 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnvironment Descriptions for Usability and Generalisation in Reinforcement Learning
Dec 22, 2024
The majority of current reinforcement learning (RL) research involves training and deploying agents in environments that are implemented by engineers in general-purpose programming languages and more advanced frameworks such as CUDA or JAX. This makes the application of RL to novel problems of interest inaccessible to small organisations or private individuals with insufficient engineering expertise. This position paper argues that, to enable more widespread adoption of RL, it is important for the research community to shift focus towards methodologies where environments are described in user-friendly domain-specific or natural languages. Aside from improving the usability of RL, such language-based environment descriptions may also provide valuable context and boost the ability of trained agents to generalise to unseen environments within the set of all environments that can be described in any language of choice.
Games of Knightian Uncertainty as AGI testbeds
Jun 27, 2024

Arguably, for the latter part of the late 20th and early 21st centuries, games have been seen as the drosophila of AI. Games are a set of exciting testbeds, whose solutions (in terms of identifying optimal players) would lead to machines that would possess some form of general intelligence, or at the very least help us gain insights toward building intelligent machines. Following impressive successes in traditional board games like Go, Chess, and Poker, but also video games like the Atari 2600 collection, it is clear that this is not the case. Games have been attacked successfully, but we are nowhere near AGI developments (or, as harsher critics might say, useful AI developments!). In this short vision paper, we argue that for game research to become again relevant to the AGI pathway, we need to be able to address \textit{Knightian uncertainty} in the context of games, i.e. agents need to be able to adapt to rapid changes in game rules on the fly with no warning, no previous data, and no model access.
Robustness of Algorithms for Causal Structure Learning to Hyperparameter Choice
Oct 27, 2023



Hyperparameters play a critical role in machine learning. Hyperparameter tuning can make the difference between state-of-the-art and poor prediction performance for any algorithm, but it is particularly challenging for structure learning due to its unsupervised nature. As a result, hyperparameter tuning is often neglected in favour of using the default values provided by a particular implementation of an algorithm. While there have been numerous studies on performance evaluation of causal discovery algorithms, how hyperparameters affect individual algorithms, as well as the choice of the best algorithm for a specific problem, has not been studied in depth before. This work addresses this gap by investigating the influence of hyperparameters on causal structure learning tasks. Specifically, we perform an empirical evaluation of hyperparameter selection for some seminal learning algorithms on datasets of varying levels of complexity. We find that, while the choice of algorithm remains crucial to obtaining state-of-the-art performance, hyperparameter selection in ensemble settings strongly influences the choice of algorithm, in that a poor choice of hyperparameters can lead to analysts using algorithms which do not give state-of-the-art performance for their data.
Hyperparameter Tuning and Model Evaluation in Causal Effect Estimation
Mar 02, 2023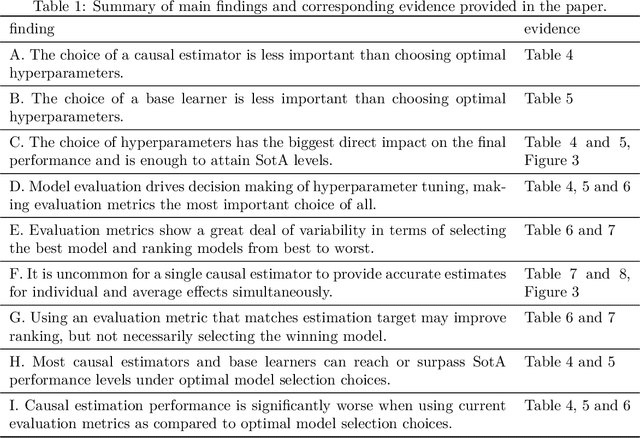
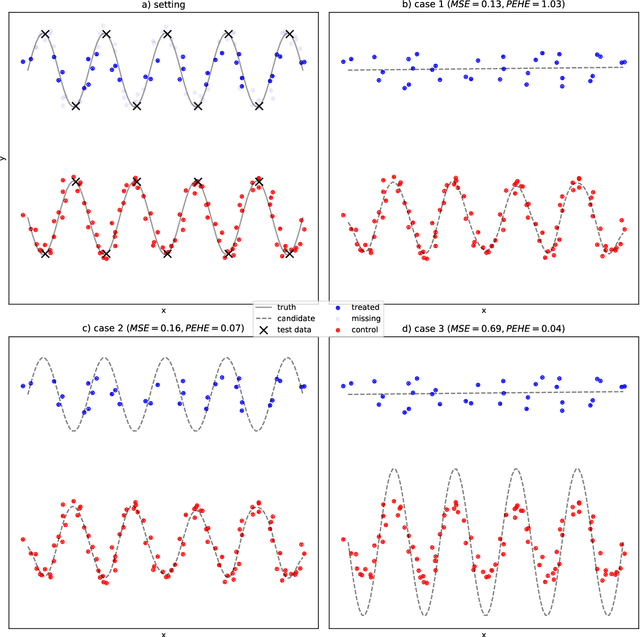
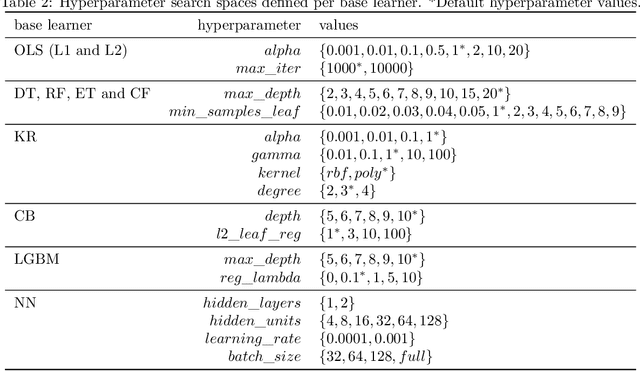
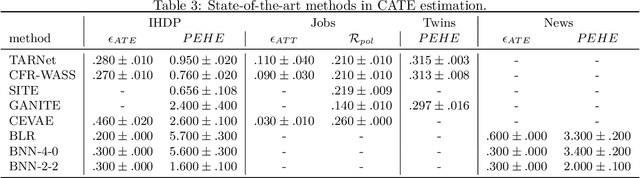
The performance of most causal effect estimators relies on accurate predictions of high-dimensional non-linear functions of the observed data. The remarkable flexibility of modern Machine Learning (ML) methods is perfectly suited to this task. However, data-driven hyperparameter tuning of ML methods requires effective model evaluation to avoid large errors in causal estimates, a task made more challenging because causal inference involves unavailable counterfactuals. Multiple performance-validation metrics have recently been proposed such that practitioners now not only have to make complex decisions about which causal estimators, ML learners and hyperparameters to choose, but also about which evaluation metric to use. This paper, motivated by unclear recommendations, investigates the interplay between the four different aspects of model evaluation for causal effect estimation. We develop a comprehensive experimental setup that involves many commonly used causal estimators, ML methods and evaluation approaches and apply it to four well-known causal inference benchmark datasets. Our results suggest that optimal hyperparameter tuning of ML learners is enough to reach state-of-the-art performance in effect estimation, regardless of estimators and learners. We conclude that most causal estimators are roughly equivalent in performance if tuned thoroughly enough. We also find hyperparameter tuning and model evaluation are much more important than causal estimators and ML methods. Finally, from the significant gap we find in estimation performance of popular evaluation metrics compared with optimal model selection choices, we call for more research into causal model evaluation to unlock the optimum performance not currently being delivered even by state-of-the-art procedures.
A Comparison of Self-Play Algorithms Under a Generalized Framework
Jun 08, 2020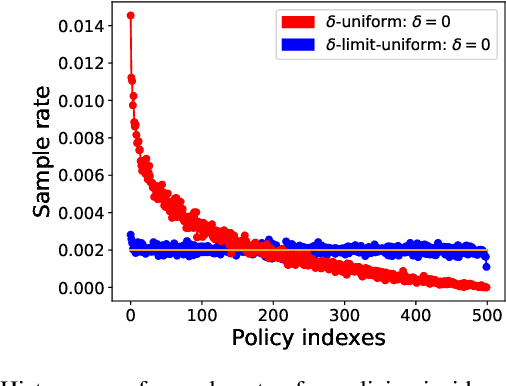
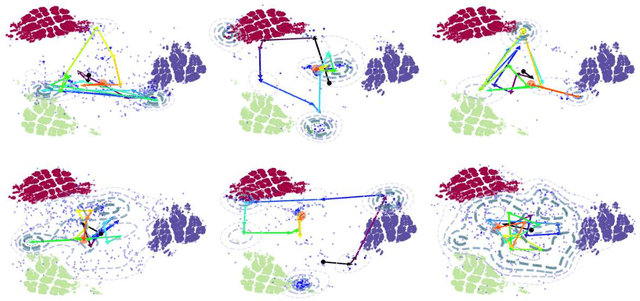
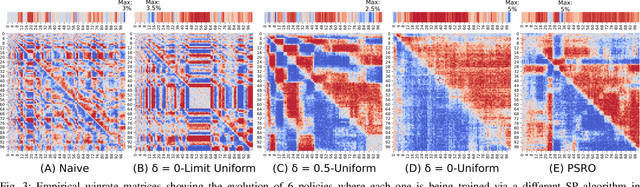
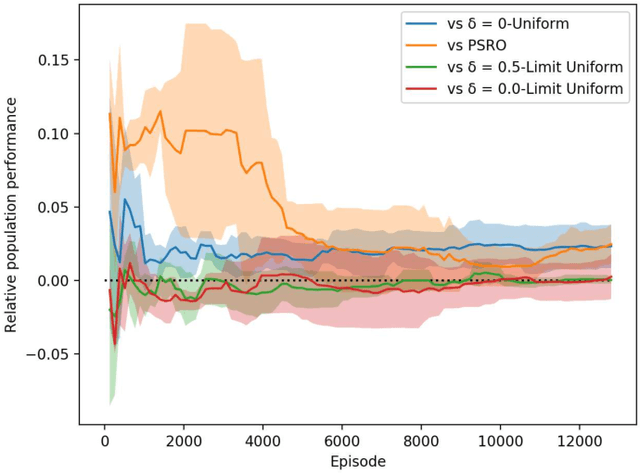
Throughout scientific history, overarching theoretical frameworks have allowed researchers to grow beyond personal intuitions and culturally biased theories. They allow to verify and replicate existing findings, and to link is connected results. The notion of self-play, albeit often cited in multiagent Reinforcement Learning, has never been grounded in a formal model. We present a formalized framework, with clearly defined assumptions, which encapsulates the meaning of self-play as abstracted from various existing self-play algorithms. This framework is framed as an approximation to a theoretical solution concept for multiagent training. On a simple environment, we qualitatively measure how well a subset of the captured self-play methods approximate this solution when paired with the famous PPO algorithm. We also provide insights on interpreting quantitative metrics of performance for self-play training. Our results indicate that, throughout training, various self-play definitions exhibit cyclic policy evolutions.
Deep Learning in Target Space
Jun 02, 2020
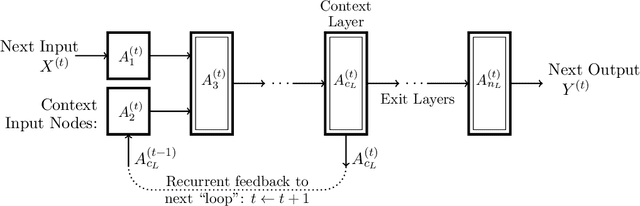
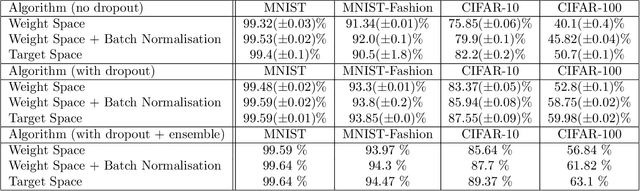

Deep learning uses neural networks which are parameterised by their weights. The neural networks are usually trained by tuning the weights to directly minimise a given loss function. In this paper we propose to reparameterise the weights into targets for the firing strengths of the individual nodes in the network. Given a set of targets, it is possible to calculate the weights which make the firing strengths best meet those targets. It is argued that using targets for training addresses the problem of exploding gradients, by a process which we call cascade untangling, and makes the loss-function surface smoother to traverse, and so leads to easier, faster training, and also potentially better generalisation, of the neural network. It also allows for easier learning of deeper and recurrent network structures. The necessary conversion of targets to weights comes at an extra computational expense, which is in many cases manageable. Learning in target space can be combined with existing neural-network optimisers, for extra gain. Experimental results show the speed of using target space, and examples of improved generalisation, for fully-connected networks and convolutional networks, and the ability to recall and process long time sequences and perform natural-language processing with recurrent networks.
Open Loop In Natura Economic Planning
May 14, 2020
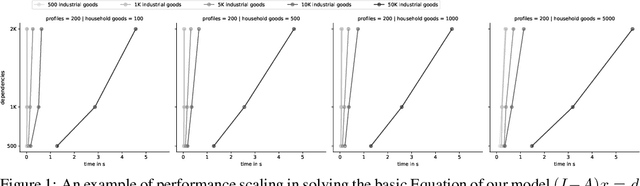


The debate between the optimal way of allocating societal surplus (i.e. products and services) has been raging, in one form or another, practically forever; following the collapse of the Soviet Union in 1991, the market became the only legitimate form of organisation -- there was no other alternative. Working within the tradition of Marx, Leontief, Kantorovich, Beer and Cockshott, we propose what we deem an automated planning system that aims to operate on unit level (e.g., factories and citizens), rather than on aggregate demand and sectors. We explain why it is both a viable and desirable alternative to current market conditions and position our solution within current societal structures. Our experiments show that it would be trivial to plan for up to 50K industrial goods and 5K final goods in commodity hardware.
Viewpoint: Artificial Intelligence and Labour
Mar 17, 2018
The welfare of modern societies has been intrinsically linked to wage labour. With some exceptions, the modern human has to sell her labour-power to be able reproduce biologically and socially. Thus, a lingering fear of technological unemployment features predominately as a theme among Artificial Intelligence researchers. In this short paper we show that, if past trends are anything to go by, this fear is irrational. On the contrary, we argue that the main problem humanity will be facing is the normalisation of extremely long working hours.