 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepKnowledge: Generalisation-Driven Deep Learning Testing
Mar 25, 2024



Despite their unprecedented success, DNNs are notoriously fragile to small shifts in data distribution, demanding effective testing techniques that can assess their dependability. Despite recent advances in DNN testing, there is a lack of systematic testing approaches that assess the DNN's capability to generalise and operate comparably beyond data in their training distribution. We address this gap with DeepKnowledge, a systematic testing methodology for DNN-based systems founded on the theory of knowledge generalisation, which aims to enhance DNN robustness and reduce the residual risk of 'black box' models. Conforming to this theory, DeepKnowledge posits that core computational DNN units, termed Transfer Knowledge neurons, can generalise under domain shift. DeepKnowledge provides an objective confidence measurement on testing activities of DNN given data distribution shifts and uses this information to instrument a generalisation-informed test adequacy criterion to check the transfer knowledge capacity of a test set. Our empirical evaluation of several DNNs, across multiple datasets and state-of-the-art adversarial generation techniques demonstrates the usefulness and effectiveness of DeepKnowledge and its ability to support the engineering of more dependable DNNs. We report improvements of up to 10 percentage points over state-of-the-art coverage criteria for detecting adversarial attacks on several benchmarks, including MNIST, SVHN, and CIFAR.
ETHER: Aligning Emergent Communication for Hindsight Experience Replay
Jul 28, 2023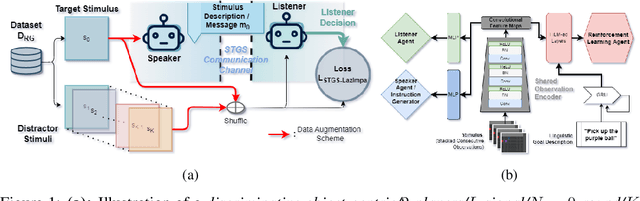


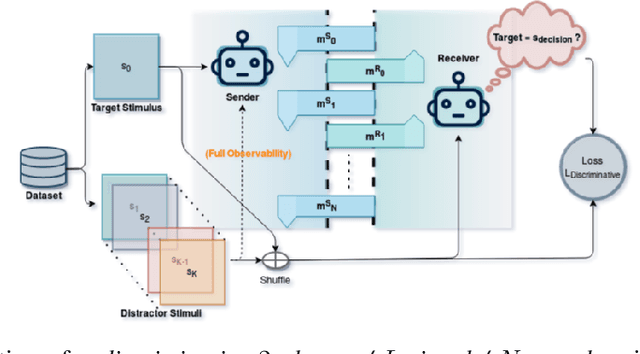
Natural language instruction following is paramount to enable collaboration between artificial agents and human beings. Natural language-conditioned reinforcement learning (RL) agents have shown how natural languages' properties, such as compositionality, can provide a strong inductive bias to learn complex policies. Previous architectures like HIGhER combine the benefit of language-conditioning with Hindsight Experience Replay (HER) to deal with sparse rewards environments. Yet, like HER, HIGhER relies on an oracle predicate function to provide a feedback signal highlighting which linguistic description is valid for which state. This reliance on an oracle limits its application. Additionally, HIGhER only leverages the linguistic information contained in successful RL trajectories, thus hurting its final performance and data-efficiency. Without early successful trajectories, HIGhER is no better than DQN upon which it is built. In this paper, we propose the Emergent Textual Hindsight Experience Replay (ETHER) agent, which builds on HIGhER and addresses both of its limitations by means of (i) a discriminative visual referential game, commonly studied in the subfield of Emergent Communication (EC), used here as an unsupervised auxiliary task and (ii) a semantic grounding scheme to align the emergent language with the natural language of the instruction-following benchmark. We show that the referential game's agents make an artificial language emerge that is aligned with the natural-like language used to describe goals in the BabyAI benchmark and that it is expressive enough so as to also describe unsuccessful RL trajectories and thus provide feedback to the RL agent to leverage the linguistic, structured information contained in all trajectories. Our work shows that EC is a viable unsupervised auxiliary task for RL and provides missing pieces to make HER more widely applicable.
Visual Referential Games Further the Emergence of Disentangled Representations
Apr 27, 2023



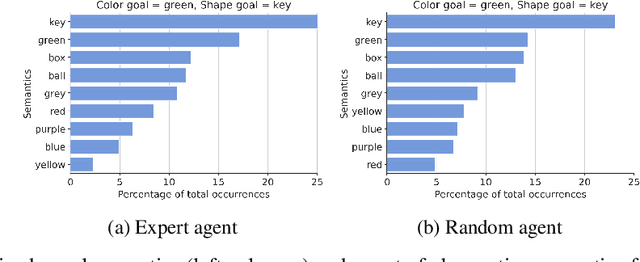
Natural languages are powerful tools wielded by human beings to communicate information. Among their desirable properties, compositionality has been the main focus in the context of referential games and variants, as it promises to enable greater systematicity to the agents which would wield it. The concept of disentanglement has been shown to be of paramount importance to learned representations that generalise well in deep learning, and is thought to be a necessary condition to enable systematicity. Thus, this paper investigates how do compositionality at the level of the emerging languages, disentanglement at the level of the learned representations, and systematicity relate to each other in the context of visual referential games. Firstly, we find that visual referential games that are based on the Obverter architecture outperforms state-of-the-art unsupervised learning approach in terms of many major disentanglement metrics. Secondly, we expand the previously proposed Positional Disentanglement (PosDis) metric for compositionality to (re-)incorporate some concerns pertaining to informativeness and completeness features found in the Mutual Information Gap (MIG) disentanglement metric it stems from. This extension allows for further discrimination between the different kind of compositional languages that emerge in the context of Obverter-based referential games, in a way that neither the referential game accuracy nor previous metrics were able to capture. Finally we investigate whether the resulting (emergent) systematicity, as measured by zero-shot compositional learning tests, correlates with any of the disentanglement and compositionality metrics proposed so far. Throughout the training process, statically significant correlation coefficients can be found both positive and negative depending on the moment of the measure.
Meta-Referential Games to Learn Compositional Learning Behaviours
Jul 16, 2022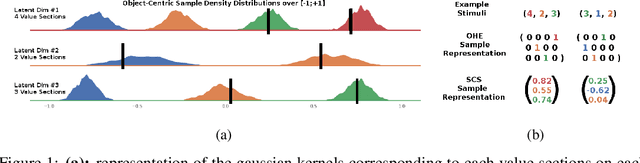

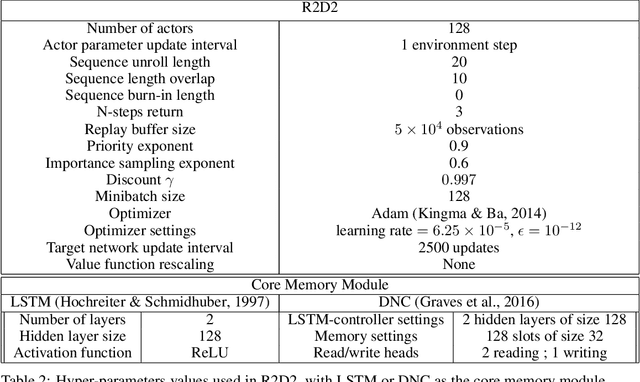
Human beings use compositionality to generalise from past experiences to actual or fictive, novel experiences. To do so, we separate our experiences into fundamental atomic components. These atomic components can then be recombined in novel ways to support our ability to imagine and engage with novel experiences. We frame this as the ability to learn to generalise compositionally. And, we will refer to behaviours making use of this ability as compositional learning behaviours (CLBs). A central problem to learning CLBs is the resolution of a binding problem (BP) (by learning to, firstly, segregate the supportive stimulus components from the observation of multiple stimuli, and then, combine them in a single episodic experience). While it is another feat of intelligence that human beings perform with ease, it is not the case for state-of-the-art artificial agents. Thus, in order to build artificial agents able to collaborate with human beings, we propose to develop a novel benchmark to investigate agents' abilities to exhibit CLBs by solving a domain-agnostic version of the BP. We take inspiration from the language emergence and grounding framework of referential games and propose a meta-learning extension of referential games, entitled Meta-Referential Games, and use this framework to build our benchmark, that we name Symbolic Behaviour Benchmark (S2B). While it has the potential to test for more symbolic behaviours, rather than solely CLBs, in the present paper, though, we solely focus on the single-agent language grounding task that tests for CLBs. We provide baseline results for it, using state-of-the-art RL agents, and show that our proposed benchmark is a compelling challenge that we hope will spur the research community towards developing more capable artificial agents.