 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGR-Agent: Adaptive Graph Reasoning Agent under Incomplete Knowledge
Dec 16, 2025

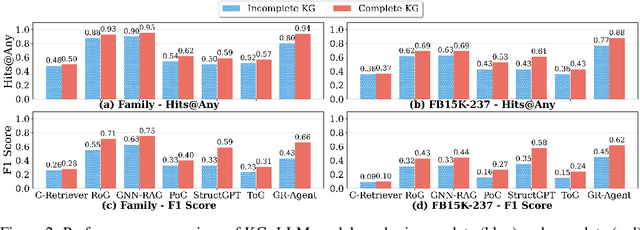

Large language models (LLMs) achieve strong results on knowledge graph question answering (KGQA), but most benchmarks assume complete knowledge graphs (KGs) where direct supporting triples exist. This reduces evaluation to shallow retrieval and overlooks the reality of incomplete KGs, where many facts are missing and answers must be inferred from existing facts. We bridge this gap by proposing a methodology for constructing benchmarks under KG incompleteness, which removes direct supporting triples while ensuring that alternative reasoning paths required to infer the answer remain. Experiments on benchmarks constructed using our methodology show that existing methods suffer consistent performance degradation under incompleteness, highlighting their limited reasoning ability. To overcome this limitation, we present the Adaptive Graph Reasoning Agent (GR-Agent). It first constructs an interactive environment from the KG, and then formalizes KGQA as agent environment interaction within this environment. GR-Agent operates over an action space comprising graph reasoning tools and maintains a memory of potential supporting reasoning evidence, including relevant relations and reasoning paths. Extensive experiments demonstrate that GR-Agent outperforms non-training baselines and performs comparably to training-based methods under both complete and incomplete settings.
What Breaks Knowledge Graph based RAG? Empirical Insights into Reasoning under Incomplete Knowledge
Aug 11, 2025Knowledge Graph-based Retrieval-Augmented Generation (KG-RAG) is an increasingly explored approach for combining the reasoning capabilities of large language models with the structured evidence of knowledge graphs. However, current evaluation practices fall short: existing benchmarks often include questions that can be directly answered using existing triples in KG, making it unclear whether models perform reasoning or simply retrieve answers directly. Moreover, inconsistent evaluation metrics and lenient answer matching criteria further obscure meaningful comparisons. In this work, we introduce a general method for constructing benchmarks, together with an evaluation protocol, to systematically assess KG-RAG methods under knowledge incompleteness. Our empirical results show that current KG-RAG methods have limited reasoning ability under missing knowledge, often rely on internal memorization, and exhibit varying degrees of generalization depending on their design.
Predicate-Conditional Conformalized Answer Sets for Knowledge Graph Embeddings
May 22, 2025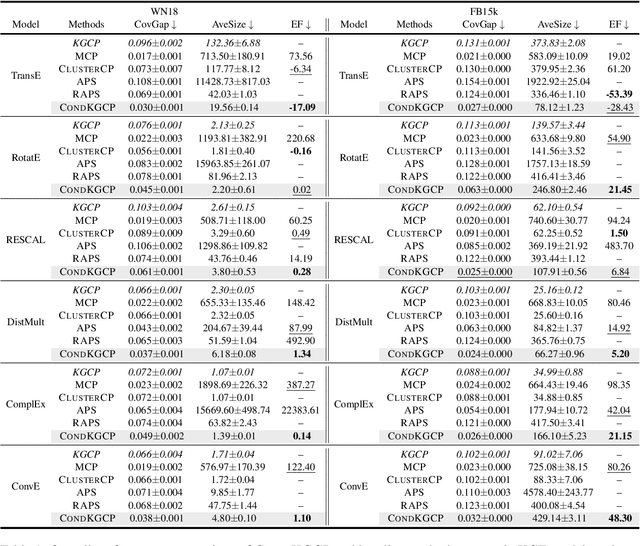
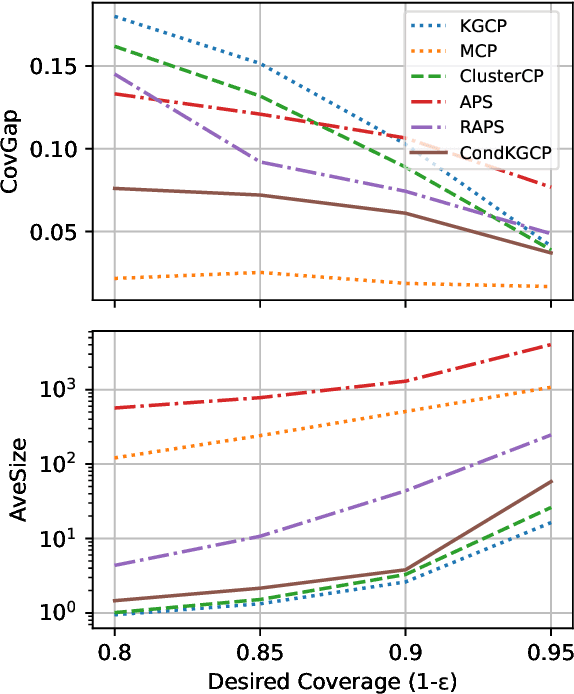
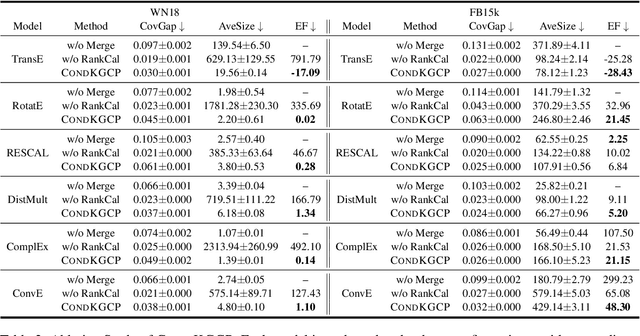
Uncertainty quantification in Knowledge Graph Embedding (KGE) methods is crucial for ensuring the reliability of downstream applications. A recent work applies conformal prediction to KGE methods, providing uncertainty estimates by generating a set of answers that is guaranteed to include the true answer with a predefined confidence level. However, existing methods provide probabilistic guarantees averaged over a reference set of queries and answers (marginal coverage guarantee). In high-stakes applications such as medical diagnosis, a stronger guarantee is often required: the predicted sets must provide consistent coverage per query (conditional coverage guarantee). We propose CondKGCP, a novel method that approximates predicate-conditional coverage guarantees while maintaining compact prediction sets. CondKGCP merges predicates with similar vector representations and augments calibration with rank information. We prove the theoretical guarantees and demonstrate empirical effectiveness of CondKGCP by comprehensive evaluations.
Evaluating Knowledge Graph Based Retrieval Augmented Generation Methods under Knowledge Incompleteness
Apr 07, 2025

Knowledge Graph based Retrieval-Augmented Generation (KG-RAG) is a technique that enhances Large Language Model (LLM) inference in tasks like Question Answering (QA) by retrieving relevant information from knowledge graphs (KGs). However, real-world KGs are often incomplete, meaning that essential information for answering questions may be missing. Existing benchmarks do not adequately capture the impact of KG incompleteness on KG-RAG performance. In this paper, we systematically evaluate KG-RAG methods under incomplete KGs by removing triples using different methods and analyzing the resulting effects. We demonstrate that KG-RAG methods are sensitive to KG incompleteness, highlighting the need for more robust approaches in realistic settings.
Supposedly Equivalent Facts That Aren't? Entity Frequency in Pre-training Induces Asymmetry in LLMs
Mar 28, 2025Understanding and mitigating hallucinations in Large Language Models (LLMs) is crucial for ensuring reliable content generation. While previous research has primarily focused on "when" LLMs hallucinate, our work explains "why" and directly links model behaviour to the pre-training data that forms their prior knowledge. Specifically, we demonstrate that an asymmetry exists in the recognition of logically equivalent facts, which can be attributed to frequency discrepancies of entities appearing as subjects versus objects. Given that most pre-training datasets are inaccessible, we leverage the fully open-source OLMo series by indexing its Dolma dataset to estimate entity frequencies. Using relational facts (represented as triples) from Wikidata5M, we construct probing datasets to isolate this effect. Our experiments reveal that facts with a high-frequency subject and a low-frequency object are better recognised than their inverse, despite their logical equivalence. The pattern reverses in low-to-high frequency settings, and no statistically significant asymmetry emerges when both entities are high-frequency. These findings highlight the influential role of pre-training data in shaping model predictions and provide insights for inferring the characteristics of pre-training data in closed or partially closed LLMs.
DAGE: DAG Query Answering via Relational Combinator with Logical Constraints
Oct 29, 2024Predicting answers to queries over knowledge graphs is called a complex reasoning task because answering a query requires subdividing it into subqueries. Existing query embedding methods use this decomposition to compute the embedding of a query as the combination of the embedding of the subqueries. This requirement limits the answerable queries to queries having a single free variable and being decomposable, which are called tree-form queries and correspond to the $\mathcal{SROI}^-$ description logic. In this paper, we define a more general set of queries, called DAG queries and formulated in the $\mathcal{ALCOIR}$ description logic, propose a query embedding method for them, called DAGE, and a new benchmark to evaluate query embeddings on them. Given the computational graph of a DAG query, DAGE combines the possibly multiple paths between two nodes into a single path with a trainable operator that represents the intersection of relations and learns DAG-DL from tautologies. We show that it is possible to implement DAGE on top of existing query embedding methods, and we empirically measure the improvement of our method over the results of vanilla methods evaluated in tree-form queries that approximate the DAG queries of our proposed benchmark.
Visual Representation Learning Guided By Multi-modal Prior Knowledge
Oct 21, 2024Despite the remarkable success of deep neural networks (DNNs) in computer vision, they fail to remain high-performing when facing distribution shifts between training and testing data. In this paper, we propose Knowledge-Guided Visual representation learning (KGV), a distribution-based learning approach leveraging multi-modal prior knowledge, to improve generalization under distribution shift. We use prior knowledge from two distinct modalities: 1) a knowledge graph (KG) with hierarchical and association relationships; and 2) generated synthetic images of visual elements semantically represented in the KG. The respective embeddings are generated from the given modalities in a common latent space, i.e., visual embeddings from original and synthetic images as well as knowledge graph embeddings (KGEs). These embeddings are aligned via a novel variant of translation-based KGE methods, where the node and relation embeddings of the KG are modeled as Gaussian distributions and translations respectively. We claim that incorporating multi-model prior knowledge enables more regularized learning of image representations. Thus, the models are able to better generalize across different data distributions. We evaluate KGV on different image classification tasks with major or minor distribution shifts, namely road sign classification across datasets from Germany, China, and Russia, image classification with the mini-ImageNet dataset and its variants, as well as the DVM-CAR dataset. The results demonstrate that KGV consistently exhibits higher accuracy and data efficiency than the baselines across all experiments.
Predictive Multiplicity of Knowledge Graph Embeddings in Link Prediction
Aug 15, 2024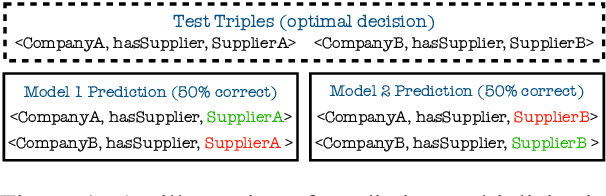

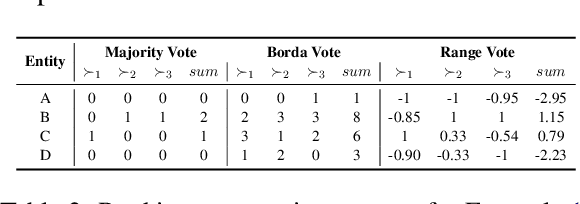

Knowledge graph embedding (KGE) models are often used to predict missing links for knowledge graphs (KGs). However, multiple KG embeddings can perform almost equally well for link prediction yet suggest conflicting predictions for certain queries, termed \textit{predictive multiplicity} in literature. This behavior poses substantial risks for KGE-based applications in high-stake domains but has been overlooked in KGE research. In this paper, we define predictive multiplicity in link prediction. We introduce evaluation metrics and measure predictive multiplicity for representative KGE methods on commonly used benchmark datasets. Our empirical study reveals significant predictive multiplicity in link prediction, with $8\%$ to $39\%$ testing queries exhibiting conflicting predictions. To address this issue, we propose leveraging voting methods from social choice theory, significantly mitigating conflicts by $66\%$ to $78\%$ according to our experiments.
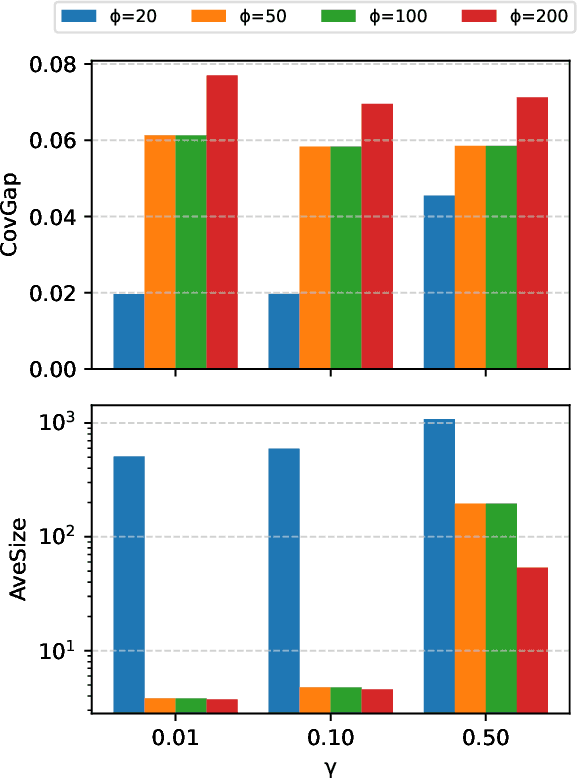
Conformalized Answer Set Prediction for Knowledge Graph Embedding
Aug 15, 2024Knowledge graph embeddings (KGE) apply machine learning methods on knowledge graphs (KGs) to provide non-classical reasoning capabilities based on similarities and analogies. The learned KG embeddings are typically used to answer queries by ranking all potential answers, but rankings often lack a meaningful probabilistic interpretation - lower-ranked answers do not necessarily have a lower probability of being true. This limitation makes it difficult to distinguish plausible from implausible answers, posing challenges for the application of KGE methods in high-stakes domains like medicine. We address this issue by applying the theory of conformal prediction that allows generating answer sets, which contain the correct answer with probabilistic guarantees. We explain how conformal prediction can be used to generate such answer sets for link prediction tasks. Our empirical evaluation on four benchmark datasets using six representative KGE methods validates that the generated answer sets satisfy the probabilistic guarantees given by the theory of conformal prediction. We also demonstrate that the generated answer sets often have a sensible size and that the size adapts well with respect to the difficulty of the query.
Approximating Probabilistic Inference in Statistical EL with Knowledge Graph Embeddings
Jul 16, 2024Statistical information is ubiquitous but drawing valid conclusions from it is prohibitively hard. We explain how knowledge graph embeddings can be used to approximate probabilistic inference efficiently using the example of Statistical EL (SEL), a statistical extension of the lightweight Description Logic EL. We provide proofs for runtime and soundness guarantees, and empirically evaluate the runtime and approximation quality of our approach.