 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScriptDoctor: Automatic Generation of PuzzleScript Games via Large Language Models and Tree Search
Jun 06, 2025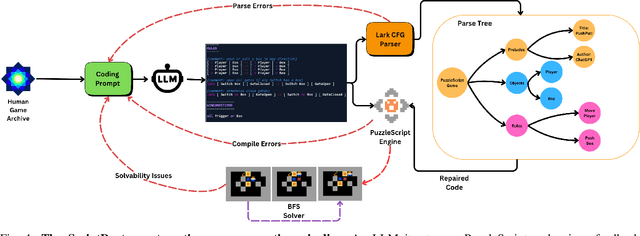


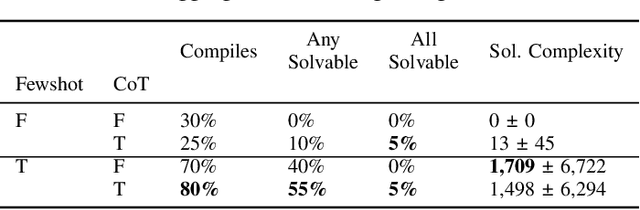
There is much interest in using large pre-trained models in Automatic Game Design (AGD), whether via the generation of code, assets, or more abstract conceptualization of design ideas. But so far this interest largely stems from the ad hoc use of such generative models under persistent human supervision. Much work remains to show how these tools can be integrated into longer-time-horizon AGD pipelines, in which systems interface with game engines to test generated content autonomously. To this end, we introduce ScriptDoctor, a Large Language Model (LLM)-driven system for automatically generating and testing games in PuzzleScript, an expressive but highly constrained description language for turn-based puzzle games over 2D gridworlds. ScriptDoctor generates and tests game design ideas in an iterative loop, where human-authored examples are used to ground the system's output, compilation errors from the PuzzleScript engine are used to elicit functional code, and search-based agents play-test generated games. ScriptDoctor serves as a concrete example of the potential of automated, open-ended LLM-based workflows in generating novel game content.
GAVEL: Generating Games Via Evolution and Language Models
Jul 12, 2024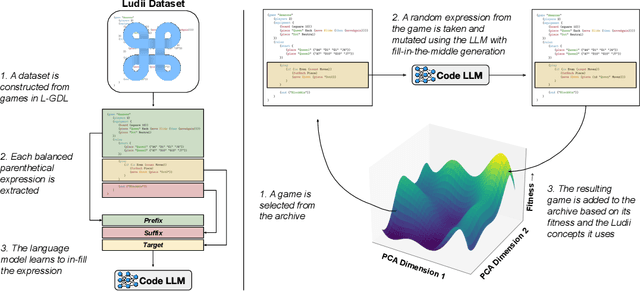

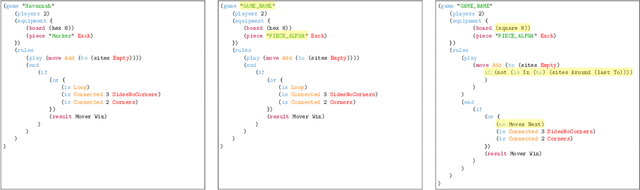

Automatically generating novel and interesting games is a complex task. Challenges include representing game rules in a computationally workable form, searching through the large space of potential games under most such representations, and accurately evaluating the originality and quality of previously unseen games. Prior work in automated game generation has largely focused on relatively restricted rule representations and relied on domain-specific heuristics. In this work, we explore the generation of novel games in the comparatively expansive Ludii game description language, which encodes the rules of over 1000 board games in a variety of styles and modes of play. We draw inspiration from recent advances in large language models and evolutionary computation in order to train a model that intelligently mutates and recombines games and mechanics expressed as code. We demonstrate both quantitatively and qualitatively that our approach is capable of generating new and interesting games, including in regions of the potential rules space not covered by existing games in the Ludii dataset. A sample of the generated games are available to play online through the Ludii portal.
Can Language Models Serve as Text-Based World Simulators?
Jun 10, 2024



Virtual environments play a key role in benchmarking advances in complex planning and decision-making tasks but are expensive and complicated to build by hand. Can current language models themselves serve as world simulators, correctly predicting how actions change different world states, thus bypassing the need for extensive manual coding? Our goal is to answer this question in the context of text-based simulators. Our approach is to build and use a new benchmark, called ByteSized32-State-Prediction, containing a dataset of text game state transitions and accompanying game tasks. We use this to directly quantify, for the first time, how well LLMs can serve as text-based world simulators. We test GPT-4 on this dataset and find that, despite its impressive performance, it is still an unreliable world simulator without further innovations. This work thus contributes both new insights into current LLM's capabilities and weaknesses, as well as a novel benchmark to track future progress as new models appear.
Goals as Reward-Producing Programs
May 21, 2024People are remarkably capable of generating their own goals, beginning with child's play and continuing into adulthood. Despite considerable empirical and computational work on goals and goal-oriented behavior, models are still far from capturing the richness of everyday human goals. Here, we bridge this gap by collecting a dataset of human-generated playful goals, modeling them as reward-producing programs, and generating novel human-like goals through program synthesis. Reward-producing programs capture the rich semantics of goals through symbolic operations that compose, add temporal constraints, and allow for program execution on behavioral traces to evaluate progress. To build a generative model of goals, we learn a fitness function over the infinite set of possible goal programs and sample novel goals with a quality-diversity algorithm. Human evaluators found that model-generated goals, when sampled from partitions of program space occupied by human examples, were indistinguishable from human-created games. We also discovered that our model's internal fitness scores predict games that are evaluated as more fun to play and more human-like.
Missed Connections: Lateral Thinking Puzzles for Large Language Models
Apr 17, 2024



The Connections puzzle published each day by the New York Times tasks players with dividing a bank of sixteen words into four groups of four words that each relate to a common theme. Solving the puzzle requires both common linguistic knowledge (i.e. definitions and typical usage) as well as, in many cases, lateral or abstract thinking. This is because the four categories ascend in complexity, with the most challenging category often requiring thinking about words in uncommon ways or as parts of larger phrases. We investigate the capacity for automated AI systems to play Connections and explore the game's potential as an automated benchmark for abstract reasoning and a way to measure the semantic information encoded by data-driven linguistic systems. In particular, we study both a sentence-embedding baseline and modern large language models (LLMs). We report their accuracy on the task, measure the impacts of chain-of-thought prompting, and discuss their failure modes. Overall, we find that the Connections task is challenging yet feasible, and a strong test-bed for future work.
Large Language Models and Games: A Survey and Roadmap
Feb 28, 2024Recent years have seen an explosive increase in research on large language models (LLMs), and accompanying public engagement on the topic. While starting as a niche area within natural language processing, LLMs have shown remarkable potential across a broad range of applications and domains, including games. This paper surveys the current state of the art across the various applications of LLMs in and for games, and identifies the different roles LLMs can take within a game. Importantly, we discuss underexplored areas and promising directions for future uses of LLMs in games and we reconcile the potential and limitations of LLMs within the games domain. As the first comprehensive survey and roadmap at the intersection of LLMs and games, we are hopeful that this paper will serve as the basis for groundbreaking research and innovation in this exciting new field.
ByteSized32: A Corpus and Challenge Task for Generating Task-Specific World Models Expressed as Text Games
May 24, 2023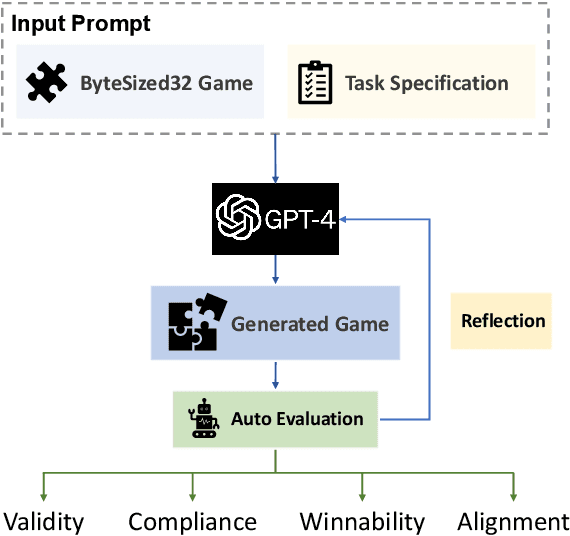
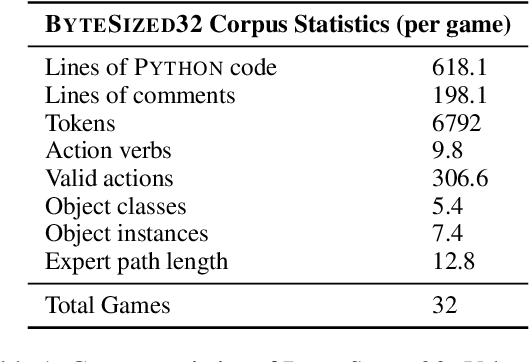

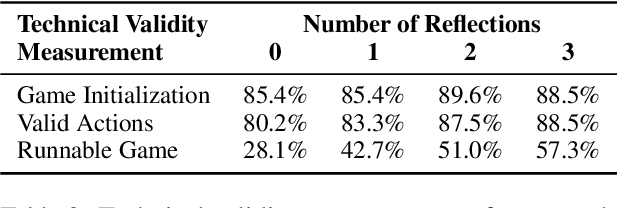
In this work we examine the ability of language models to generate explicit world models of scientific and common-sense reasoning tasks by framing this as a problem of generating text-based games. To support this, we introduce ByteSized32, a corpus of 32 highly-templated text games written in Python totaling 24k lines of code, each centered around a particular task, and paired with a set of 16 unseen text game specifications for evaluation. We propose a suite of automatic and manual metrics for assessing simulation validity, compliance with task specifications, playability, winnability, and alignment with the physical world. In a single-shot evaluation of GPT-4 on this simulation-as-code-generation task, we find it capable of producing runnable games in 27% of cases, highlighting the difficulty of this challenge task. We discuss areas of future improvement, including GPT-4's apparent capacity to perform well at simulating near canonical task solutions, with performance dropping off as simulations include distractors or deviate from canonical solutions in the action space.
Level Generation Through Large Language Models
Feb 11, 2023Large Language Models (LLMs) are powerful tools, capable of leveraging their training on natural language to write stories, generate code, and answer questions. But can they generate functional video game levels? Game levels, with their complex functional constraints and spatial relationships in more than one dimension, are very different from the kinds of data an LLM typically sees during training. Datasets of game levels are also hard to come by, potentially taxing the abilities of these data-hungry models. We investigate the use of LLMs to generate levels for the game Sokoban, finding that LLMs are indeed capable of doing so, and that their performance scales dramatically with dataset size. We also perform preliminary experiments on controlling LLM level generators and discuss promising areas for future work.