 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFor How Long Should We Be Punching? Learning Action Duration in Fighting Games
May 20, 2026Fighting games such as Street Fighter II present unique challenges to reinforcement learning (RL) agents due to their fast-paced, real-time nature. In most RL frameworks, agents are hard-coded to make decisions at a fixed interval, typically every frame or every N frames. Although this design ensures timely responses, it restricts the agent's ability to adjust its reaction timing. Acting every frame grants frame-perfect reflexes, which are unrealistic compared to human players, whereas longer fixed intervals reduce computational cost but hinder responsiveness. We consider an alternative decision-making framework in which the agent learns not only what action to take but also for how long to execute it. By jointly predicting both action and duration, the agent can dynamically adapt its responsiveness to different situations in the game. We implement this method using the open-source FightLadder environment with agents trained against scripted built-in bots, systematically testing different frame skip configurations to analyze their influence on performance, responsiveness, and learned behavior. Experiments show that learned timing can match the performance of well-chosen fixed frame skips and encourages repeatable action patterns, but does not ensure robustness on its own. In most cases, we see agents performing best with consistently high frame skip values (i.e., low responsiveness). This strategy makes it easier to learn exploitative strategies where the same action is repeated over and over, which the scripted bots appear to be susceptible to.
StratFormer: Adaptive Opponent Modeling and Exploitation in Imperfect-Information Games
Apr 28, 2026We present StratFormer, a transformer-based meta-agent that learns to simultaneously model and exploit opponents in imperfect-information games through a two-phase curriculum. The first phase trains an opponent modeling head to identify behavioral patterns from action histories while the agent plays a game-theoretic optimal (GTO) policy. The second phase progressively shifts the policy toward best-response (BR) exploitation, guided by a per-opponent regularization schedule tied to exploitability. Our architecture introduces dual-turn tokens -- feature vectors constructed at both agent and opponent decision points -- coupled with bucket-rate features that encode opponent tendencies across five strategic contexts. On Leduc Hold'em, a small poker variant with six cards and two betting rounds, we test against six opponent archetypes at two strength levels each, with exploitability ranging from 0.15 to 1.26 Big Blinds (BB) per hand. StratFormer achieves an average exploitation gain of +0.106 BB per hand over GTO, with peak gains of +0.821 against highly exploitable opponents, while maintaining near-equilibrium safety.
Generalized Proof-Number Monte-Carlo Tree Search
Jun 16, 2025This paper presents Generalized Proof-Number Monte-Carlo Tree Search: a generalization of recently proposed combinations of Proof-Number Search (PNS) with Monte-Carlo Tree Search (MCTS), which use (dis)proof numbers to bias UCB1-based Selection strategies towards parts of the search that are expected to be easily (dis)proven. We propose three core modifications of prior combinations of PNS with MCTS. First, we track proof numbers per player. This reduces code complexity in the sense that we no longer need disproof numbers, and generalizes the technique to be applicable to games with more than two players. Second, we propose and extensively evaluate different methods of using proof numbers to bias the selection strategy, achieving strong performance with strategies that are simpler to implement and compute. Third, we merge our technique with Score Bounded MCTS, enabling the algorithm to prove and leverage upper and lower bounds on scores - as opposed to only proving wins or not-wins. Experiments demonstrate substantial performance increases, reaching the range of 80% for 8 out of the 11 tested board games.
Environment Descriptions for Usability and Generalisation in Reinforcement Learning
Dec 22, 2024
The majority of current reinforcement learning (RL) research involves training and deploying agents in environments that are implemented by engineers in general-purpose programming languages and more advanced frameworks such as CUDA or JAX. This makes the application of RL to novel problems of interest inaccessible to small organisations or private individuals with insufficient engineering expertise. This position paper argues that, to enable more widespread adoption of RL, it is important for the research community to shift focus towards methodologies where environments are described in user-friendly domain-specific or natural languages. Aside from improving the usability of RL, such language-based environment descriptions may also provide valuable context and boost the ability of trained agents to generalise to unseen environments within the set of all environments that can be described in any language of choice.
Anytime Sequential Halving in Monte-Carlo Tree Search
Nov 11, 2024



Monte-Carlo Tree Search (MCTS) typically uses multi-armed bandit (MAB) strategies designed to minimize cumulative regret, such as UCB1, as its selection strategy. However, in the root node of the search tree, it is more sensible to minimize simple regret. Previous work has proposed using Sequential Halving as selection strategy in the root node, as, in theory, it performs better with respect to simple regret. However, Sequential Halving requires a budget of iterations to be predetermined, which is often impractical. This paper proposes an anytime version of the algorithm, which can be halted at any arbitrary time and still return a satisfactory result, while being designed such that it approximates the behavior of Sequential Halving. Empirical results in synthetic MAB problems and ten different board games demonstrate that the algorithm's performance is competitive with Sequential Halving and UCB1 (and their analogues in MCTS).
Exploring RL-based LLM Training for Formal Language Tasks with Programmed Rewards
Oct 22, 2024



Proximal Policy Optimization (PPO) is commonly used in Reinforcement Learning from Human Feedback to align large language models (LLMs) with downstream tasks. This paper investigates the feasibility of using PPO for direct reinforcement learning (RL) from explicitly programmed reward signals, as opposed to indirect learning from human feedback via an intermediary reward model. We focus on tasks expressed through formal languages, such as mathematics and programming, where explicit reward functions can be programmed to automatically assess the quality of generated outputs. We apply this approach to a sentiment alignment task, a simple arithmetic task, and a more complex game synthesis task. The sentiment alignment task replicates prior research and serves to validate our experimental setup. Our results show that pure RL-based training for the two formal language tasks is challenging, with success being limited even for the simple arithmetic task. We propose a novel batch-entropy regularization term to aid exploration, although training is not yet entirely stable. Our findings suggest that direct RL training of LLMs may be more suitable for relatively minor changes, such as alignment, than for learning new tasks altogether, even if an informative reward signal can be expressed programmatically.
GAVEL: Generating Games Via Evolution and Language Models
Jul 12, 2024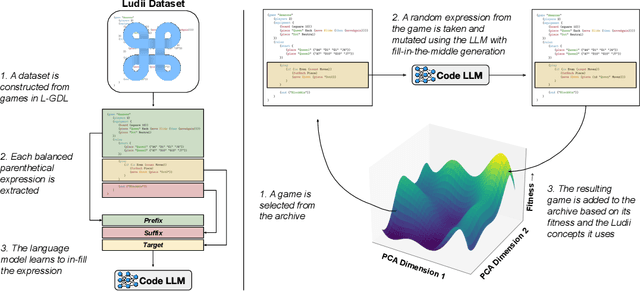

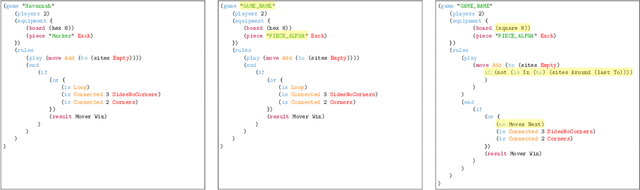

Automatically generating novel and interesting games is a complex task. Challenges include representing game rules in a computationally workable form, searching through the large space of potential games under most such representations, and accurately evaluating the originality and quality of previously unseen games. Prior work in automated game generation has largely focused on relatively restricted rule representations and relied on domain-specific heuristics. In this work, we explore the generation of novel games in the comparatively expansive Ludii game description language, which encodes the rules of over 1000 board games in a variety of styles and modes of play. We draw inspiration from recent advances in large language models and evolutionary computation in order to train a model that intelligently mutates and recombines games and mechanics expressed as code. We demonstrate both quantitatively and qualitatively that our approach is capable of generating new and interesting games, including in regions of the potential rules space not covered by existing games in the Ludii dataset. A sample of the generated games are available to play online through the Ludii portal.
Enhancements for Real-Time Monte-Carlo Tree Search in General Video Game Playing
Jul 03, 2024



General Video Game Playing (GVGP) is a field of Artificial Intelligence where agents play a variety of real-time video games that are unknown in advance. This limits the use of domain-specific heuristics. Monte-Carlo Tree Search (MCTS) is a search technique for game playing that does not rely on domain-specific knowledge. This paper discusses eight enhancements for MCTS in GVGP; Progressive History, N-Gram Selection Technique, Tree Reuse, Breadth-First Tree Initialization, Loss Avoidance, Novelty-Based Pruning, Knowledge-Based Evaluations, and Deterministic Game Detection. Some of these are known from existing literature, and are either extended or introduced in the context of GVGP, and some are novel enhancements for MCTS. Most enhancements are shown to provide statistically significant increases in win percentages when applied individually. When combined, they increase the average win percentage over sixty different games from 31.0% to 48.4% in comparison to a vanilla MCTS implementation, approaching a level that is competitive with the best agents of the GVG-AI competition in 2015.
* Green Open Access version of conference paper published in 2016
Games of Knightian Uncertainty as AGI testbeds
Jun 27, 2024

Arguably, for the latter part of the late 20th and early 21st centuries, games have been seen as the drosophila of AI. Games are a set of exciting testbeds, whose solutions (in terms of identifying optimal players) would lead to machines that would possess some form of general intelligence, or at the very least help us gain insights toward building intelligent machines. Following impressive successes in traditional board games like Go, Chess, and Poker, but also video games like the Atari 2600 collection, it is clear that this is not the case. Games have been attacked successfully, but we are nowhere near AGI developments (or, as harsher critics might say, useful AI developments!). In this short vision paper, we argue that for game research to become again relevant to the AGI pathway, we need to be able to address \textit{Knightian uncertainty} in the context of games, i.e. agents need to be able to adapt to rapid changes in game rules on the fly with no warning, no previous data, and no model access.
Towards a Characterisation of Monte-Carlo Tree Search Performance in Different Games
Jun 13, 2024


Many enhancements to Monte-Carlo Tree Search (MCTS) have been proposed over almost two decades of general game playing and other artificial intelligence research. However, our ability to characterise and understand which variants work well or poorly in which games is still lacking. This paper describes work on an initial dataset that we have built to make progress towards such an understanding: 268,386 plays among 61 different agents across 1494 distinct games. We describe a preliminary analysis and work on training predictive models on this dataset, as well as lessons learned and future plans for a new and improved version of the dataset.