 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSource-Aware Training Enables Knowledge Attribution in Language Models
Apr 11, 2024Large language models (LLMs) learn a vast amount of knowledge during pretraining, but they are often oblivious to the source(s) of such knowledge. We investigate the problem of intrinsic source citation, where LLMs are required to cite the pretraining source supporting a generated response. Intrinsic source citation can enhance LLM transparency, interpretability, and verifiability. To give LLMs such ability, we explore source-aware training -- a post pretraining recipe that involves (i) training the LLM to associate unique source document identifiers with the knowledge in each document, followed by (ii) an instruction-tuning to teach the LLM to cite a supporting pretraining source when prompted. Source-aware training can easily be applied to pretrained LLMs off the shelf, and diverges minimally from existing pretraining/fine-tuning frameworks. Through experiments on carefully curated data, we demonstrate that our training recipe can enable faithful attribution to the pretraining data without a substantial impact on the model's quality compared to standard pretraining. Our results also highlight the importance of data augmentation in achieving attribution. Code and data available here: \url{https://github.com/mukhal/intrinsic-source-citation}
OLMo: Accelerating the Science of Language Models
Feb 07, 2024
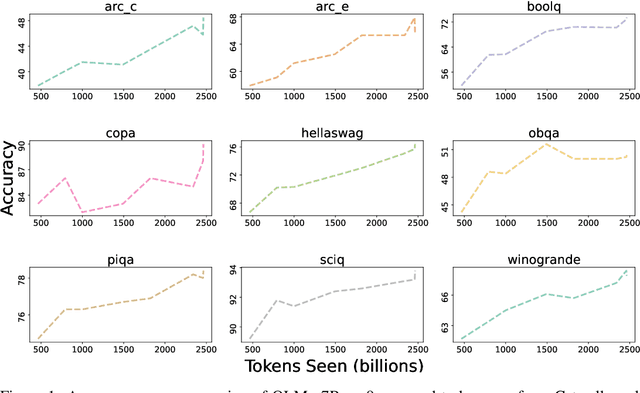
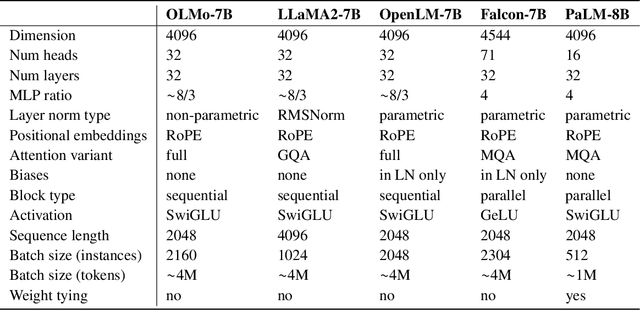
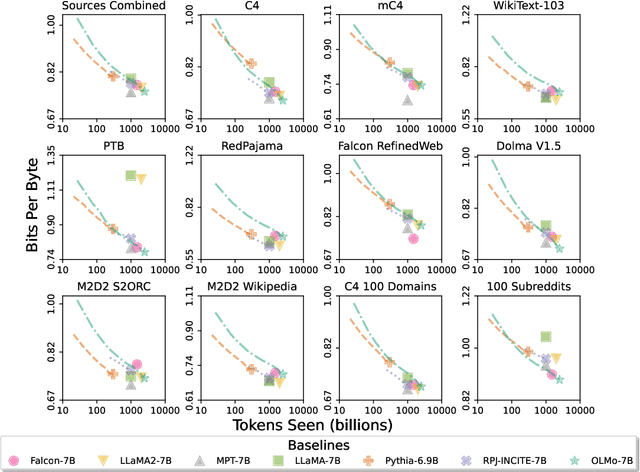
Language models (LMs) have become ubiquitous in both NLP research and in commercial product offerings. As their commercial importance has surged, the most powerful models have become closed off, gated behind proprietary interfaces, with important details of their training data, architectures, and development undisclosed. Given the importance of these details in scientifically studying these models, including their biases and potential risks, we believe it is essential for the research community to have access to powerful, truly open LMs. To this end, this technical report details the first release of OLMo, a state-of-the-art, truly Open Language Model and its framework to build and study the science of language modeling. Unlike most prior efforts that have only released model weights and inference code, we release OLMo and the whole framework, including training data and training and evaluation code. We hope this release will empower and strengthen the open research community and inspire a new wave of innovation.
Dolma: an Open Corpus of Three Trillion Tokens for Language Model Pretraining Research
Jan 31, 2024



Language models have become a critical technology to tackling a wide range of natural language processing tasks, yet many details about how the best-performing language models were developed are not reported. In particular, information about their pretraining corpora is seldom discussed: commercial language models rarely provide any information about their data; even open models rarely release datasets they are trained on, or an exact recipe to reproduce them. As a result, it is challenging to conduct certain threads of language modeling research, such as understanding how training data impacts model capabilities and shapes their limitations. To facilitate open research on language model pretraining, we release Dolma, a three trillion tokens English corpus, built from a diverse mixture of web content, scientific papers, code, public-domain books, social media, and encyclopedic materials. In addition, we open source our data curation toolkit to enable further experimentation and reproduction of our work. In this report, we document Dolma, including its design principles, details about its construction, and a summary of its contents. We interleave this report with analyses and experimental results from training language models on intermediate states of Dolma to share what we have learned about important data curation practices, including the role of content or quality filters, deduplication, and multi-source mixing. Dolma has been used to train OLMo, a state-of-the-art, open language model and framework designed to build and study the science of language modeling.
Paloma: A Benchmark for Evaluating Language Model Fit
Dec 16, 2023Language models (LMs) commonly report perplexity on monolithic data held out from training. Implicitly or explicitly, this data is composed of domains$\unicode{x2013}$varying distributions of language. Rather than assuming perplexity on one distribution extrapolates to others, Perplexity Analysis for Language Model Assessment (Paloma), measures LM fit to 585 text domains, ranging from nytimes.com to r/depression on Reddit. We invite submissions to our benchmark and organize results by comparability based on compliance with guidelines such as removal of benchmark contamination from pretraining. Submissions can also record parameter and training token count to make comparisons of Pareto efficiency for performance as a function of these measures of cost. We populate our benchmark with results from 6 baselines pretrained on popular corpora. In case studies, we demonstrate analyses that are possible with Paloma, such as finding that pretraining without data beyond Common Crawl leads to inconsistent fit to many domains.
Catwalk: A Unified Language Model Evaluation Framework for Many Datasets
Dec 15, 2023The success of large language models has shifted the evaluation paradigms in natural language processing (NLP). The community's interest has drifted towards comparing NLP models across many tasks, domains, and datasets, often at an extreme scale. This imposes new engineering challenges: efforts in constructing datasets and models have been fragmented, and their formats and interfaces are incompatible. As a result, it often takes extensive (re)implementation efforts to make fair and controlled comparisons at scale. Catwalk aims to address these issues. Catwalk provides a unified interface to a broad range of existing NLP datasets and models, ranging from both canonical supervised training and fine-tuning, to more modern paradigms like in-context learning. Its carefully-designed abstractions allow for easy extensions to many others. Catwalk substantially lowers the barriers to conducting controlled experiments at scale. For example, we finetuned and evaluated over 64 models on over 86 datasets with a single command, without writing any code. Maintained by the AllenNLP team at the Allen Institute for Artificial Intelligence (AI2), Catwalk is an ongoing open-source effort: https://github.com/allenai/catwalk.
Camels in a Changing Climate: Enhancing LM Adaptation with Tulu 2
Nov 20, 2023Since the release of T\"ULU [Wang et al., 2023b], open resources for instruction tuning have developed quickly, from better base models to new finetuning techniques. We test and incorporate a number of these advances into T\"ULU, resulting in T\"ULU 2, a suite of improved T\"ULU models for advancing the understanding and best practices of adapting pretrained language models to downstream tasks and user preferences. Concretely, we release: (1) T\"ULU-V2-mix, an improved collection of high-quality instruction datasets; (2) T\"ULU 2, LLAMA-2 models finetuned on the V2 mixture; (3) T\"ULU 2+DPO, T\"ULU 2 models trained with direct preference optimization (DPO), including the largest DPO-trained model to date (T\"ULU 2+DPO 70B); (4) CODE T\"ULU 2, CODE LLAMA models finetuned on our V2 mix that outperform CODE LLAMA and its instruction-tuned variant, CODE LLAMA-Instruct. Our evaluation from multiple perspectives shows that the T\"ULU 2 suite achieves state-of-the-art performance among open models and matches or exceeds the performance of GPT-3.5-turbo-0301 on several benchmarks. We release all the checkpoints, data, training and evaluation code to facilitate future open efforts on adapting large language models.
Efficiency Pentathlon: A Standardized Arena for Efficiency Evaluation
Jul 19, 2023Rising computational demands of modern natural language processing (NLP) systems have increased the barrier to entry for cutting-edge research while posing serious environmental concerns. Yet, progress on model efficiency has been impeded by practical challenges in model evaluation and comparison. For example, hardware is challenging to control due to disparate levels of accessibility across different institutions. Moreover, improvements in metrics such as FLOPs often fail to translate to progress in real-world applications. In response, we introduce Pentathlon, a benchmark for holistic and realistic evaluation of model efficiency. Pentathlon focuses on inference, which accounts for a majority of the compute in a model's lifecycle. It offers a strictly-controlled hardware platform, and is designed to mirror real-world applications scenarios. It incorporates a suite of metrics that target different aspects of efficiency, including latency, throughput, memory overhead, and energy consumption. Pentathlon also comes with a software library that can be seamlessly integrated into any codebase and enable evaluation. As a standardized and centralized evaluation platform, Pentathlon can drastically reduce the workload to make fair and reproducible efficiency comparisons. While initially focused on natural language processing (NLP) models, Pentathlon is designed to allow flexible extension to other fields. We envision Pentathlon will stimulate algorithmic innovations in building efficient models, and foster an increased awareness of the social and environmental implications in the development of future-generation NLP models.
How Far Can Camels Go? Exploring the State of Instruction Tuning on Open Resources
Jun 07, 2023In this work we explore recent advances in instruction-tuning language models on a range of open instruction-following datasets. Despite recent claims that open models can be on par with state-of-the-art proprietary models, these claims are often accompanied by limited evaluation, making it difficult to compare models across the board and determine the utility of various resources. We provide a large set of instruction-tuned models from 6.7B to 65B parameters in size, trained on 12 instruction datasets ranging from manually curated (e.g., OpenAssistant) to synthetic and distilled (e.g., Alpaca) and systematically evaluate them on their factual knowledge, reasoning, multilinguality, coding, and open-ended instruction following abilities through a collection of automatic, model-based, and human-based metrics. We further introduce T\"ulu, our best performing instruction-tuned model suite finetuned on a combination of high-quality open resources. Our experiments show that different instruction-tuning datasets can uncover or enhance specific skills, while no single dataset (or combination) provides the best performance across all evaluations. Interestingly, we find that model and human preference-based evaluations fail to reflect differences in model capabilities exposed by benchmark-based evaluations, suggesting the need for the type of systemic evaluation performed in this work. Our evaluations show that the best model in any given evaluation reaches on average 83% of ChatGPT performance, and 68% of GPT-4 performance, suggesting that further investment in building better base models and instruction-tuning data is required to close the gap. We release our instruction-tuned models, including a fully finetuned 65B T\"ulu, along with our code, data, and evaluation framework at https://github.com/allenai/open-instruct to facilitate future research.
Large Language Model Distillation Doesn't Need a Teacher
May 24, 2023Knowledge distillation trains a smaller student model to match the output distribution of a larger teacher to maximize the end-task performance under computational constraints. However, existing literature on language model distillation primarily focuses on compressing encoder-only models that are then specialized by task-specific supervised finetuning. We need to rethink this setup for more recent large language models with tens to hundreds of billions of parameters. Task-specific finetuning is impractical at this scale, and model performance is often measured using zero/few-shot prompting. Thus, in this work, we advocate for task-agnostic zero-shot evaluated distillation for large language models without access to end-task finetuning data. We propose a teacher-free task-agnostic distillation method, which uses a truncated version of the larger model for initialization, and continues pretraining this model using a language modeling objective. Our teacher-free method shines in a distillation regime where it is infeasible to fit both the student and teacher into the GPU memory. Despite its simplicity, our method can effectively reduce the model size by 50\%, matching or outperforming the vanilla distillation method on perplexity and accuracy on 13 zero-shot end-tasks while being 1.5x computationally efficient.
TESS: Text-to-Text Self-Conditioned Simplex Diffusion
May 15, 2023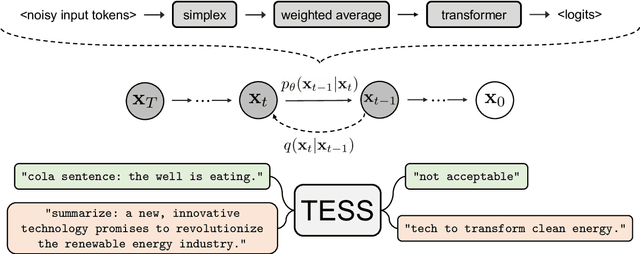
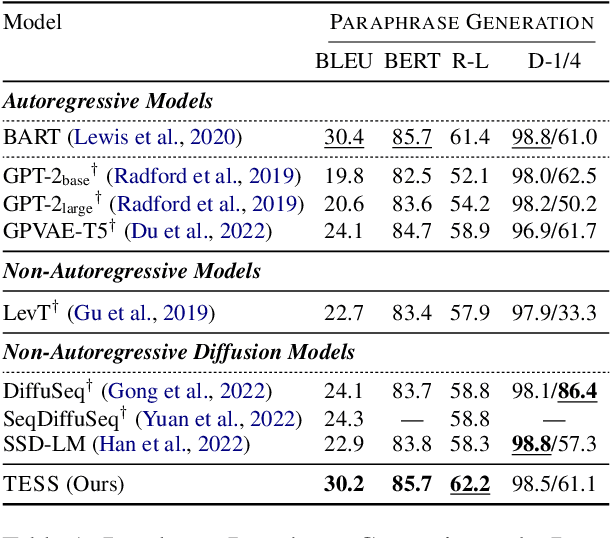

Diffusion models have emerged as a powerful paradigm for generation, obtaining strong performance in various domains with continuous-valued inputs. Despite the promises of fully non-autoregressive text generation, applying diffusion models to natural language remains challenging due to its discrete nature. In this work, we propose Text-to-text Self-conditioned Simplex Diffusion (TESS), a text diffusion model that is fully non-autoregressive, employs a new form of self-conditioning, and applies the diffusion process on the logit simplex space rather than the typical learned embedding space. Through extensive experiments on natural language understanding and generation tasks including summarization, text simplification, paraphrase generation, and question generation, we demonstrate that TESS outperforms state-of-the-art non-autoregressive models and is competitive with pretrained autoregressive sequence-to-sequence models.