 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Literature-Driven Scientific Theories at Scale
Jan 22, 2026Contemporary automated scientific discovery has focused on agents for generating scientific experiments, while systems that perform higher-level scientific activities such as theory building remain underexplored. In this work, we formulate the problem of synthesizing theories consisting of qualitative and quantitative laws from large corpora of scientific literature. We study theory generation at scale, using 13.7k source papers to synthesize 2.9k theories, examining how generation using literature-grounding versus parametric knowledge, and accuracy-focused versus novelty-focused generation objectives change theory properties. Our experiments show that, compared to using parametric LLM memory for generation, our literature-supported method creates theories that are significantly better at both matching existing evidence and at predicting future results from 4.6k subsequently-written papers
AstaBench: Rigorous Benchmarking of AI Agents with a Scientific Research Suite
Oct 24, 2025AI agents hold the potential to revolutionize scientific productivity by automating literature reviews, replicating experiments, analyzing data, and even proposing new directions of inquiry; indeed, there are now many such agents, ranging from general-purpose "deep research" systems to specialized science-specific agents, such as AI Scientist and AIGS. Rigorous evaluation of these agents is critical for progress. Yet existing benchmarks fall short on several fronts: they (1) fail to provide holistic, product-informed measures of real-world use cases such as science research; (2) lack reproducible agent tools necessary for a controlled comparison of core agentic capabilities; (3) do not account for confounding variables such as model cost and tool access; (4) do not provide standardized interfaces for quick agent prototyping and evaluation; and (5) lack comprehensive baseline agents necessary to identify true advances. In response, we define principles and tooling for more rigorously benchmarking agents. Using these, we present AstaBench, a suite that provides the first holistic measure of agentic ability to perform scientific research, comprising 2400+ problems spanning the entire scientific discovery process and multiple scientific domains, and including many problems inspired by actual user requests to deployed Asta agents. Our suite comes with the first scientific research environment with production-grade search tools that enable controlled, reproducible evaluation, better accounting for confounders. Alongside, we provide a comprehensive suite of nine science-optimized classes of Asta agents and numerous baselines. Our extensive evaluation of 57 agents across 22 agent classes reveals several interesting findings, most importantly that despite meaningful progress on certain individual aspects, AI remains far from solving the challenge of science research assistance.
HARPA: A Testability-Driven, Literature-Grounded Framework for Research Ideation
Oct 01, 2025While there has been a surge of interest in automated scientific discovery (ASD), especially with the emergence of LLMs, it remains challenging for tools to generate hypotheses that are both testable and grounded in the scientific literature. Additionally, existing ideation tools are not adaptive to prior experimental outcomes. We developed HARPA to address these challenges by incorporating the ideation workflow inspired by human researchers. HARPA first identifies emerging research trends through literature mining, then explores hypothesis design spaces, and finally converges on precise, testable hypotheses by pinpointing research gaps and justifying design choices. Our evaluations show that HARPA-generated hypothesis-driven research proposals perform comparably to a strong baseline AI-researcher across most qualitative dimensions (e.g., specificity, novelty, overall quality), but achieve significant gains in feasibility(+0.78, p$<0.05$, bootstrap) and groundedness (+0.85, p$<0.01$, bootstrap) on a 10-point Likert scale. When tested with the ASD agent (CodeScientist), HARPA produced more successful executions (20 vs. 11 out of 40) and fewer failures (16 vs. 21 out of 40), showing that expert feasibility judgments track with actual execution success. Furthermore, to simulate how researchers continuously refine their understanding of what hypotheses are both testable and potentially interesting from experience, HARPA learns a reward model that scores new hypotheses based on prior experimental outcomes, achieving approx. a 28\% absolute gain over HARPA's untrained baseline scorer. Together, these methods represent a step forward in the field of AI-driven scientific discovery.
Matter-of-Fact: A Benchmark for Verifying the Feasibility of Literature-Supported Claims in Materials Science
Jun 04, 2025Contemporary approaches to assisted scientific discovery use language models to automatically generate large numbers of potential hypothesis to test, while also automatically generating code-based experiments to test those hypotheses. While hypotheses can be comparatively inexpensive to generate, automated experiments can be costly, particularly when run at scale (i.e. thousands of experiments). Developing the capacity to filter hypotheses based on their feasibility would allow discovery systems to run at scale, while increasing their likelihood of making significant discoveries. In this work we introduce Matter-of-Fact, a challenge dataset for determining the feasibility of hypotheses framed as claims. Matter-of-Fact includes 8.4k claims extracted from scientific articles spanning four high-impact contemporary materials science topics, including superconductors, semiconductors, batteries, and aerospace materials, while including qualitative and quantitative claims from theoretical, experimental, and code/simulation results. We show that strong baselines that include retrieval augmented generation over scientific literature and code generation fail to exceed 72% performance on this task (chance performance is 50%), while domain-expert verification suggests nearly all are solvable -- highlighting both the difficulty of this task for current models, and the potential to accelerate scientific discovery by making near-term progress.
From Models to Microtheories: Distilling a Model's Topical Knowledge for Grounded Question Answering
Dec 24, 2024



Recent reasoning methods (e.g., chain-of-thought, entailment reasoning) help users understand how language models (LMs) answer a single question, but they do little to reveal the LM's overall understanding, or "theory," about the question's topic, making it still hard to trust the model. Our goal is to materialize such theories - here called microtheories (a linguistic analog of logical microtheories) - as a set of sentences encapsulating an LM's core knowledge about a topic. These statements systematically work together to entail answers to a set of questions to both engender trust and improve performance. Our approach is to first populate a knowledge store with (model-generated) sentences that entail answers to training questions and then distill those down to a core microtheory that is concise, general, and non-redundant. We show that, when added to a general corpus (e.g., Wikipedia), microtheories can supply critical, topical information not necessarily present in the corpus, improving both a model's ability to ground its answers to verifiable knowledge (i.e., show how answers are systematically entailed by documents in the corpus, fully grounding up to +8% more answers), and the accuracy of those grounded answers (up to +8% absolute). We also show that, in a human evaluation in the medical domain, our distilled microtheories contain a significantly higher concentration of topically critical facts than the non-distilled knowledge store. Finally, we show we can quantify the coverage of a microtheory for a topic (characterized by a dataset) using a notion of $p$-relevance. Together, these suggest that microtheories are an efficient distillation of an LM's topic-relevant knowledge, that they can usefully augment existing corpora, and can provide both performance gains and an interpretable, verifiable window into the model's knowledge of a topic.
DISCOVERYWORLD: A Virtual Environment for Developing and Evaluating Automated Scientific Discovery Agents
Jun 10, 2024



Automated scientific discovery promises to accelerate progress across scientific domains. However, developing and evaluating an AI agent's capacity for end-to-end scientific reasoning is challenging as running real-world experiments is often prohibitively expensive or infeasible. In this work we introduce DISCOVERYWORLD, the first virtual environment for developing and benchmarking an agent's ability to perform complete cycles of novel scientific discovery. DISCOVERYWORLD contains a variety of different challenges, covering topics as diverse as radioisotope dating, rocket science, and proteomics, to encourage development of general discovery skills rather than task-specific solutions. DISCOVERYWORLD itself is an inexpensive, simulated, text-based environment (with optional 2D visual overlay). It includes 120 different challenge tasks, spanning eight topics each with three levels of difficulty and several parametric variations. Each task requires an agent to form hypotheses, design and run experiments, analyze results, and act on conclusions. DISCOVERYWORLD further provides three automatic metrics for evaluating performance, based on (a) task completion, (b) task-relevant actions taken, and (c) the discovered explanatory knowledge. We find that strong baseline agents, that perform well in prior published environments, struggle on most DISCOVERYWORLD tasks, suggesting that DISCOVERYWORLD captures some of the novel challenges of discovery, and thus that DISCOVERYWORLD may help accelerate near-term development and assessment of scientific discovery competency in agents. Code available at: www.github.com/allenai/discoveryworld
Can Language Models Serve as Text-Based World Simulators?
Jun 10, 2024



Virtual environments play a key role in benchmarking advances in complex planning and decision-making tasks but are expensive and complicated to build by hand. Can current language models themselves serve as world simulators, correctly predicting how actions change different world states, thus bypassing the need for extensive manual coding? Our goal is to answer this question in the context of text-based simulators. Our approach is to build and use a new benchmark, called ByteSized32-State-Prediction, containing a dataset of text game state transitions and accompanying game tasks. We use this to directly quantify, for the first time, how well LLMs can serve as text-based world simulators. We test GPT-4 on this dataset and find that, despite its impressive performance, it is still an unreliable world simulator without further innovations. This work thus contributes both new insights into current LLM's capabilities and weaknesses, as well as a novel benchmark to track future progress as new models appear.
PDDLEGO: Iterative Planning in Textual Environments
May 30, 2024Planning in textual environments have been shown to be a long-standing challenge even for current models. A recent, promising line of work uses LLMs to generate a formal representation of the environment that can be solved by a symbolic planner. However, existing methods rely on a fully-observed environment where all entity states are initially known, so a one-off representation can be constructed, leading to a complete plan. In contrast, we tackle partially-observed environments where there is initially no sufficient information to plan for the end-goal. We propose PDDLEGO that iteratively construct a planning representation that can lead to a partial plan for a given sub-goal. By accomplishing the sub-goal, more information is acquired to augment the representation, eventually achieving the end-goal. We show that plans produced by few-shot PDDLEGO are 43% more efficient than generating plans end-to-end on the Coin Collector simulation, with strong performance (98%) on the more complex Cooking World simulation where end-to-end LLMs fail to generate coherent plans (4%).
Enhancing Systematic Decompositional Natural Language Inference Using Informal Logic
Feb 27, 2024Contemporary language models enable new opportunities for structured reasoning with text, such as the construction and evaluation of intuitive, proof-like textual entailment trees without relying on brittle formal logic. However, progress in this direction has been hampered by a long-standing lack of a clear protocol for determining what valid compositional entailment is. This absence causes noisy datasets and limited performance gains by modern neuro-symbolic engines. To address these problems, we formulate a consistent and theoretically grounded approach to annotating decompositional entailment datasets, and evaluate its impact on LLM-based textual inference. We find that our resulting dataset, RDTE (Recognizing Decompositional Textual Entailment), has a substantially higher internal consistency (+9%) than prior decompositional entailment datasets, suggesting that RDTE is a significant step forward in the long-standing problem of forming a clear protocol for discerning entailment. We also find that training an RDTE-oriented entailment classifier via knowledge distillation and employing it in a modern neuro-symbolic reasoning engine significantly improves results (both accuracy and proof quality) over other entailment classifier baselines, illustrating the practical benefit of this advance for textual inference.
Self-Supervised Behavior Cloned Transformers are Path Crawlers for Text Games
Dec 07, 2023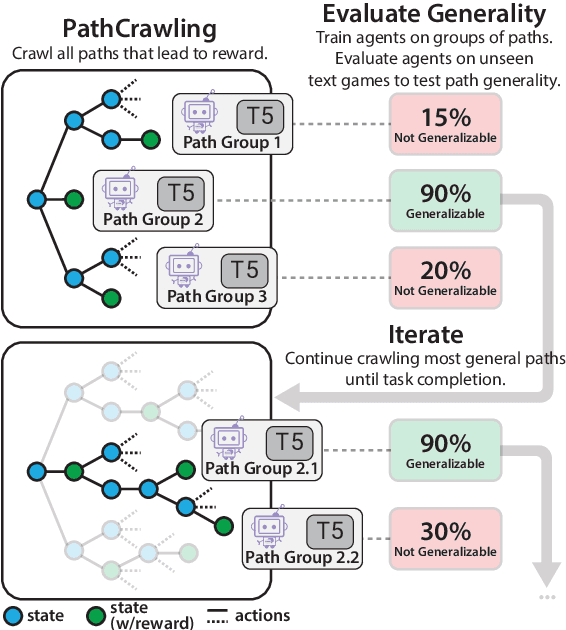
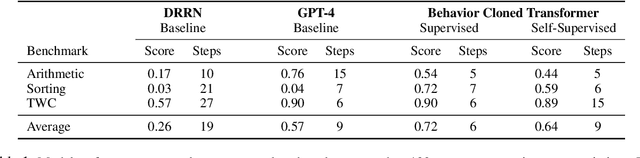
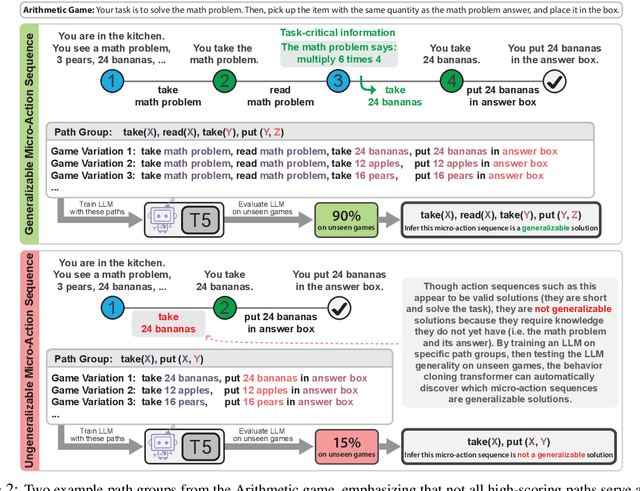

In this work, we introduce a self-supervised behavior cloning transformer for text games, which are challenging benchmarks for multi-step reasoning in virtual environments. Traditionally, Behavior Cloning Transformers excel in such tasks but rely on supervised training data. Our approach auto-generates training data by exploring trajectories (defined by common macro-action sequences) that lead to reward within the games, while determining the generality and utility of these trajectories by rapidly training small models then evaluating their performance on unseen development games. Through empirical analysis, we show our method consistently uncovers generalizable training data, achieving about 90\% performance of supervised systems across three benchmark text games.