 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeETHER: Aligning Emergent Communication for Hindsight Experience Replay
Jul 28, 2023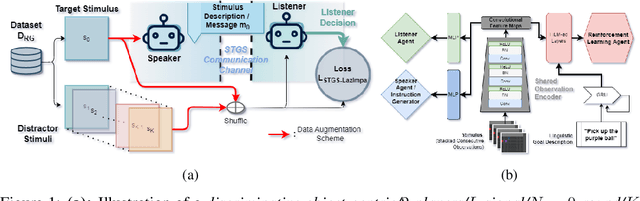


Natural language instruction following is paramount to enable collaboration between artificial agents and human beings. Natural language-conditioned reinforcement learning (RL) agents have shown how natural languages' properties, such as compositionality, can provide a strong inductive bias to learn complex policies. Previous architectures like HIGhER combine the benefit of language-conditioning with Hindsight Experience Replay (HER) to deal with sparse rewards environments. Yet, like HER, HIGhER relies on an oracle predicate function to provide a feedback signal highlighting which linguistic description is valid for which state. This reliance on an oracle limits its application. Additionally, HIGhER only leverages the linguistic information contained in successful RL trajectories, thus hurting its final performance and data-efficiency. Without early successful trajectories, HIGhER is no better than DQN upon which it is built. In this paper, we propose the Emergent Textual Hindsight Experience Replay (ETHER) agent, which builds on HIGhER and addresses both of its limitations by means of (i) a discriminative visual referential game, commonly studied in the subfield of Emergent Communication (EC), used here as an unsupervised auxiliary task and (ii) a semantic grounding scheme to align the emergent language with the natural language of the instruction-following benchmark. We show that the referential game's agents make an artificial language emerge that is aligned with the natural-like language used to describe goals in the BabyAI benchmark and that it is expressive enough so as to also describe unsuccessful RL trajectories and thus provide feedback to the RL agent to leverage the linguistic, structured information contained in all trajectories. Our work shows that EC is a viable unsupervised auxiliary task for RL and provides missing pieces to make HER more widely applicable.
Learning to Select SAT Encodings for Pseudo-Boolean and Linear Integer Constraints
Jul 18, 2023Many constraint satisfaction and optimisation problems can be solved effectively by encoding them as instances of the Boolean Satisfiability problem (SAT). However, even the simplest types of constraints have many encodings in the literature with widely varying performance, and the problem of selecting suitable encodings for a given problem instance is not trivial. We explore the problem of selecting encodings for pseudo-Boolean and linear constraints using a supervised machine learning approach. We show that it is possible to select encodings effectively using a standard set of features for constraint problems; however we obtain better performance with a new set of features specifically designed for the pseudo-Boolean and linear constraints. In fact, we achieve good results when selecting encodings for unseen problem classes. Our results compare favourably to AutoFolio when using the same feature set. We discuss the relative importance of instance features to the task of selecting the best encodings, and compare several variations of the machine learning method.
Visual Referential Games Further the Emergence of Disentangled Representations
Apr 27, 2023



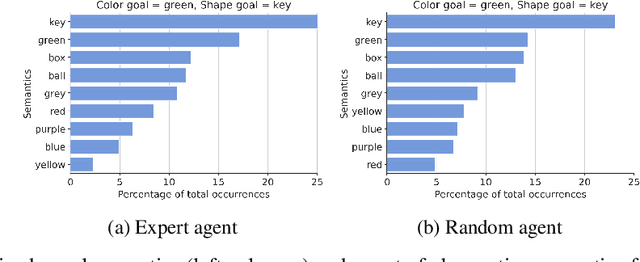
Natural languages are powerful tools wielded by human beings to communicate information. Among their desirable properties, compositionality has been the main focus in the context of referential games and variants, as it promises to enable greater systematicity to the agents which would wield it. The concept of disentanglement has been shown to be of paramount importance to learned representations that generalise well in deep learning, and is thought to be a necessary condition to enable systematicity. Thus, this paper investigates how do compositionality at the level of the emerging languages, disentanglement at the level of the learned representations, and systematicity relate to each other in the context of visual referential games. Firstly, we find that visual referential games that are based on the Obverter architecture outperforms state-of-the-art unsupervised learning approach in terms of many major disentanglement metrics. Secondly, we expand the previously proposed Positional Disentanglement (PosDis) metric for compositionality to (re-)incorporate some concerns pertaining to informativeness and completeness features found in the Mutual Information Gap (MIG) disentanglement metric it stems from. This extension allows for further discrimination between the different kind of compositional languages that emerge in the context of Obverter-based referential games, in a way that neither the referential game accuracy nor previous metrics were able to capture. Finally we investigate whether the resulting (emergent) systematicity, as measured by zero-shot compositional learning tests, correlates with any of the disentanglement and compositionality metrics proposed so far. Throughout the training process, statically significant correlation coefficients can be found both positive and negative depending on the moment of the measure.
Meta-Referential Games to Learn Compositional Learning Behaviours
Jul 16, 2022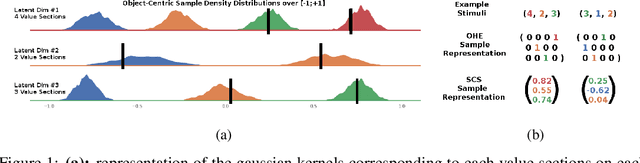

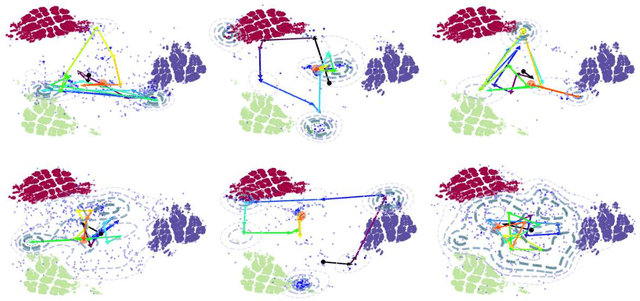
Human beings use compositionality to generalise from past experiences to actual or fictive, novel experiences. To do so, we separate our experiences into fundamental atomic components. These atomic components can then be recombined in novel ways to support our ability to imagine and engage with novel experiences. We frame this as the ability to learn to generalise compositionally. And, we will refer to behaviours making use of this ability as compositional learning behaviours (CLBs). A central problem to learning CLBs is the resolution of a binding problem (BP) (by learning to, firstly, segregate the supportive stimulus components from the observation of multiple stimuli, and then, combine them in a single episodic experience). While it is another feat of intelligence that human beings perform with ease, it is not the case for state-of-the-art artificial agents. Thus, in order to build artificial agents able to collaborate with human beings, we propose to develop a novel benchmark to investigate agents' abilities to exhibit CLBs by solving a domain-agnostic version of the BP. We take inspiration from the language emergence and grounding framework of referential games and propose a meta-learning extension of referential games, entitled Meta-Referential Games, and use this framework to build our benchmark, that we name Symbolic Behaviour Benchmark (S2B). While it has the potential to test for more symbolic behaviours, rather than solely CLBs, in the present paper, though, we solely focus on the single-agent language grounding task that tests for CLBs. We provide baseline results for it, using state-of-the-art RL agents, and show that our proposed benchmark is a compelling challenge that we hope will spur the research community towards developing more capable artificial agents.
Interactive Storytelling for Children: A Case-study of Design and Development Considerations for Ethical Conversational AI
Jul 20, 2021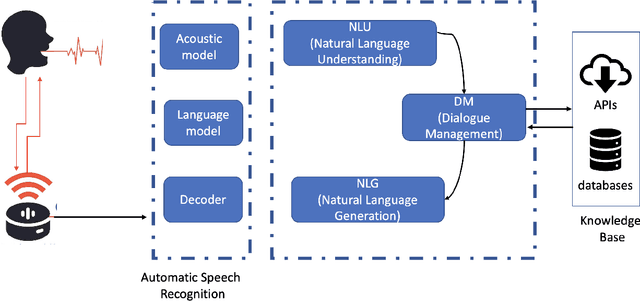

Conversational Artificial Intelligence (CAI) systems and Intelligent Personal Assistants (IPA), such as Alexa, Cortana, Google Home and Siri are becoming ubiquitous in our lives, including those of children, the implications of which is receiving increased attention, specifically with respect to the effects of these systems on children's cognitive, social and linguistic development. Recent advances address the implications of CAI with respect to privacy, safety, security, and access. However, there is a need to connect and embed the ethical and technical aspects in the design. Using a case-study of a research and development project focused on the use of CAI in storytelling for children, this paper reflects on the social context within a specific case of technology development, as substantiated and supported by argumentation from within the literature. It describes the decision making process behind the recommendations made on this case for their adoption in the creative industries. Further research that engages with developers and stakeholders in the ethics of storytelling through CAI is highlighted as a matter of urgency.
Quality Evolvability ES: Evolving Individuals With a Distribution of Well Performing and Diverse Offspring
Mar 19, 2021

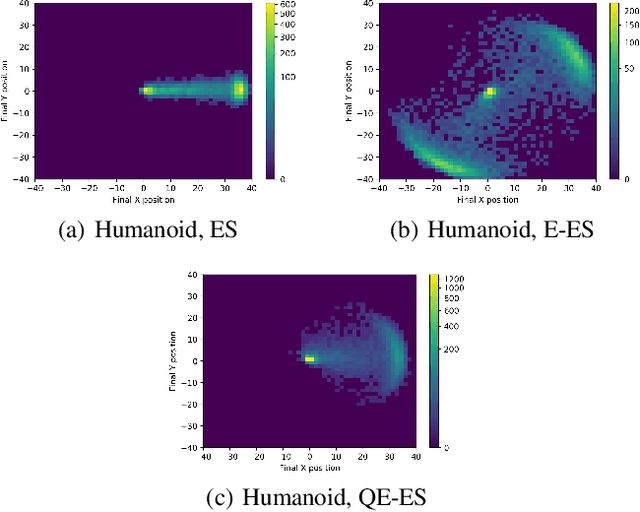
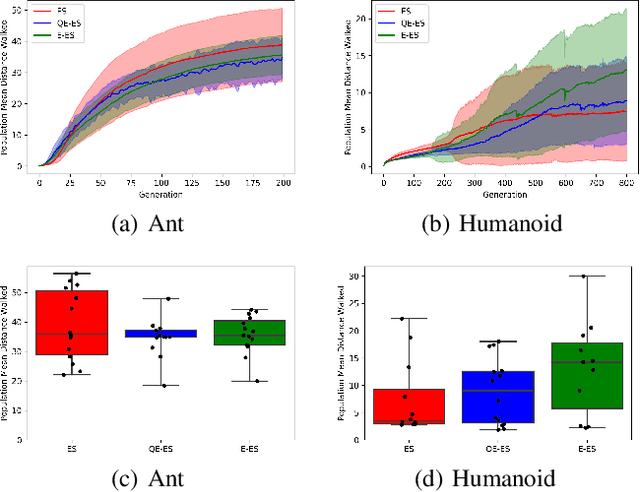
One of the most important lessons from the success of deep learning is that learned representations tend to perform much better at any task compared to representations we design by hand. Yet evolution of evolvability algorithms, which aim to automatically learn good genetic representations, have received relatively little attention, perhaps because of the large amount of computational power they require. The recent method Evolvability ES allows direct selection for evolvability with little computation. However, it can only be used to solve problems where evolvability and task performance are aligned. We propose Quality Evolvability ES, a method that simultaneously optimizes for task performance and evolvability and without this restriction. Our proposed approach Quality Evolvability has similar motivation to Quality Diversity algorithms, but with some important differences. While Quality Diversity aims to find an archive of diverse and well-performing, but potentially genetically distant individuals, Quality Evolvability aims to find a single individual with a diverse and well-performing distribution of offspring. By doing so Quality Evolvability is forced to discover more evolvable representations. We demonstrate on robotic locomotion control tasks that Quality Evolvability ES, similarly to Quality Diversity methods, can learn faster than objective-based methods and can handle deceptive problems.
On (Emergent) Systematic Generalisation and Compositionality in Visual Referential Games with Straight-Through Gumbel-Softmax Estimator
Dec 19, 2020


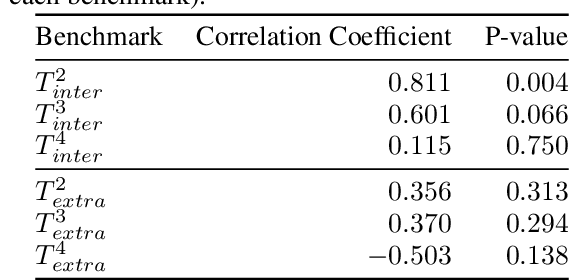
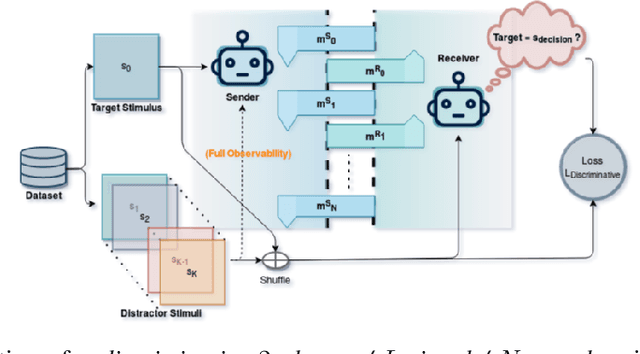
The drivers of compositionality in artificial languages that emerge when two (or more) agents play a non-visual referential game has been previously investigated using approaches based on the REINFORCE algorithm and the (Neural) Iterated Learning Model. Following the more recent introduction of the \textit{Straight-Through Gumbel-Softmax} (ST-GS) approach, this paper investigates to what extent the drivers of compositionality identified so far in the field apply in the ST-GS context and to what extent do they translate into (emergent) systematic generalisation abilities, when playing a visual referential game. Compositionality and the generalisation abilities of the emergent languages are assessed using topographic similarity and zero-shot compositional tests. Firstly, we provide evidence that the test-train split strategy significantly impacts the zero-shot compositional tests when dealing with visual stimuli, whilst it does not when dealing with symbolic ones. Secondly, empirical evidence shows that using the ST-GS approach with small batch sizes and an overcomplete communication channel improves compositionality in the emerging languages. Nevertheless, while shown robust with symbolic stimuli, the effect of the batch size is not so clear-cut when dealing with visual stimuli. Our results also show that not all overcomplete communication channels are created equal. Indeed, while increasing the maximum sentence length is found to be beneficial to further both compositionality and generalisation abilities, increasing the vocabulary size is found detrimental. Finally, a lack of correlation between the language compositionality at training-time and the agents' generalisation abilities is observed in the context of discriminative referential games with visual stimuli. This is similar to previous observations in the field using the generative variant with symbolic stimuli.
ReferentialGym: A Nomenclature and Framework for Language Emergence & Grounding in (Visual) Referential Games
Dec 17, 2020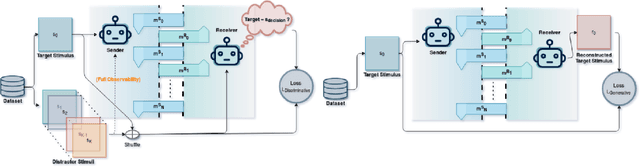

Natural languages are powerful tools wielded by human beings to communicate information and co-operate towards common goals. Their values lie in some main properties like compositionality, hierarchy and recurrent syntax, which computational linguists have been researching the emergence of in artificial languages induced by language games. Only relatively recently, the AI community has started to investigate language emergence and grounding working towards better human-machine interfaces. For instance, interactive/conversational AI assistants that are able to relate their vision to the ongoing conversation. This paper provides two contributions to this research field. Firstly, a nomenclature is proposed to understand the main initiatives in studying language emergence and grounding, accounting for the variations in assumptions and constraints. Secondly, a PyTorch based deep learning framework is introduced, entitled ReferentialGym, which is dedicated to furthering the exploration of language emergence and grounding. By providing baseline implementations of major algorithms and metrics, in addition to many different features and approaches, ReferentialGym attempts to ease the entry barrier to the field and provide the community with common implementations.
A Comparison of Self-Play Algorithms Under a Generalized Framework
Jun 08, 2020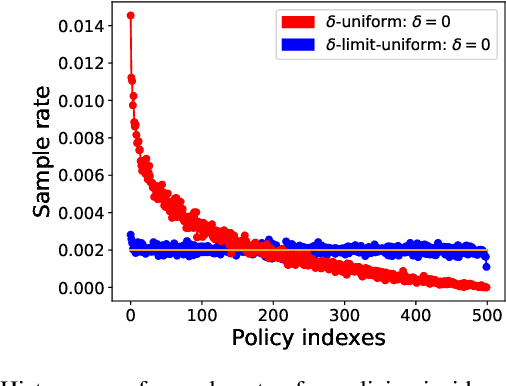
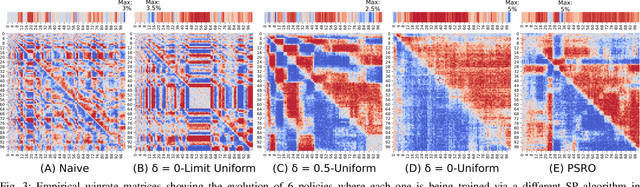
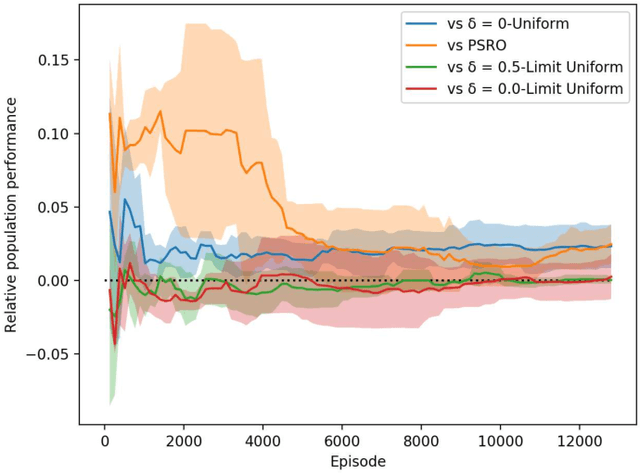
Throughout scientific history, overarching theoretical frameworks have allowed researchers to grow beyond personal intuitions and culturally biased theories. They allow to verify and replicate existing findings, and to link is connected results. The notion of self-play, albeit often cited in multiagent Reinforcement Learning, has never been grounded in a formal model. We present a formalized framework, with clearly defined assumptions, which encapsulates the meaning of self-play as abstracted from various existing self-play algorithms. This framework is framed as an approximation to a theoretical solution concept for multiagent training. On a simple environment, we qualitatively measure how well a subset of the captured self-play methods approximate this solution when paired with the famous PPO algorithm. We also provide insights on interpreting quantitative metrics of performance for self-play training. Our results indicate that, throughout training, various self-play definitions exhibit cyclic policy evolutions.
Metagame Autobalancing for Competitive Multiplayer Games
Jun 08, 2020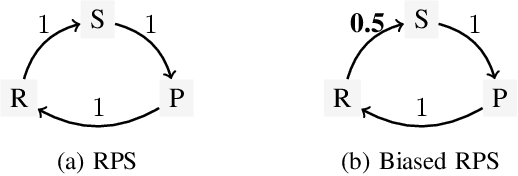
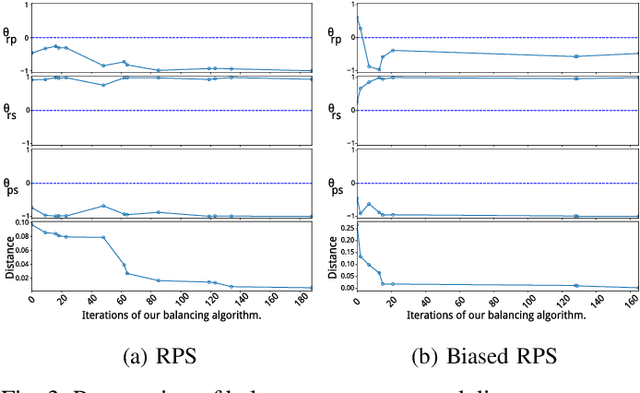

Automated game balancing has often focused on single-agent scenarios. In this paper we present a tool for balancing multi-player games during game design. Our approach requires a designer to construct an intuitive graphical representation of their meta-game target, representing the relative scores that high-level strategies (or decks, or character types) should experience. This permits more sophisticated balance targets to be defined beyond a simple requirement of equal win chances. We then find a parameterization of the game that meets this target using simulation-based optimization to minimize the distance to the target graph. We show the capabilities of this tool on examples inheriting from Rock-Paper-Scissors, and on a more complex asymmetric fighting game.