 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversal Latent Homeomorphic Manifolds: Cross-Domain Representation Learning via Homeomorphism Verification
Jan 13, 2026We present the Universal Latent Homeomorphic Manifold (ULHM), a framework that unifies semantic representations (e.g., human descriptions, diagnostic labels) and observation-driven machine representations (e.g., pixel intensities, sensor readings) into a single latent structure. Despite originating from fundamentally different pathways, both modalities capture the same underlying reality. We establish \emph{homeomorphism}, a continuous bijection preserving topological structure, as the mathematical criterion for determining when latent manifolds induced by different semantic-observation pairs can be rigorously unified. This criterion provides theoretical guarantees for three critical applications: (1) semantic-guided sparse recovery from incomplete observations, (2) cross-domain transfer learning with verified structural compatibility, and (3) zero-shot compositional learning via valid transfer from semantic to observation space. Our framework learns continuous manifold-to-manifold transformations through conditional variational inference, avoiding brittle point-to-point mappings. We develop practical verification algorithms, including trust, continuity, and Wasserstein distance metrics, that empirically validate homeomorphic structure from finite samples. Experiments demonstrate: (1) sparse image recovery from 5\% of CelebA pixels and MNIST digit reconstruction at multiple sparsity levels, (2) cross-domain classifier transfer achieving 86.73\% accuracy from MNIST to Fashion-MNIST without retraining, and (3) zero-shot classification on unseen classes achieving 89.47\% on MNIST, 84.70\% on Fashion-MNIST, and 78.76\% on CIFAR-10. Critically, the homeomorphism criterion correctly rejects incompatible datasets, preventing invalid unification and providing a feasible way to principled decomposition of general foundation models into verified domain-specific components.
Towards Foundation Model on Temporal Knowledge Graph Reasoning
Jun 04, 2025Temporal Knowledge Graphs (TKGs) store temporal facts with quadruple formats (s, p, o, t). Existing Temporal Knowledge Graph Embedding (TKGE) models perform link prediction tasks in transductive or semi-inductive settings, which means the entities, relations, and temporal information in the test graph are fully or partially observed during training. Such reliance on seen elements during inference limits the models' ability to transfer to new domains and generalize to real-world scenarios. A central limitation is the difficulty in learning representations for entities, relations, and timestamps that are transferable and not tied to dataset-specific vocabularies. To overcome these limitations, we introduce the first fully-inductive approach to temporal knowledge graph link prediction. Our model employs sinusoidal positional encodings to capture fine-grained temporal patterns and generates adaptive entity and relation representations using message passing conditioned on both local and global temporal contexts. Our model design is agnostic to temporal granularity and time span, effectively addressing temporal discrepancies across TKGs and facilitating time-aware structural information transfer. As a pretrained, scalable, and transferable model, POSTRA demonstrates strong zero-shot performance on unseen temporal knowledge graphs, effectively generalizing to novel entities, relations, and timestamps. Extensive theoretical analysis and empirical results show that a single pretrained model can improve zero-shot performance on various inductive temporal reasoning scenarios, marking a significant step toward a foundation model for temporal KGs.
Is Complex Query Answering Really Complex?
Oct 16, 2024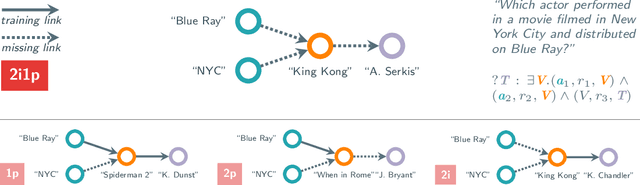
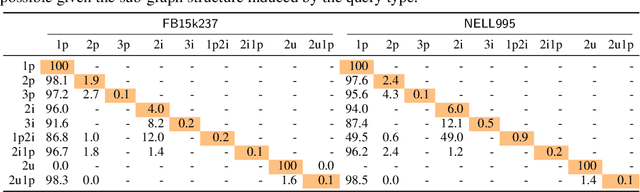

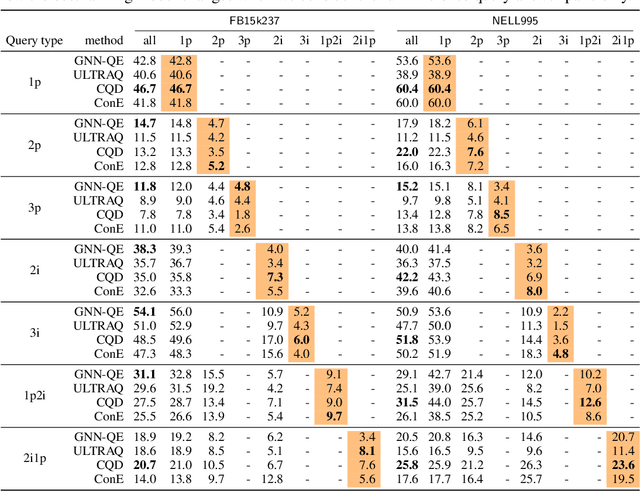
Complex query answering (CQA) on knowledge graphs (KGs) is gaining momentum as a challenging reasoning task. In this paper, we show that the current benchmarks for CQA are not really complex, and the way they are built distorts our perception of progress in this field. For example, we find that in these benchmarks, most queries (up to 98% for some query types) can be reduced to simpler problems, e.g., link prediction, where only one link needs to be predicted. The performance of state-of-the-art CQA models drops significantly when such models are evaluated on queries that cannot be reduced to easier types. Thus, we propose a set of more challenging benchmarks, composed of queries that require models to reason over multiple hops and better reflect the construction of real-world KGs. In a systematic empirical investigation, the new benchmarks show that current methods leave much to be desired from current CQA methods.
Generating SROI^{-} Ontologies via Knowledge Graph Query Embedding Learning
Jul 12, 2024Query embedding approaches answer complex logical queries over incomplete knowledge graphs (KGs) by computing and operating on low-dimensional vector representations of entities, relations, and queries. However, current query embedding models heavily rely on excessively parameterized neural networks and cannot explain the knowledge learned from the graph. We propose a novel query embedding method, AConE, which explains the knowledge learned from the graph in the form of SROI^{-} description logic axioms while being more parameter-efficient than most existing approaches. AConE associates queries to a SROI^{-} description logic concept. Every SROI^{-} concept is embedded as a cone in complex vector space, and each SROI^{-} relation is embedded as a transformation that rotates and scales cones. We show theoretically that AConE can learn SROI^{-} axioms, and defines an algebra whose operations correspond one to one to SROI^{-} description logic concept constructs. Our empirical study on multiple query datasets shows that AConE achieves superior results over previous baselines with fewer parameters. Notably on the WN18RR dataset, AConE achieves significant improvement over baseline models. We provide comprehensive analyses showing that the capability to represent axioms positively impacts the results of query answering.
ETHER: Aligning Emergent Communication for Hindsight Experience Replay
Jul 28, 2023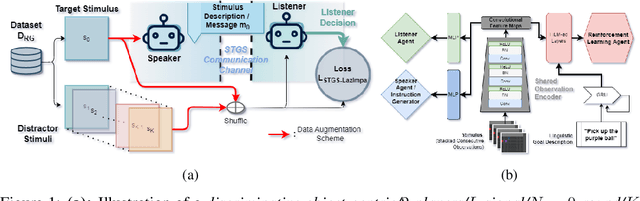

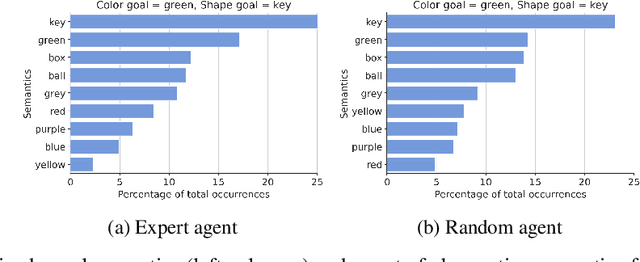

Natural language instruction following is paramount to enable collaboration between artificial agents and human beings. Natural language-conditioned reinforcement learning (RL) agents have shown how natural languages' properties, such as compositionality, can provide a strong inductive bias to learn complex policies. Previous architectures like HIGhER combine the benefit of language-conditioning with Hindsight Experience Replay (HER) to deal with sparse rewards environments. Yet, like HER, HIGhER relies on an oracle predicate function to provide a feedback signal highlighting which linguistic description is valid for which state. This reliance on an oracle limits its application. Additionally, HIGhER only leverages the linguistic information contained in successful RL trajectories, thus hurting its final performance and data-efficiency. Without early successful trajectories, HIGhER is no better than DQN upon which it is built. In this paper, we propose the Emergent Textual Hindsight Experience Replay (ETHER) agent, which builds on HIGhER and addresses both of its limitations by means of (i) a discriminative visual referential game, commonly studied in the subfield of Emergent Communication (EC), used here as an unsupervised auxiliary task and (ii) a semantic grounding scheme to align the emergent language with the natural language of the instruction-following benchmark. We show that the referential game's agents make an artificial language emerge that is aligned with the natural-like language used to describe goals in the BabyAI benchmark and that it is expressive enough so as to also describe unsuccessful RL trajectories and thus provide feedback to the RL agent to leverage the linguistic, structured information contained in all trajectories. Our work shows that EC is a viable unsupervised auxiliary task for RL and provides missing pieces to make HER more widely applicable.
Composing Efficient, Robust Tests for Policy Selection
Jun 12, 2023Modern reinforcement learning systems produce many high-quality policies throughout the learning process. However, to choose which policy to actually deploy in the real world, they must be tested under an intractable number of environmental conditions. We introduce RPOSST, an algorithm to select a small set of test cases from a larger pool based on a relatively small number of sample evaluations. RPOSST treats the test case selection problem as a two-player game and optimizes a solution with provable $k$-of-$N$ robustness, bounding the error relative to a test that used all the test cases in the pool. Empirical results demonstrate that RPOSST finds a small set of test cases that identify high quality policies in a toy one-shot game, poker datasets, and a high-fidelity racing simulator.
BRExIt: On Opponent Modelling in Expert Iteration
May 31, 2022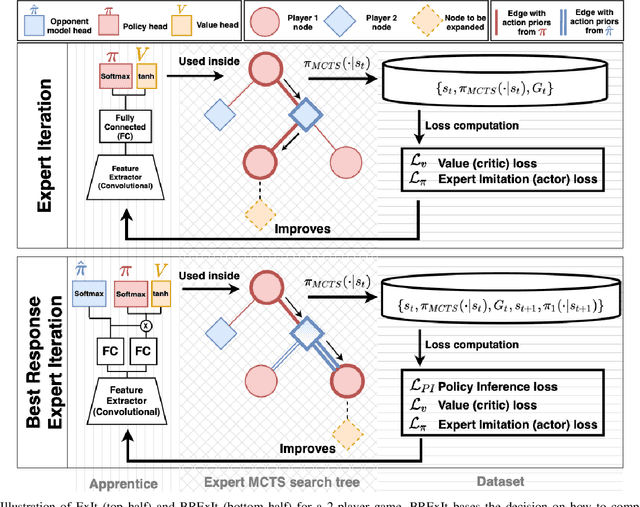
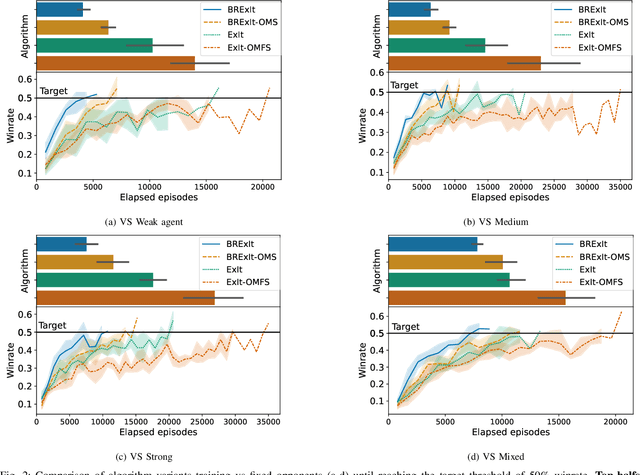
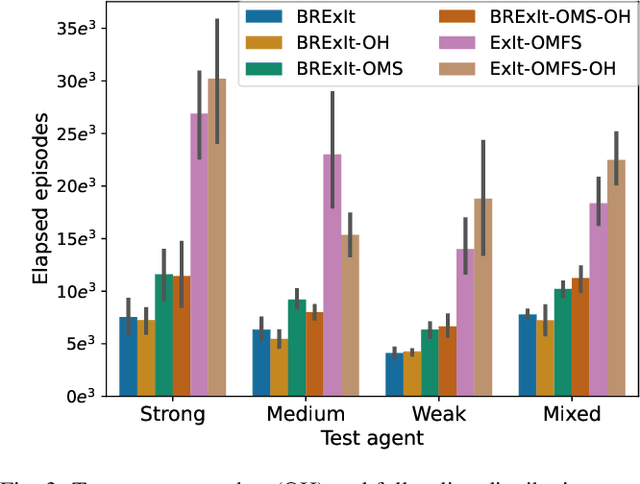
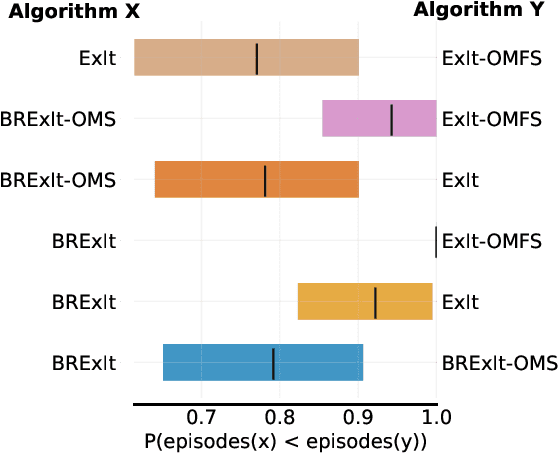
Finding a best response policy is a central objective in game theory and multi-agent learning, with modern population-based training approaches employing reinforcement learning algorithms as best-response oracles to improve play against candidate opponents (typically previously learnt policies). We propose Best Response Expert Iteration (BRExIt), which accelerates learning in games by incorporating opponent models into the state-of-the-art learning algorithm Expert Iteration (ExIt). BRExIt aims to (1) improve feature shaping in the apprentice, with a policy head predicting opponent policies as an auxiliary task, and (2) bias opponent moves in planning towards the given or learnt opponent model, to generate apprentice targets that better approximate a best response. In an empirical ablation on BRExIt's algorithmic variants in the game Connect4 against a set of fixed test agents, we provide statistical evidence that BRExIt learns well-performing policies with greater sample efficiency than ExIt.
A Comparison of Self-Play Algorithms Under a Generalized Framework
Jun 08, 2020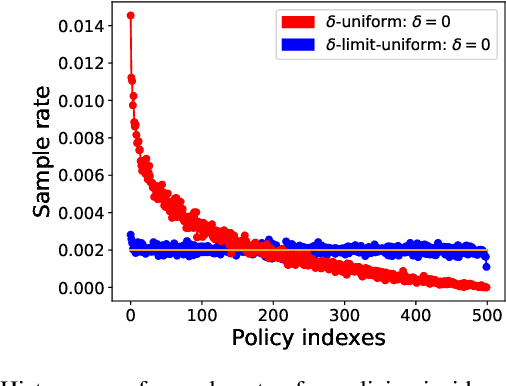
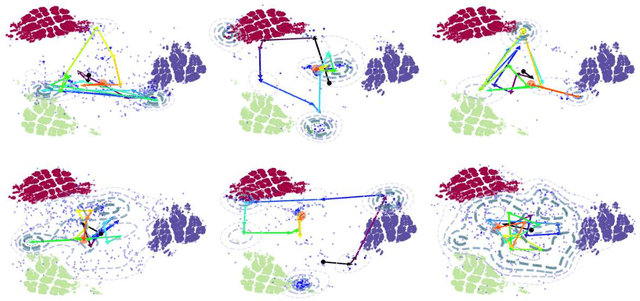
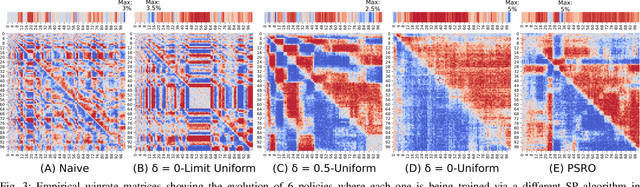
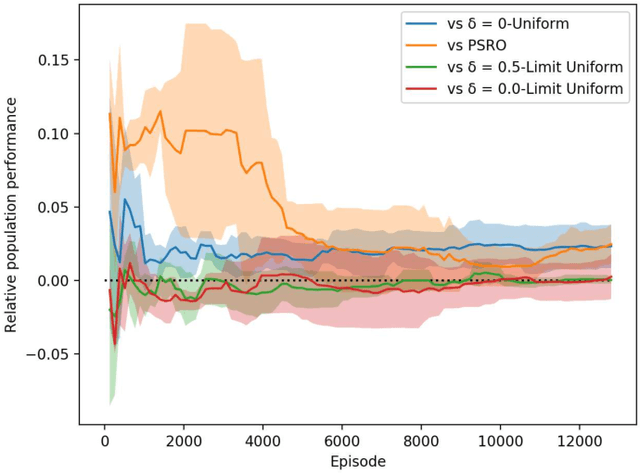
Throughout scientific history, overarching theoretical frameworks have allowed researchers to grow beyond personal intuitions and culturally biased theories. They allow to verify and replicate existing findings, and to link is connected results. The notion of self-play, albeit often cited in multiagent Reinforcement Learning, has never been grounded in a formal model. We present a formalized framework, with clearly defined assumptions, which encapsulates the meaning of self-play as abstracted from various existing self-play algorithms. This framework is framed as an approximation to a theoretical solution concept for multiagent training. On a simple environment, we qualitatively measure how well a subset of the captured self-play methods approximate this solution when paired with the famous PPO algorithm. We also provide insights on interpreting quantitative metrics of performance for self-play training. Our results indicate that, throughout training, various self-play definitions exhibit cyclic policy evolutions.
Metagame Autobalancing for Competitive Multiplayer Games
Jun 08, 2020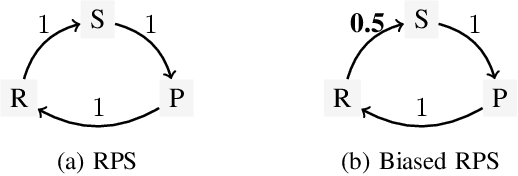
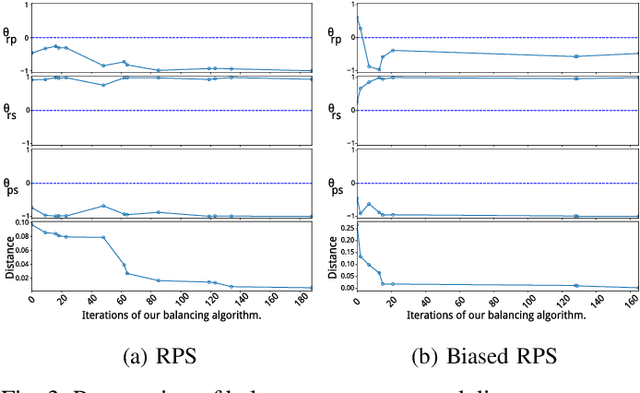

Automated game balancing has often focused on single-agent scenarios. In this paper we present a tool for balancing multi-player games during game design. Our approach requires a designer to construct an intuitive graphical representation of their meta-game target, representing the relative scores that high-level strategies (or decks, or character types) should experience. This permits more sophisticated balance targets to be defined beyond a simple requirement of equal win chances. We then find a parameterization of the game that meets this target using simulation-based optimization to minimize the distance to the target graph. We show the capabilities of this tool on examples inheriting from Rock-Paper-Scissors, and on a more complex asymmetric fighting game.
A Novel Variational Family for Hidden Nonlinear Markov Models
Nov 06, 2018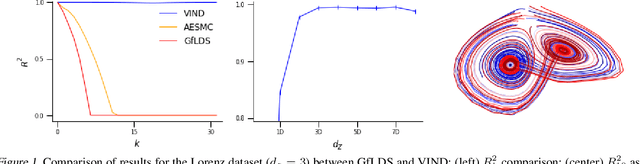
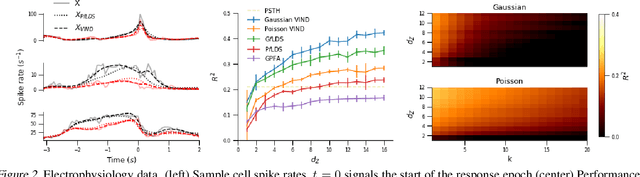
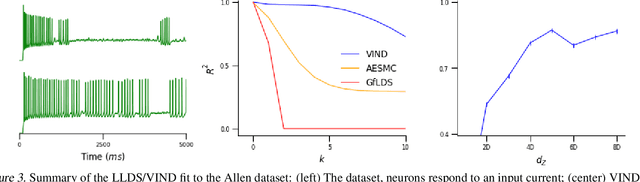
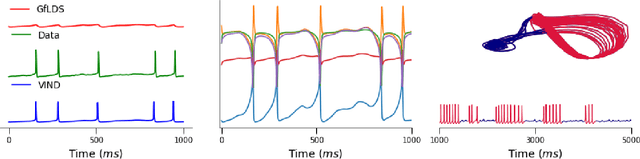
Latent variable models have been widely applied for the analysis and visualization of large datasets. In the case of sequential data, closed-form inference is possible when the transition and observation functions are linear. However, approximate inference techniques are usually necessary when dealing with nonlinear dynamics and observation functions. Here, we propose a novel variational inference framework for the explicit modeling of time series, Variational Inference for Nonlinear Dynamics (VIND), that is able to uncover nonlinear observation and transition functions from sequential data. The framework includes a structured approximate posterior, and an algorithm that relies on the fixed-point iteration method to find the best estimate for latent trajectories. We apply the method to several datasets and show that it is able to accurately infer the underlying dynamics of these systems, in some cases substantially outperforming state-of-the-art methods.