 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAstaBench: Rigorous Benchmarking of AI Agents with a Scientific Research Suite
Oct 24, 2025AI agents hold the potential to revolutionize scientific productivity by automating literature reviews, replicating experiments, analyzing data, and even proposing new directions of inquiry; indeed, there are now many such agents, ranging from general-purpose "deep research" systems to specialized science-specific agents, such as AI Scientist and AIGS. Rigorous evaluation of these agents is critical for progress. Yet existing benchmarks fall short on several fronts: they (1) fail to provide holistic, product-informed measures of real-world use cases such as science research; (2) lack reproducible agent tools necessary for a controlled comparison of core agentic capabilities; (3) do not account for confounding variables such as model cost and tool access; (4) do not provide standardized interfaces for quick agent prototyping and evaluation; and (5) lack comprehensive baseline agents necessary to identify true advances. In response, we define principles and tooling for more rigorously benchmarking agents. Using these, we present AstaBench, a suite that provides the first holistic measure of agentic ability to perform scientific research, comprising 2400+ problems spanning the entire scientific discovery process and multiple scientific domains, and including many problems inspired by actual user requests to deployed Asta agents. Our suite comes with the first scientific research environment with production-grade search tools that enable controlled, reproducible evaluation, better accounting for confounders. Alongside, we provide a comprehensive suite of nine science-optimized classes of Asta agents and numerous baselines. Our extensive evaluation of 57 agents across 22 agent classes reveals several interesting findings, most importantly that despite meaningful progress on certain individual aspects, AI remains far from solving the challenge of science research assistance.
HARPA: A Testability-Driven, Literature-Grounded Framework for Research Ideation
Oct 01, 2025While there has been a surge of interest in automated scientific discovery (ASD), especially with the emergence of LLMs, it remains challenging for tools to generate hypotheses that are both testable and grounded in the scientific literature. Additionally, existing ideation tools are not adaptive to prior experimental outcomes. We developed HARPA to address these challenges by incorporating the ideation workflow inspired by human researchers. HARPA first identifies emerging research trends through literature mining, then explores hypothesis design spaces, and finally converges on precise, testable hypotheses by pinpointing research gaps and justifying design choices. Our evaluations show that HARPA-generated hypothesis-driven research proposals perform comparably to a strong baseline AI-researcher across most qualitative dimensions (e.g., specificity, novelty, overall quality), but achieve significant gains in feasibility(+0.78, p$<0.05$, bootstrap) and groundedness (+0.85, p$<0.01$, bootstrap) on a 10-point Likert scale. When tested with the ASD agent (CodeScientist), HARPA produced more successful executions (20 vs. 11 out of 40) and fewer failures (16 vs. 21 out of 40), showing that expert feasibility judgments track with actual execution success. Furthermore, to simulate how researchers continuously refine their understanding of what hypotheses are both testable and potentially interesting from experience, HARPA learns a reward model that scores new hypotheses based on prior experimental outcomes, achieving approx. a 28\% absolute gain over HARPA's untrained baseline scorer. Together, these methods represent a step forward in the field of AI-driven scientific discovery.
HypER: Literature-grounded Hypothesis Generation and Distillation with Provenance
Jun 15, 2025



Large Language models have demonstrated promising performance in research ideation across scientific domains. Hypothesis development, the process of generating a highly specific declarative statement connecting a research idea with empirical validation, has received relatively less attention. Existing approaches trivially deploy retrieval augmentation and focus only on the quality of the final output ignoring the underlying reasoning process behind ideation. We present $\texttt{HypER}$ ($\textbf{Hyp}$othesis Generation with $\textbf{E}$xplanation and $\textbf{R}$easoning), a small language model (SLM) trained for literature-guided reasoning and evidence-based hypothesis generation. $\texttt{HypER}$ is trained in a multi-task setting to discriminate between valid and invalid scientific reasoning chains in presence of controlled distractions. We find that $\texttt{HypER}$ outperformes the base model, distinguishing valid from invalid reasoning chains (+22\% average absolute F1), generates better evidence-grounded hypotheses (0.327 vs. 0.305 base model) with high feasibility and impact as judged by human experts ($>$3.5 on 5-point Likert scale).
Med-EASi: Finely Annotated Dataset and Models for Controllable Simplification of Medical Texts
Feb 17, 2023
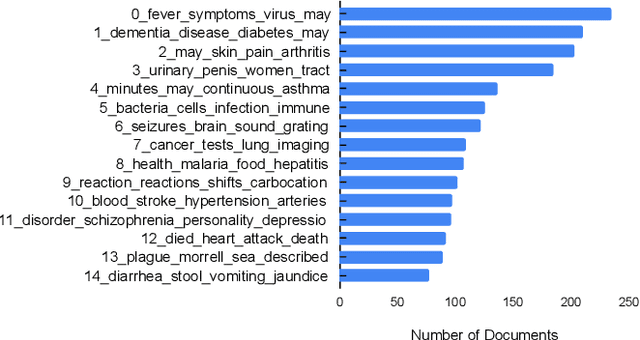

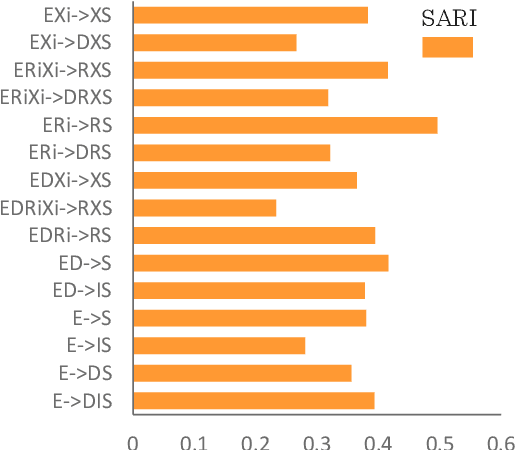
Automatic medical text simplification can assist providers with patient-friendly communication and make medical texts more accessible, thereby improving health literacy. But curating a quality corpus for this task requires the supervision of medical experts. In this work, we present $\textbf{Med-EASi}$ ($\underline{\textbf{Med}}$ical dataset for $\underline{\textbf{E}}$laborative and $\underline{\textbf{A}}$bstractive $\underline{\textbf{Si}}$mplification), a uniquely crowdsourced and finely annotated dataset for supervised simplification of short medical texts. Its $\textit{expert-layman-AI collaborative}$ annotations facilitate $\textit{controllability}$ over text simplification by marking four kinds of textual transformations: elaboration, replacement, deletion, and insertion. To learn medical text simplification, we fine-tune T5-large with four different styles of input-output combinations, leading to two control-free and two controllable versions of the model. We add two types of $\textit{controllability}$ into text simplification, by using a multi-angle training approach: $\textit{position-aware}$, which uses in-place annotated inputs and outputs, and $\textit{position-agnostic}$, where the model only knows the contents to be edited, but not their positions. Our results show that our fine-grained annotations improve learning compared to the unannotated baseline. Furthermore, $\textit{position-aware}$ control generates better simplification than the $\textit{position-agnostic}$ one. The data and code are available at https://github.com/Chandrayee/CTRL-SIMP.