 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Run-time Safety Monitors for Machine Learning Components
Jun 23, 2024



For machine learning components used as part of autonomous systems (AS) in carrying out critical tasks it is crucial that assurance of the models can be maintained in the face of post-deployment changes (such as changes in the operating environment of the system). A critical part of this is to be able to monitor when the performance of the model at runtime (as a result of changes) poses a safety risk to the system. This is a particularly difficult challenge when ground truth is unavailable at runtime. In this paper we introduce a process for creating safety monitors for ML components through the use of degraded datasets and machine learning. The safety monitor that is created is deployed to the AS in parallel to the ML component to provide a prediction of the safety risk associated with the model output. We demonstrate the viability of our approach through some initial experiments using publicly available speed sign datasets.
ETHER: Aligning Emergent Communication for Hindsight Experience Replay
Jul 28, 2023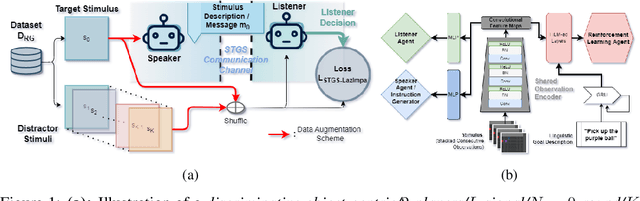

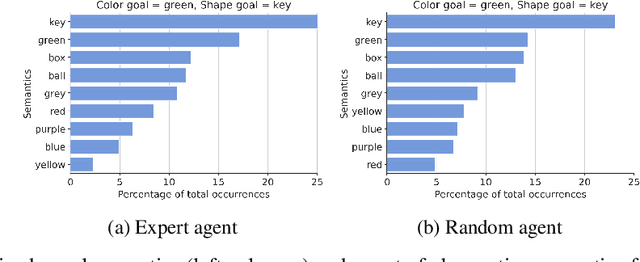

Natural language instruction following is paramount to enable collaboration between artificial agents and human beings. Natural language-conditioned reinforcement learning (RL) agents have shown how natural languages' properties, such as compositionality, can provide a strong inductive bias to learn complex policies. Previous architectures like HIGhER combine the benefit of language-conditioning with Hindsight Experience Replay (HER) to deal with sparse rewards environments. Yet, like HER, HIGhER relies on an oracle predicate function to provide a feedback signal highlighting which linguistic description is valid for which state. This reliance on an oracle limits its application. Additionally, HIGhER only leverages the linguistic information contained in successful RL trajectories, thus hurting its final performance and data-efficiency. Without early successful trajectories, HIGhER is no better than DQN upon which it is built. In this paper, we propose the Emergent Textual Hindsight Experience Replay (ETHER) agent, which builds on HIGhER and addresses both of its limitations by means of (i) a discriminative visual referential game, commonly studied in the subfield of Emergent Communication (EC), used here as an unsupervised auxiliary task and (ii) a semantic grounding scheme to align the emergent language with the natural language of the instruction-following benchmark. We show that the referential game's agents make an artificial language emerge that is aligned with the natural-like language used to describe goals in the BabyAI benchmark and that it is expressive enough so as to also describe unsuccessful RL trajectories and thus provide feedback to the RL agent to leverage the linguistic, structured information contained in all trajectories. Our work shows that EC is a viable unsupervised auxiliary task for RL and provides missing pieces to make HER more widely applicable.