiple defect types present in an anomalous product. Additionally, our approach outperforms zero/few-shot learning SoTA methods on image-level and pixel-level anomaly detection and segmentation tasks on five commonly used datasets: MVTec-AD, Visa, MPDD, MAD and Real-IAD.
Approximate Agreement Algorithms for Byzantine Collaborative Learning
Apr 02, 2025In Byzantine collaborative learning, $n$ clients in a peer-to-peer network collectively learn a model without sharing their data by exchanging and aggregating stochastic gradient estimates. Byzantine clients can prevent others from collecting identical sets of gradient estimates. The aggregation step thus needs to be combined with an efficient (approximate) agreement subroutine to ensure convergence of the training process. In this work, we study the geometric median aggregation rule for Byzantine collaborative learning. We show that known approaches do not provide theoretical guarantees on convergence or gradient quality in the agreement subroutine. To satisfy these theoretical guarantees, we present a hyperbox algorithm for geometric median aggregation. We practically evaluate our algorithm in both centralized and decentralized settings under Byzantine attacks on non-i.i.d. data. We show that our geometric median-based approaches can tolerate sign-flip attacks better than known mean-based approaches from the literature.
Predicting the Road Ahead: A Knowledge Graph based Foundation Model for Scene Understanding in Autonomous Driving
Mar 24, 2025The autonomous driving field has seen remarkable advancements in various topics, such as object recognition, trajectory prediction, and motion planning. However, current approaches face limitations in effectively comprehending the complex evolutions of driving scenes over time. This paper proposes FM4SU, a novel methodology for training a symbolic foundation model (FM) for scene understanding in autonomous driving. It leverages knowledge graphs (KGs) to capture sensory observation along with domain knowledge such as road topology, traffic rules, or complex interactions between traffic participants. A bird's eye view (BEV) symbolic representation is extracted from the KG for each driving scene, including the spatio-temporal information among the objects across the scenes. The BEV representation is serialized into a sequence of tokens and given to pre-trained language models (PLMs) for learning an inherent understanding of the co-occurrence among driving scene elements and generating predictions on the next scenes. We conducted a number of experiments using the nuScenes dataset and KG in various scenarios. The results demonstrate that fine-tuned models achieve significantly higher accuracy in all tasks. The fine-tuned T5 model achieved a next scene prediction accuracy of 86.7%. This paper concludes that FM4SU offers a promising foundation for developing more comprehensive models for scene understanding in autonomous driving.
An Optimization Driven Link SINR Assurance in RIS-assisted Indoor Networks
Dec 28, 2024Future smart factories are expected to deploy applications over high-performance indoor wireless channels in the millimeter-wave (mmWave) bands, which on the other hand are susceptible to high path losses and Line-of Sight (LoS) blockages. Low-cost Reconfigurable Intelligent Surfaces (RISs) can provide great opportunities in such scenarios, due to its ability to alleviate LoS link blockages. In this paper, we formulate a combinatorial optimization problem, solved with Integer Linear Programming (ILP) to optimally maintain connectivity by solving the problem of allocating RIS to robots in a wireless indoor network. Our model exploits the characteristic of nulling interference from RISs by tuning RIS reflection coefficients. We further consider Quality-of-Service (QoS) at receivers in terms of Signal-to-Interference-plus-Noise Ratio (SINR) and connection outages due to insufficient transmission quality service. Numerical results for optimal solutions and heuristics show the benefits of optimally deploying RISs by providing continuous connectivity through SINR, which significantly reduces outages due to link quality.
Visual Representation Learning Guided By Multi-modal Prior Knowledge
Oct 21, 2024Despite the remarkable success of deep neural networks (DNNs) in computer vision, they fail to remain high-performing when facing distribution shifts between training and testing data. In this paper, we propose Knowledge-Guided Visual representation learning (KGV), a distribution-based learning approach leveraging multi-modal prior knowledge, to improve generalization under distribution shift. We use prior knowledge from two distinct modalities: 1) a knowledge graph (KG) with hierarchical and association relationships; and 2) generated synthetic images of visual elements semantically represented in the KG. The respective embeddings are generated from the given modalities in a common latent space, i.e., visual embeddings from original and synthetic images as well as knowledge graph embeddings (KGEs). These embeddings are aligned via a novel variant of translation-based KGE methods, where the node and relation embeddings of the KG are modeled as Gaussian distributions and translations respectively. We claim that incorporating multi-model prior knowledge enables more regularized learning of image representations. Thus, the models are able to better generalize across different data distributions. We evaluate KGV on different image classification tasks with major or minor distribution shifts, namely road sign classification across datasets from Germany, China, and Russia, image classification with the mini-ImageNet dataset and its variants, as well as the DVM-CAR dataset. The results demonstrate that KGV consistently exhibits higher accuracy and data efficiency than the baselines across all experiments.
GermanPartiesQA: Benchmarking Commercial Large Language Models for Political Bias and Sycophancy
Jul 25, 2024
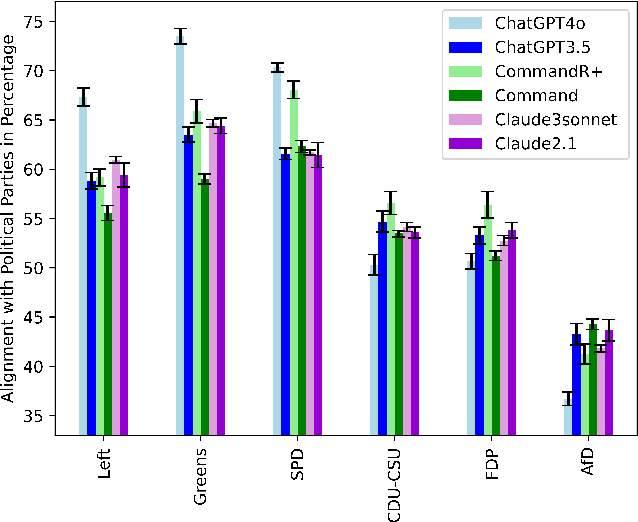

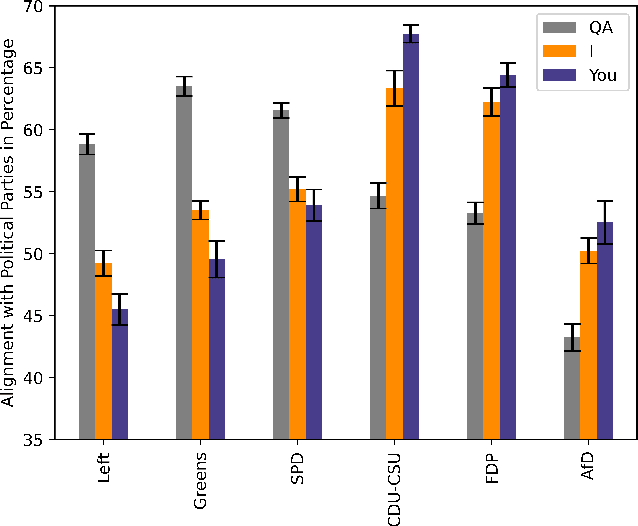
LLMs are changing the way humans create and interact with content, potentially affecting citizens' political opinions and voting decisions. As LLMs increasingly shape our digital information ecosystems, auditing to evaluate biases, sycophancy, or steerability has emerged as an active field of research. In this paper, we evaluate and compare the alignment of six LLMs by OpenAI, Anthropic, and Cohere with German party positions and evaluate sycophancy based on a prompt experiment. We contribute to evaluating political bias and sycophancy in multi-party systems across major commercial LLMs. First, we develop the benchmark dataset GermanPartiesQA based on the Voting Advice Application Wahl-o-Mat covering 10 state and 1 national elections between 2021 and 2023. In our study, we find a left-green tendency across all examined LLMs. We then conduct our prompt experiment for which we use the benchmark and sociodemographic data of leading German parliamentarians to evaluate changes in LLMs responses. To differentiate between sycophancy and steerabilty, we use 'I am [politician X], ...' and 'You are [politician X], ...' prompts. Against our expectations, we do not observe notable differences between prompting 'I am' and 'You are'. While our findings underscore that LLM responses can be ideologically steered with political personas, they suggest that observed changes in LLM outputs could be better described as personalization to the given context rather than sycophancy.