 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable AI for Data-Driven Design of High-Dimensional Predictive Studies
May 21, 2026Predictive modelling is important for health data analysis and data-driven clinical decision-making. However, predictive studies are challenging to design optimally by hand when tens or even hundreds of features require selection, transformation, or interaction modelling. While complex machine learning models offer high performance, their "black-box" nature limits the clinical trust, transparency, and interpretability required for decision-making. We developed and evaluated an Exploratory AI Recommender that provides data-driven recommendations to improve predictive performance of existing interpretable statistical models. The developed framework uses flexible AI modelling to capture complex data patterns and explainable AI techniques to translate the patterns into three recommendation types: feature exclusion, non-linear terms, and feature interactions. We evaluated the framework by comparing predictive performance of a baseline (i.e., no interactions or non-linear terms) Cox Proportional Hazards (CPH) model against an augmented CPH incorporating recommendations suggested by our method. The primary analysis predicts the time to the first occurrence of a fall or related injury in 245,614 patients. Our method recommended excluding 23 features, including non-linear terms for two features, and including 221 suggested feature interactions. The C-index improved from 0.805 (95% CI 0.798-0.812) to 0.815 (95% CI 0.809-0.822), and so did calibration (intercept: -0.006 to 0.003; slope: 1.063 to 0.950). All recommendations were supported by existing literature. The method also proved effective on two additional public datasets, demonstrating wider applicability. The proposed Exploratory AI Recommender demonstrates the potential of explainable AI and data-driven study design to improve the process of developing, and the performance of high-dimensional transparent predictive models.
A Causal Framework for Mitigating Data Shifts in Healthcare
Mar 13, 2026Developing predictive models that perform reliably across diverse patient populations and heterogeneous environments is a core aim of medical research. However, generalization is only possible if the learned model is robust to statistical differences between data used for training and data seen at the time and place of deployment. Domain generalization methods provide strategies to address data shifts, but each method comes with its own set of assumptions and trade-offs. To apply these methods in healthcare, we must understand how domain shifts arise, what assumptions we prefer to make, and what our design constraints are. This article proposes a causal framework for the design of predictive models to improve generalization. Causality provides a powerful language to characterize and understand diverse domain shifts, regardless of data modality. This allows us to pinpoint why models fail to generalize, leading to more principled strategies to prepare for and adapt to shifts. We recommend general mitigation strategies, discussing trade-offs and highlighting existing work. Our causality-based perspective offers a critical foundation for developing robust, interpretable, and clinically relevant AI solutions in healthcare, paving the way for reliable real-world deployment.
Rethinking Chronological Causal Discovery with Signal Processing
Feb 23, 2026Causal discovery problems use a set of observations to deduce causality between variables in the real world, typically to answer questions about biological or physical systems. These observations are often recorded at regular time intervals, determined by a user or a machine, depending on the experiment design. There is generally no guarantee that the timing of these recordings matches the timing of the underlying biological or physical events. In this paper, we examine the sensitivity of causal discovery methods to this potential mismatch. We consider empirical and theoretical evidence to understand how causal discovery performance is impacted by changes of sampling rate and window length. We demonstrate that both classical and recent causal discovery methods exhibit sensitivity to these hyperparameters, and we discuss how ideas from signal processing may help us understand these phenomena.
Games of Knightian Uncertainty as AGI testbeds
Jun 27, 2024

Arguably, for the latter part of the late 20th and early 21st centuries, games have been seen as the drosophila of AI. Games are a set of exciting testbeds, whose solutions (in terms of identifying optimal players) would lead to machines that would possess some form of general intelligence, or at the very least help us gain insights toward building intelligent machines. Following impressive successes in traditional board games like Go, Chess, and Poker, but also video games like the Atari 2600 collection, it is clear that this is not the case. Games have been attacked successfully, but we are nowhere near AGI developments (or, as harsher critics might say, useful AI developments!). In this short vision paper, we argue that for game research to become again relevant to the AGI pathway, we need to be able to address \textit{Knightian uncertainty} in the context of games, i.e. agents need to be able to adapt to rapid changes in game rules on the fly with no warning, no previous data, and no model access.
Robustness of Algorithms for Causal Structure Learning to Hyperparameter Choice
Oct 27, 2023



Hyperparameters play a critical role in machine learning. Hyperparameter tuning can make the difference between state-of-the-art and poor prediction performance for any algorithm, but it is particularly challenging for structure learning due to its unsupervised nature. As a result, hyperparameter tuning is often neglected in favour of using the default values provided by a particular implementation of an algorithm. While there have been numerous studies on performance evaluation of causal discovery algorithms, how hyperparameters affect individual algorithms, as well as the choice of the best algorithm for a specific problem, has not been studied in depth before. This work addresses this gap by investigating the influence of hyperparameters on causal structure learning tasks. Specifically, we perform an empirical evaluation of hyperparameter selection for some seminal learning algorithms on datasets of varying levels of complexity. We find that, while the choice of algorithm remains crucial to obtaining state-of-the-art performance, hyperparameter selection in ensemble settings strongly influences the choice of algorithm, in that a poor choice of hyperparameters can lead to analysts using algorithms which do not give state-of-the-art performance for their data.
Hyperparameter Tuning and Model Evaluation in Causal Effect Estimation
Mar 02, 2023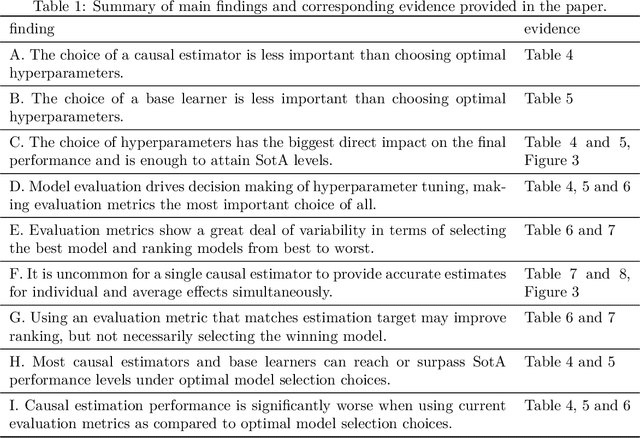
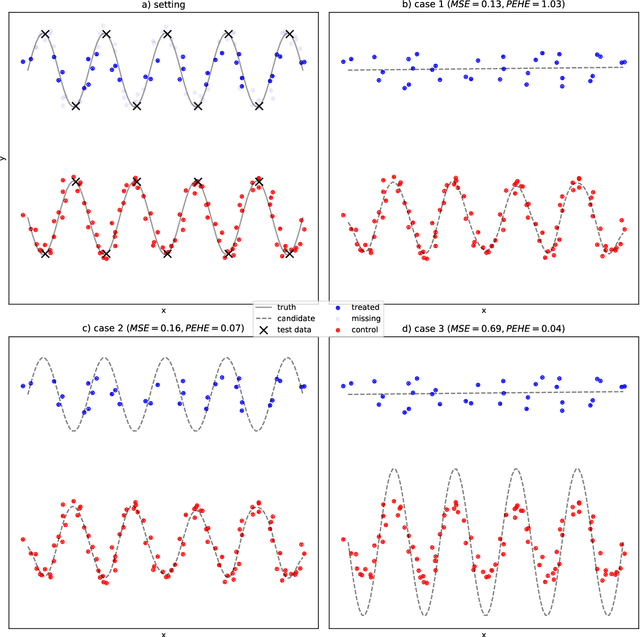
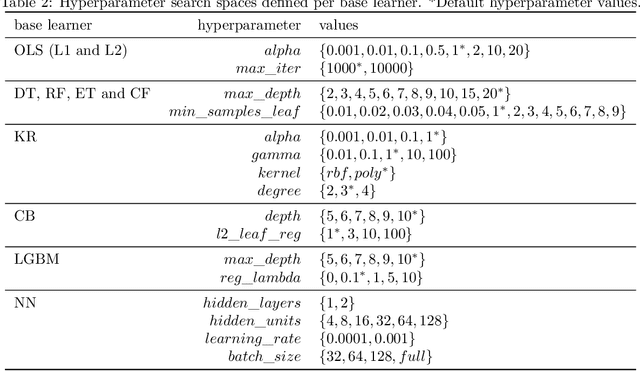
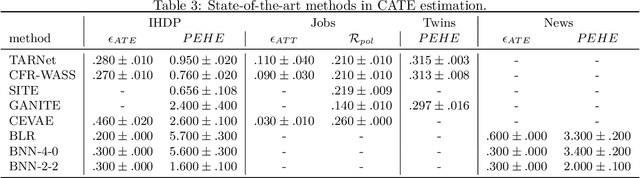
The performance of most causal effect estimators relies on accurate predictions of high-dimensional non-linear functions of the observed data. The remarkable flexibility of modern Machine Learning (ML) methods is perfectly suited to this task. However, data-driven hyperparameter tuning of ML methods requires effective model evaluation to avoid large errors in causal estimates, a task made more challenging because causal inference involves unavailable counterfactuals. Multiple performance-validation metrics have recently been proposed such that practitioners now not only have to make complex decisions about which causal estimators, ML learners and hyperparameters to choose, but also about which evaluation metric to use. This paper, motivated by unclear recommendations, investigates the interplay between the four different aspects of model evaluation for causal effect estimation. We develop a comprehensive experimental setup that involves many commonly used causal estimators, ML methods and evaluation approaches and apply it to four well-known causal inference benchmark datasets. Our results suggest that optimal hyperparameter tuning of ML learners is enough to reach state-of-the-art performance in effect estimation, regardless of estimators and learners. We conclude that most causal estimators are roughly equivalent in performance if tuned thoroughly enough. We also find hyperparameter tuning and model evaluation are much more important than causal estimators and ML methods. Finally, from the significant gap we find in estimation performance of popular evaluation metrics compared with optimal model selection choices, we call for more research into causal model evaluation to unlock the optimum performance not currently being delivered even by state-of-the-art procedures.
Undersmoothing Causal Estimators with Generative Trees
Mar 16, 2022



Inferring individualised treatment effects from observational data can unlock the potential for targeted interventions. It is, however, hard to infer these effects from observational data. One major problem that can arise is covariate shift where the data (outcome) conditional distribution remains the same but the covariate (input) distribution changes between the training and test set. In an observational data setting, this problem is materialised in control and treated units coming from different distributions. A common solution is to augment learning methods through reweighing schemes (e.g. propensity scores). These are needed due to model misspecification, but might hurt performance in the individual case. In this paper, we explore a novel generative tree based approach that tackles model misspecification directly, helping downstream estimators achieve better robustness. We show empirically that the choice of model class can indeed significantly affect the final performance and that reweighing methods can struggle in individualised effect estimation. Our proposed approach is competitive with reweighing methods on average treatment effects while performing significantly better on individualised treatment effects.