 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOlmo 3
Dec 15, 2025We introduce Olmo 3, a family of state-of-the-art, fully-open language models at the 7B and 32B parameter scales. Olmo 3 model construction targets long-context reasoning, function calling, coding, instruction following, general chat, and knowledge recall. This release includes the entire model flow, i.e., the full lifecycle of the family of models, including every stage, checkpoint, data point, and dependency used to build it. Our flagship model, Olmo 3 Think 32B, is the strongest fully-open thinking model released to-date.
AstaBench: Rigorous Benchmarking of AI Agents with a Scientific Research Suite
Oct 24, 2025AI agents hold the potential to revolutionize scientific productivity by automating literature reviews, replicating experiments, analyzing data, and even proposing new directions of inquiry; indeed, there are now many such agents, ranging from general-purpose "deep research" systems to specialized science-specific agents, such as AI Scientist and AIGS. Rigorous evaluation of these agents is critical for progress. Yet existing benchmarks fall short on several fronts: they (1) fail to provide holistic, product-informed measures of real-world use cases such as science research; (2) lack reproducible agent tools necessary for a controlled comparison of core agentic capabilities; (3) do not account for confounding variables such as model cost and tool access; (4) do not provide standardized interfaces for quick agent prototyping and evaluation; and (5) lack comprehensive baseline agents necessary to identify true advances. In response, we define principles and tooling for more rigorously benchmarking agents. Using these, we present AstaBench, a suite that provides the first holistic measure of agentic ability to perform scientific research, comprising 2400+ problems spanning the entire scientific discovery process and multiple scientific domains, and including many problems inspired by actual user requests to deployed Asta agents. Our suite comes with the first scientific research environment with production-grade search tools that enable controlled, reproducible evaluation, better accounting for confounders. Alongside, we provide a comprehensive suite of nine science-optimized classes of Asta agents and numerous baselines. Our extensive evaluation of 57 agents across 22 agent classes reveals several interesting findings, most importantly that despite meaningful progress on certain individual aspects, AI remains far from solving the challenge of science research assistance.
Ai2 Scholar QA: Organized Literature Synthesis with Attribution
Apr 15, 2025Retrieval-augmented generation is increasingly effective in answering scientific questions from literature, but many state-of-the-art systems are expensive and closed-source. We introduce Ai2 Scholar QA, a free online scientific question answering application. To facilitate research, we make our entire pipeline public: as a customizable open-source Python package and interactive web app, along with paper indexes accessible through public APIs and downloadable datasets. We describe our system in detail and present experiments analyzing its key design decisions. In an evaluation on a recent scientific QA benchmark, we find that Ai2 Scholar QA outperforms competing systems.
The Semantic Reader Project: Augmenting Scholarly Documents through AI-Powered Interactive Reading Interfaces
Mar 25, 2023



Scholarly publications are key to the transfer of knowledge from scholars to others. However, research papers are information-dense, and as the volume of the scientific literature grows, the need for new technology to support the reading process grows. In contrast to the process of finding papers, which has been transformed by Internet technology, the experience of reading research papers has changed little in decades. The PDF format for sharing research papers is widely used due to its portability, but it has significant downsides including: static content, poor accessibility for low-vision readers, and difficulty reading on mobile devices. This paper explores the question "Can recent advances in AI and HCI power intelligent, interactive, and accessible reading interfaces -- even for legacy PDFs?" We describe the Semantic Reader Project, a collaborative effort across multiple institutions to explore automatic creation of dynamic reading interfaces for research papers. Through this project, we've developed ten research prototype interfaces and conducted usability studies with more than 300 participants and real-world users showing improved reading experiences for scholars. We've also released a production reading interface for research papers that will incorporate the best features as they mature. We structure this paper around challenges scholars and the public face when reading research papers -- Discovery, Efficiency, Comprehension, Synthesis, and Accessibility -- and present an overview of our progress and remaining open challenges.
The Semantic Scholar Open Data Platform
Jan 24, 2023



The volume of scientific output is creating an urgent need for automated tools to help scientists keep up with developments in their field. Semantic Scholar (S2) is an open data platform and website aimed at accelerating science by helping scholars discover and understand scientific literature. We combine public and proprietary data sources using state-of-the-art techniques for scholarly PDF content extraction and automatic knowledge graph construction to build the Semantic Scholar Academic Graph, the largest open scientific literature graph to-date, with 200M+ papers, 80M+ authors, 550M+ paper-authorship edges, and 2.4B+ citation edges. The graph includes advanced semantic features such as structurally parsed text, natural language summaries, and vector embeddings. In this paper, we describe the components of the S2 data processing pipeline and the associated APIs offered by the platform. We will update this living document to reflect changes as we add new data offerings and improve existing services.
GenericsKB: A Knowledge Base of Generic Statements
May 02, 2020


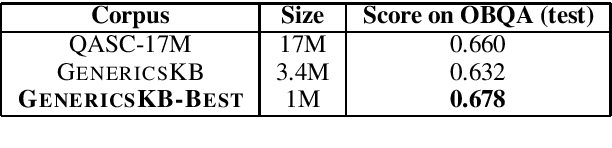
We present a new resource for the NLP community, namely a large (3.5M+ sentence) knowledge base of *generic statements*, e.g., "Trees remove carbon dioxide from the atmosphere", collected from multiple corpora. This is the first large resource to contain *naturally occurring* generic sentences, as opposed to extracted or crowdsourced triples, and thus is rich in high-quality, general, semantically complete statements. All GenericsKB sentences are annotated with their topical term, surrounding context (sentences), and a (learned) confidence. We also release GenericsKB-Best (1M+ sentences), containing the best-quality generics in GenericsKB augmented with selected, synthesized generics from WordNet and ConceptNet. In tests on two existing datasets requiring multihop reasoning (OBQA and QASC), we find using GenericsKB can result in higher scores and better explanations than using a much larger corpus. This demonstrates that GenericsKB can be a useful resource for NLP applications, as well as providing data for linguistic studies of generics and their semantics. GenericsKB is available at https://allenai.org/data/genericskb.