 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAstaBench: Rigorous Benchmarking of AI Agents with a Scientific Research Suite
Oct 24, 2025AI agents hold the potential to revolutionize scientific productivity by automating literature reviews, replicating experiments, analyzing data, and even proposing new directions of inquiry; indeed, there are now many such agents, ranging from general-purpose "deep research" systems to specialized science-specific agents, such as AI Scientist and AIGS. Rigorous evaluation of these agents is critical for progress. Yet existing benchmarks fall short on several fronts: they (1) fail to provide holistic, product-informed measures of real-world use cases such as science research; (2) lack reproducible agent tools necessary for a controlled comparison of core agentic capabilities; (3) do not account for confounding variables such as model cost and tool access; (4) do not provide standardized interfaces for quick agent prototyping and evaluation; and (5) lack comprehensive baseline agents necessary to identify true advances. In response, we define principles and tooling for more rigorously benchmarking agents. Using these, we present AstaBench, a suite that provides the first holistic measure of agentic ability to perform scientific research, comprising 2400+ problems spanning the entire scientific discovery process and multiple scientific domains, and including many problems inspired by actual user requests to deployed Asta agents. Our suite comes with the first scientific research environment with production-grade search tools that enable controlled, reproducible evaluation, better accounting for confounders. Alongside, we provide a comprehensive suite of nine science-optimized classes of Asta agents and numerous baselines. Our extensive evaluation of 57 agents across 22 agent classes reveals several interesting findings, most importantly that despite meaningful progress on certain individual aspects, AI remains far from solving the challenge of science research assistance.
SciArena: An Open Evaluation Platform for Foundation Models in Scientific Literature Tasks
Jul 01, 2025
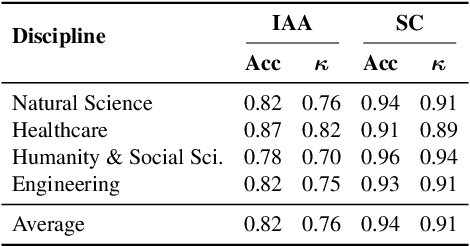

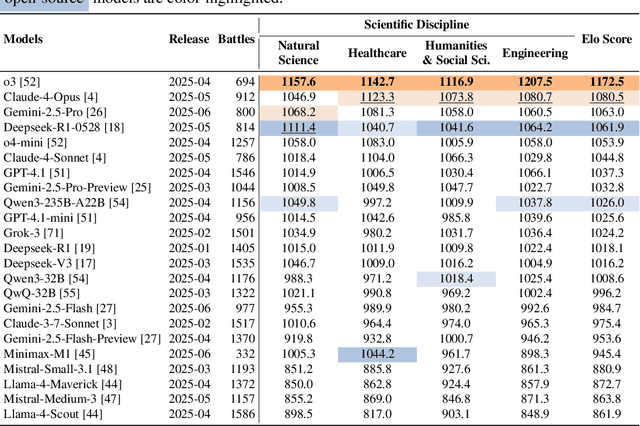
We present SciArena, an open and collaborative platform for evaluating foundation models on scientific literature tasks. Unlike traditional benchmarks for scientific literature understanding and synthesis, SciArena engages the research community directly, following the Chatbot Arena evaluation approach of community voting on model comparisons. By leveraging collective intelligence, SciArena offers a community-driven evaluation of model performance on open-ended scientific tasks that demand literature-grounded, long-form responses. The platform currently supports 23 open-source and proprietary foundation models and has collected over 13,000 votes from trusted researchers across diverse scientific domains. We analyze the data collected so far and confirm that the submitted questions are diverse, aligned with real-world literature needs, and that participating researchers demonstrate strong self-consistency and inter-annotator agreement in their evaluations. We discuss the results and insights based on the model ranking leaderboard. To further promote research in building model-based automated evaluation systems for literature tasks, we release SciArena-Eval, a meta-evaluation benchmark based on our collected preference data. The benchmark measures the accuracy of models in judging answer quality by comparing their pairwise assessments with human votes. Our experiments highlight the benchmark's challenges and emphasize the need for more reliable automated evaluation methods.
Re-evaluating Automatic LLM System Ranking for Alignment with Human Preference
Dec 31, 2024
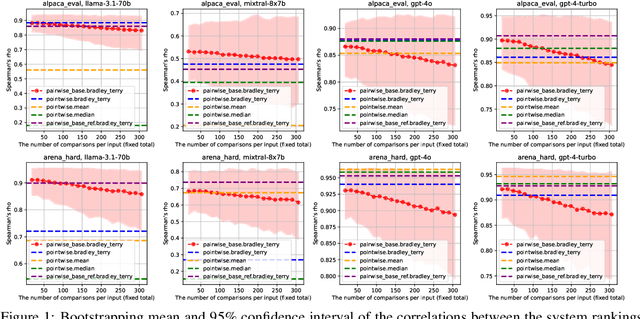
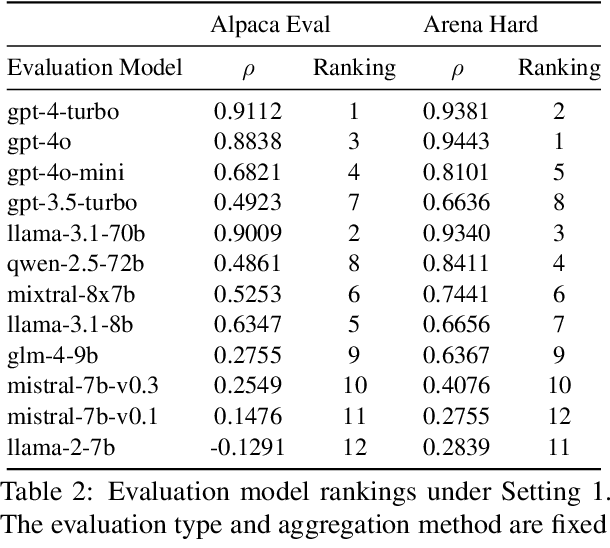
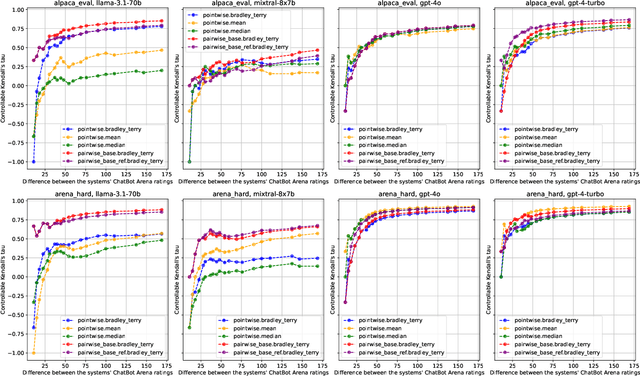
Evaluating and ranking the capabilities of different LLMs is crucial for understanding their performance and alignment with human preferences. Due to the high cost and time-consuming nature of human evaluations, an automatic LLM bencher (i.e., an automatic evaluation framework that aims to rank LLMs based on their alignment with human preferences) is indispensable. An automatic LLM bencher consists of four components: the input set (e.g., a user instruction), the evaluation model (e.g., an LLM), the evaluation type (e.g., pairwise comparison), and the aggregation method (e.g., the ELO rating system). However, previous work has not thoroughly explored how to select these components or how their different combinations influence the results. In this work, through controlled experiments, we provide a series of recommendations on how to choose each component to better automate the evaluation of LLMs. Furthermore, we discovered that when evaluating LLMs with similar performance, the performance of the automatic LLM bencher declines sharply, underscoring the limitations of current benchers and calling for future work. Lastly, we found that the evaluation models' performance at the instance level (e.g., the accuracy of selecting the best output) does not always align with their effectiveness when used as a component of a bencher, highlighting the importance of dedicated system-level evaluation of benchers.
Cocoa: Co-Planning and Co-Execution with AI Agents
Dec 14, 2024



We present Cocoa, a system that implements a novel interaction design pattern -- interactive plans -- for users to collaborate with an AI agent on complex, multi-step tasks in a document editor. Cocoa harmonizes human and AI efforts and enables flexible delegation of agency through two actions: Co-planning (where users collaboratively compose a plan of action with the agent) and Co-execution (where users collaboratively execute plan steps with the agent). Using scientific research as a sample domain, we motivate the design of Cocoa through a formative study with 9 researchers while also drawing inspiration from the design of computational notebooks. We evaluate Cocoa through a user study with 16 researchers and find that when compared to a strong chat baseline, Cocoa improved agent steerability without sacrificing ease of use. A deeper investigation of the general utility of both systems uncovered insights into usage contexts where interactive plans may be more appropriate than chat, and vice versa. Our work surfaces numerous practical implications and paves new paths for interactive interfaces that foster more effective collaboration between humans and agentic AI systems.
IdeaSynth: Iterative Research Idea Development Through Evolving and Composing Idea Facets with Literature-Grounded Feedback
Oct 05, 2024



Research ideation involves broad exploring and deep refining ideas. Both require deep engagement with literature. Existing tools focus primarily on idea broad generation, yet offer little support for iterative specification, refinement, and evaluation needed to further develop initial ideas. To bridge this gap, we introduce IdeaSynth, a research idea development system that uses LLMs to provide literature-grounded feedback for articulating research problems, solutions, evaluations, and contributions. IdeaSynth represents these idea facets as nodes on a canvas, and allow researchers to iteratively refine them by creating and exploring variations and composing them. Our lab study (N=20) showed that participants, while using IdeaSynth, explored more alternative ideas and expanded initial ideas with more details compared to a strong LLM-based baseline. Our deployment study (N=7) demonstrated that participants effectively used IdeaSynth for real-world research projects at various ideation stages from developing initial ideas to revising framings of mature manuscripts, highlighting the possibilities to adopt IdeaSynth in researcher's workflows.
PaperWeaver: Enriching Topical Paper Alerts by Contextualizing Recommended Papers with User-collected Papers
Mar 05, 2024With the rapid growth of scholarly archives, researchers subscribe to "paper alert" systems that periodically provide them with recommendations of recently published papers that are similar to previously collected papers. However, researchers sometimes struggle to make sense of nuanced connections between recommended papers and their own research context, as existing systems only present paper titles and abstracts. To help researchers spot these connections, we present PaperWeaver, an enriched paper alerts system that provides contextualized text descriptions of recommended papers based on user-collected papers. PaperWeaver employs a computational method based on Large Language Models (LLMs) to infer users' research interests from their collected papers, extract context-specific aspects of papers, and compare recommended and collected papers on these aspects. Our user study (N=15) showed that participants using PaperWeaver were able to better understand the relevance of recommended papers and triage them more confidently when compared to a baseline that presented the related work sections from recommended papers.
RCT Rejection Sampling for Causal Estimation Evaluation
Jul 27, 2023



Confounding is a significant obstacle to unbiased estimation of causal effects from observational data. For settings with high-dimensional covariates -- such as text data, genomics, or the behavioral social sciences -- researchers have proposed methods to adjust for confounding by adapting machine learning methods to the goal of causal estimation. However, empirical evaluation of these adjustment methods has been challenging and limited. In this work, we build on a promising empirical evaluation strategy that simplifies evaluation design and uses real data: subsampling randomized controlled trials (RCTs) to create confounded observational datasets while using the average causal effects from the RCTs as ground-truth. We contribute a new sampling algorithm, which we call RCT rejection sampling, and provide theoretical guarantees that causal identification holds in the observational data to allow for valid comparisons to the ground-truth RCT. Using synthetic data, we show our algorithm indeed results in low bias when oracle estimators are evaluated on the confounded samples, which is not always the case for a previously proposed algorithm. In addition to this identification result, we highlight several finite data considerations for evaluation designers who plan to use RCT rejection sampling on their own datasets. As a proof of concept, we implement an example evaluation pipeline and walk through these finite data considerations with a novel, real-world RCT -- which we release publicly -- consisting of approximately 70k observations and text data as high-dimensional covariates. Together, these contributions build towards a broader agenda of improved empirical evaluation for causal estimation.
ARIES: A Corpus of Scientific Paper Edits Made in Response to Peer Reviews
Jun 21, 2023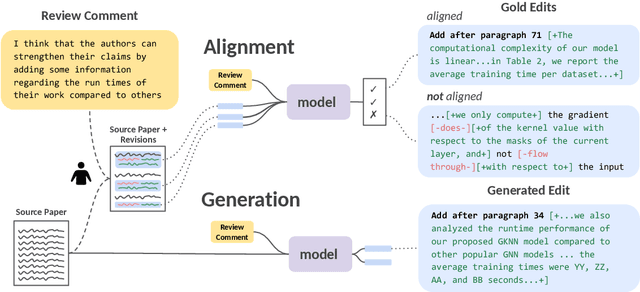
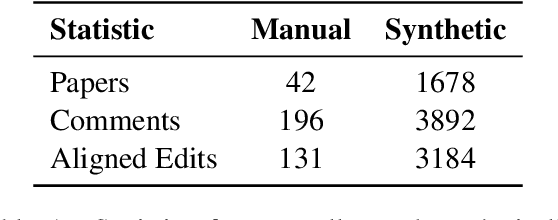

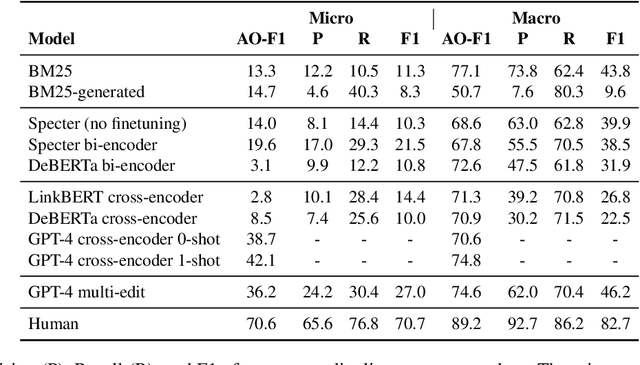
Revising scientific papers based on peer feedback is a challenging task that requires not only deep scientific knowledge and reasoning, but also the ability to recognize the implicit requests in high-level feedback and to choose the best of many possible ways to update the manuscript in response. We introduce this task for large language models and release ARIES, a dataset of review comments and their corresponding paper edits, to enable training and evaluating models. We study two versions of the task: comment-edit alignment and edit generation, and evaluate several baselines, including GPT-4. We find that models struggle even to identify the edits that correspond to a comment, especially in cases where the comment is phrased in an indirect way or where the edit addresses the spirit of a comment but not the precise request. When tasked with generating edits, GPT-4 often succeeds in addressing comments on a surface level, but it rigidly follows the wording of the feedback rather than the underlying intent, and includes fewer technical details than human-written edits. We hope that our formalization, dataset, and analysis will form a foundation for future work in this area.
Beyond Summarization: Designing AI Support for Real-World Expository Writing Tasks
Apr 05, 2023Large language models have introduced exciting new opportunities and challenges in designing and developing new AI-assisted writing support tools. Recent work has shown that leveraging this new technology can transform writing in many scenarios such as ideation during creative writing, editing support, and summarization. However, AI-supported expository writing--including real-world tasks like scholars writing literature reviews or doctors writing progress notes--is relatively understudied. In this position paper, we argue that developing AI supports for expository writing has unique and exciting research challenges and can lead to high real-world impacts. We characterize expository writing as evidence-based and knowledge-generating: it contains summaries of external documents as well as new information or knowledge. It can be seen as the product of authors' sensemaking process over a set of source documents, and the interplay between reading, reflection, and writing opens up new opportunities for designing AI support. We sketch three components for AI support design and discuss considerations for future research.
The Semantic Reader Project: Augmenting Scholarly Documents through AI-Powered Interactive Reading Interfaces
Mar 25, 2023



Scholarly publications are key to the transfer of knowledge from scholars to others. However, research papers are information-dense, and as the volume of the scientific literature grows, the need for new technology to support the reading process grows. In contrast to the process of finding papers, which has been transformed by Internet technology, the experience of reading research papers has changed little in decades. The PDF format for sharing research papers is widely used due to its portability, but it has significant downsides including: static content, poor accessibility for low-vision readers, and difficulty reading on mobile devices. This paper explores the question "Can recent advances in AI and HCI power intelligent, interactive, and accessible reading interfaces -- even for legacy PDFs?" We describe the Semantic Reader Project, a collaborative effort across multiple institutions to explore automatic creation of dynamic reading interfaces for research papers. Through this project, we've developed ten research prototype interfaces and conducted usability studies with more than 300 participants and real-world users showing improved reading experiences for scholars. We've also released a production reading interface for research papers that will incorporate the best features as they mature. We structure this paper around challenges scholars and the public face when reading research papers -- Discovery, Efficiency, Comprehension, Synthesis, and Accessibility -- and present an overview of our progress and remaining open challenges.