 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProCUA-SFT Technical Report
Jun 15, 2026Training computer-use agents (CUAs) -- models that interact with graphical desktops through screenshots and keyboard/mouse actions -- requires large-scale, diverse trajectory data collected in full desktop environments. The largest public resource, AgentNet (22.5K human trajectories), leads to negative transfer when used for supervised fine-tuning (SFT): continuing training UI-TARS 7B on AgentNet causes OSWorld success rate to fall from 26.3% to 8-10%. We present ProCUA-SFT, a dataset of 3.1M step-level SFT samples distilled from 93K synthetic trajectories across 2,484 application combinations. The dataset is produced by a fully automated pipeline that (i) synthesizes grounded tasks on live desktops seeded with real-world content -- 912 spreadsheets from SpreadsheetBench, approximately 10K permissively-licensed presentations from Zenodo10K, and multi-application OSWorld configs -- and (ii) verifies each task's feasibility through binary precondition checking before rollout. A single VLM (Kimi-K2.5) serves as goal generator, precondition judge, and trajectory executor, eliminating planner-actor capability gaps. Each trajectory is expanded into step-prefix samples that exactly reproduce the context layout seen at inference time. Fine-tuning UI-TARS 7B on ProCUA-SFT for one epoch yields 45.0% on OSWorld -- an 18.7 percentage-point improvement over the base model and over 35% above AgentNet-trained counterparts. A subset of ProCUA was incorporated into the training data for the Nemotron 3 Nano Omni model, contributing to its computer-use capabilities.
Gaming the Judge: Unfaithful Chain-of-Thought Can Undermine Agent Evaluation
Jan 21, 2026Large language models (LLMs) are increasingly used as judges to evaluate agent performance, particularly in non-verifiable settings where judgments rely on agent trajectories including chain-of-thought (CoT) reasoning. This paradigm implicitly assumes that the agent's CoT faithfully reflects both its internal reasoning and the underlying environment state. We show this assumption is brittle: LLM judges are highly susceptible to manipulation of agent reasoning traces. By systematically rewriting agent CoTs while holding actions and observations fixed, we demonstrate that manipulated reasoning alone can inflate false positive rates of state-of-the-art VLM judges by up to 90% across 800 trajectories spanning diverse web tasks. We study manipulation strategies spanning style-based approaches that alter only the presentation of reasoning and content-based approaches that fabricate signals of task progress, and find that content-based manipulations are consistently more effective. We evaluate prompting-based techniques and scaling judge-time compute, which reduce but do not fully eliminate susceptibility to manipulation. Our findings reveal a fundamental vulnerability in LLM-based evaluation and highlight the need for judging mechanisms that verify reasoning claims against observable evidence.
Process Reward Models That Think
Apr 23, 2025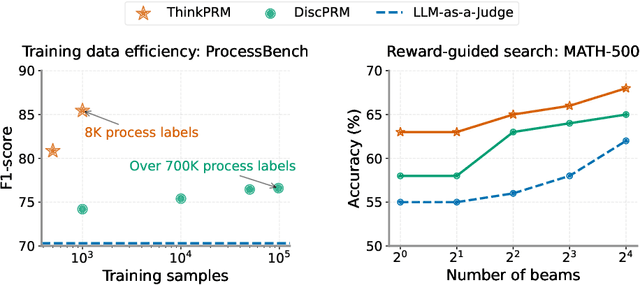
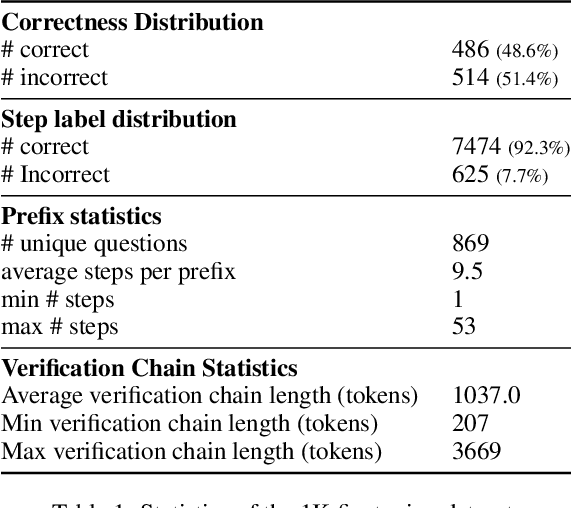
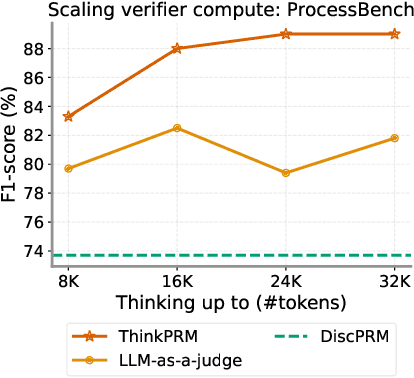
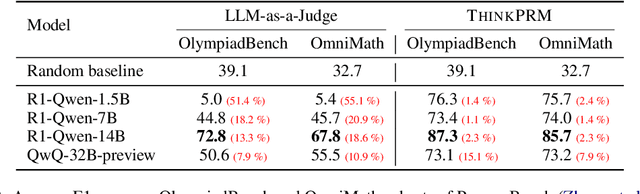
Step-by-step verifiers -- also known as process reward models (PRMs) -- are a key ingredient for test-time scaling. PRMs require step-level supervision, making them expensive to train. This work aims to build data-efficient PRMs as verbalized step-wise reward models that verify every step in the solution by generating a verification chain-of-thought (CoT). We propose ThinkPRM, a long CoT verifier fine-tuned on orders of magnitude fewer process labels than those required by discriminative PRMs. Our approach capitalizes on the inherent reasoning abilities of long CoT models, and outperforms LLM-as-a-Judge and discriminative verifiers -- using only 1% of the process labels in PRM800K -- across several challenging benchmarks. Specifically, ThinkPRM beats the baselines on ProcessBench, MATH-500, and AIME '24 under best-of-N selection and reward-guided search. In an out-of-domain evaluation on a subset of GPQA-Diamond and LiveCodeBench, our PRM surpasses discriminative verifiers trained on the full PRM800K by 8% and 4.5%, respectively. Lastly, under the same token budget, ThinkPRM scales up verification compute more effectively compared to LLM-as-a-Judge, outperforming it by 7.2% on a subset of ProcessBench. Our work highlights the value of generative, long CoT PRMs that can scale test-time compute for verification while requiring minimal supervision for training. Our code, data, and models will be released at https://github.com/mukhal/thinkprm.
MLRC-Bench: Can Language Agents Solve Machine Learning Research Challenges?
Apr 13, 2025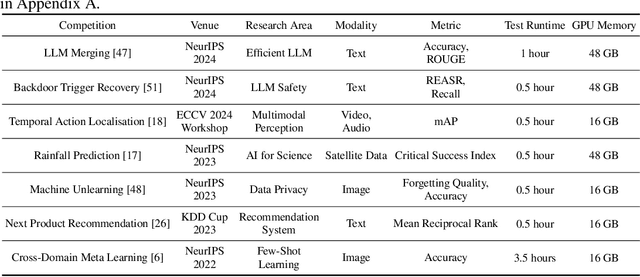
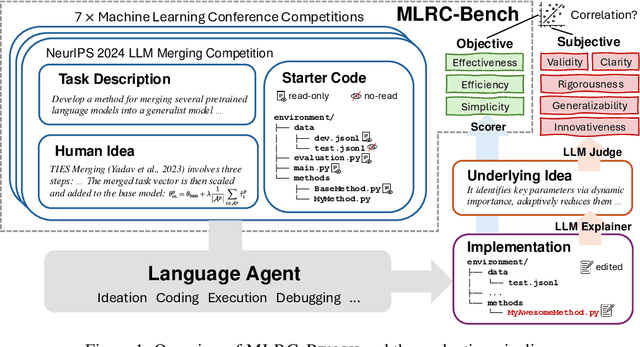
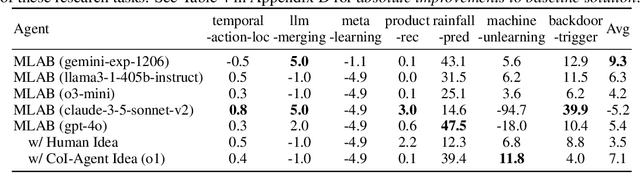
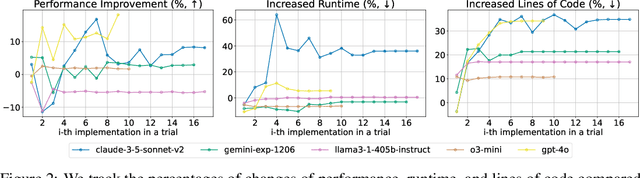
Existing evaluation of large language model (LLM) agents on scientific discovery lacks objective baselines and metrics to assess the viability of their proposed methods. To address this issue, we introduce MLRC-Bench, a benchmark designed to quantify how effectively language agents can tackle challenging Machine Learning (ML) Research Competitions. Our benchmark highlights open research problems that demand novel methodologies, in contrast to recent benchmarks such as OpenAI's MLE-Bench (Chan et al., 2024) and METR's RE-Bench (Wijk et al., 2024), which focus on well-established research tasks that are largely solvable through sufficient engineering effort. Unlike prior work, e.g., AI Scientist (Lu et al., 2024b), which evaluates the end-to-end agentic pipeline by using LLM-as-a-judge, MLRC-Bench measures the key steps of proposing and implementing novel research methods and evaluates them with newly proposed rigorous protocol and objective metrics. Our curated suite of 7 competition tasks reveals significant challenges for LLM agents. Even the best-performing tested agent (gemini-exp-1206 under MLAB (Huang et al., 2024a)) closes only 9.3% of the gap between baseline and top human participant scores. Furthermore, our analysis reveals a misalignment between the LLM-judged innovation and their actual performance on cutting-edge ML research problems. MLRC-Bench is a dynamic benchmark, which is designed to continually grow with new ML competitions to encourage rigorous and objective evaluations of AI's research capabilities.
If You Can't Use Them, Recycle Them: Optimizing Merging at Scale Mitigates Performance Tradeoffs
Dec 05, 2024
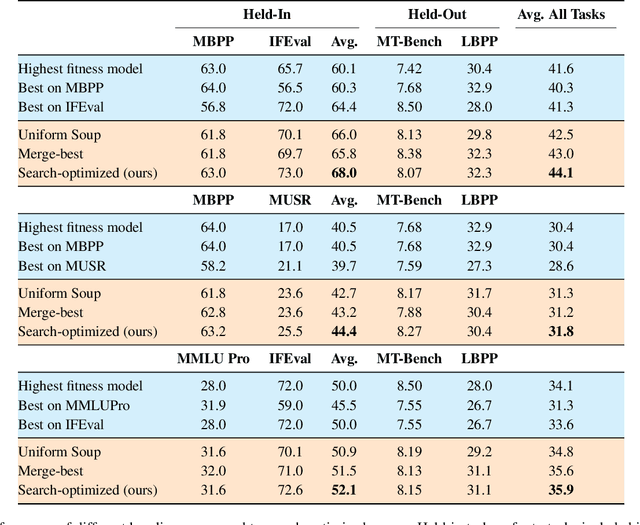
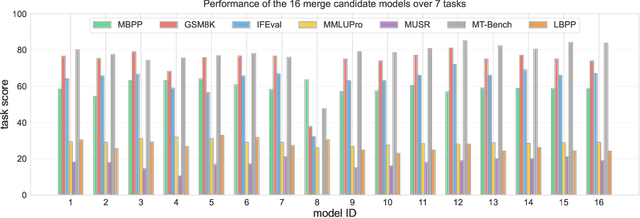
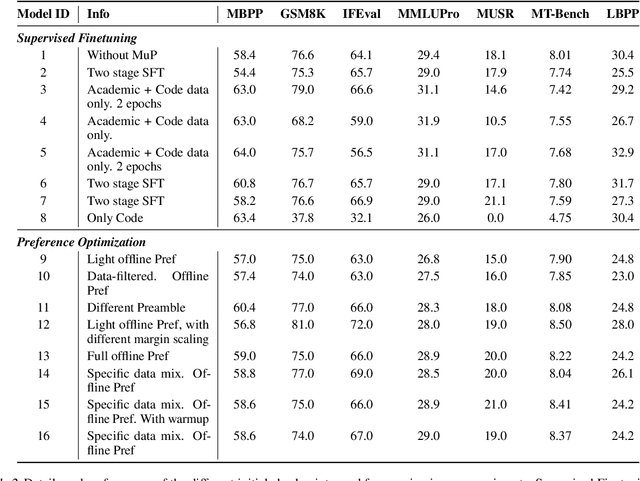
Model merging has shown great promise at combining expert models, but the benefit of merging is unclear when merging ``generalist'' models trained on many tasks. We explore merging in the context of large ($\sim100$B) models, by \textit{recycling} checkpoints that exhibit tradeoffs among different tasks. Such checkpoints are often created in the process of developing a frontier model, and many suboptimal ones are usually discarded. Given a pool of model checkpoints obtained from different training runs (e.g., different stages, objectives, hyperparameters, and data mixtures), which naturally show tradeoffs across different language capabilities (e.g., instruction following vs. code generation), we investigate whether merging can recycle such suboptimal models into a Pareto-optimal one. Our optimization algorithm tunes the weight of each checkpoint in a linear combination, resulting in a Pareto-optimal models that outperforms both individual models and merge-based baselines. Further analysis shows that good merges tend to include almost all checkpoints with with non-zero weights, indicating that even seemingly bad initial checkpoints can contribute to good final merges.
Retrieval or Global Context Understanding? On Many-Shot In-Context Learning for Long-Context Evaluation
Nov 11, 2024
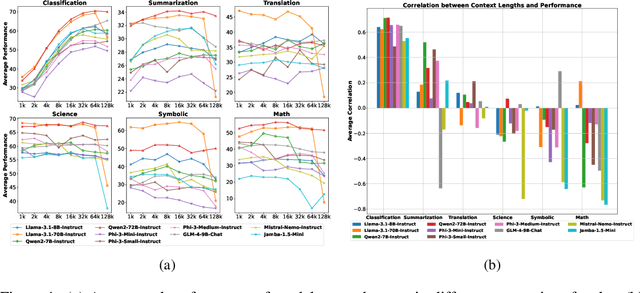
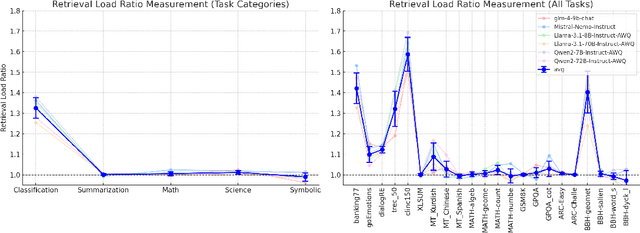
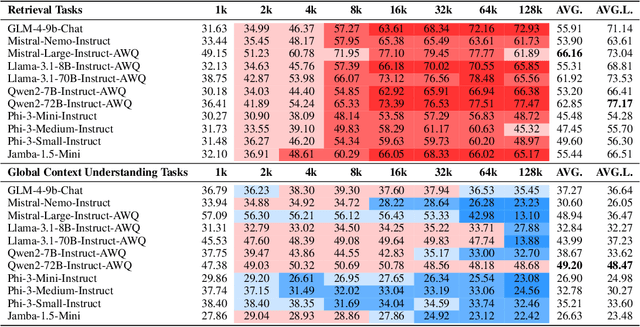
Language models (LMs) have demonstrated an improved capacity to handle long-context information, yet existing long-context benchmarks primarily measure LMs' retrieval abilities with extended inputs, e.g., pinpointing a short phrase from long-form text. Therefore, they may fall short when evaluating models' global context understanding capacity, such as synthesizing and reasoning over content across input to generate the response. In this paper, we study long-context language model (LCLM) evaluation through many-shot in-context learning (ICL). Concretely, we identify the skills each ICL task requires, and examine models' long-context capabilities on them. We first ask: What types of ICL tasks benefit from additional demonstrations, and are these tasks effective at evaluating LCLMs? We find that classification and summarization tasks show notable performance improvements with additional demonstrations, while translation and reasoning tasks do not exhibit clear trends. This suggests the classification tasks predominantly test models' retrieval skills. Next, we ask: To what extent does each task require retrieval skills versus global context understanding from LCLMs? We develop metrics to categorize ICL tasks into two groups: (i) retrieval tasks that require strong retrieval ability to pinpoint relevant examples, and (ii) global context understanding tasks that necessitate a deeper comprehension of the full input. We find that not all datasets can effectively evaluate these long-context capabilities. To address this gap, we introduce a new many-shot ICL benchmark, MANYICLBENCH, designed to characterize LCLMs' retrieval and global context understanding capabilities separately. Benchmarking 11 open-weight LCLMs with MANYICLBENCH, we find that while state-of-the-art models perform well in retrieval tasks up to 64k tokens, many show significant drops in global context tasks at just 16k tokens.
FactCheckmate: Preemptively Detecting and Mitigating Hallucinations in LMs
Oct 03, 2024



Language models (LMs) hallucinate. We inquire: Can we detect and mitigate hallucinations before they happen? This work answers this research question in the positive, by showing that the internal representations of LMs provide rich signals that can be used for this purpose. We introduce FactCheckMate, which preemptively detects hallucinations by learning a classifier that predicts whether the LM will hallucinate, based on the model's hidden states produced over the inputs, before decoding begins. If a hallucination is detected, FactCheckMate then intervenes, by adjusting the LM's hidden states such that the model will produce more factual outputs. FactCheckMate provides fresh insights that the inner workings of LMs can be revealed by their hidden states. Practically, both the detection and mitigation models in FactCheckMate are lightweight, adding little inference overhead; FactCheckMate proves a more efficient approach for mitigating hallucinations compared to many post-hoc alternatives. We evaluate FactCheckMate over LMs of different scales and model families (including Llama, Mistral, and Gemma), across a variety of QA datasets from different domains. Our results demonstrate the effectiveness of leveraging internal representations for early hallucination detection and mitigation, achieving over 70% preemptive detection accuracy. On average, outputs generated by LMs with intervention are 34.4% more factual compared to those without intervention. The average overhead difference in the inference time introduced by FactCheckMate is around 3.16 seconds.
Learning to Reason via Program Generation, Emulation, and Search
May 28, 2024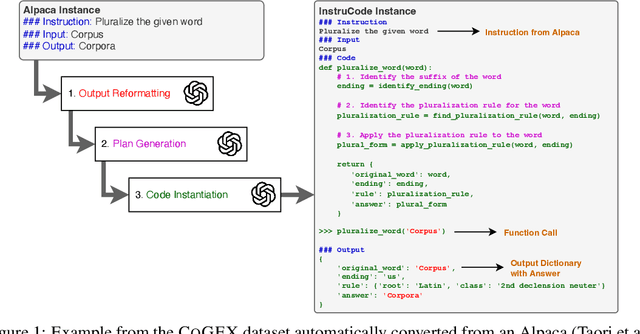
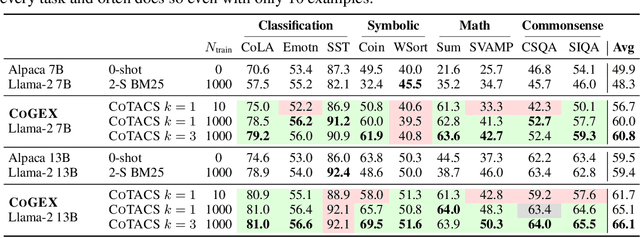


Program synthesis with language models (LMs) has unlocked a large set of reasoning abilities; code-tuned LMs have proven adept at generating programs that solve a wide variety of algorithmic symbolic manipulation tasks (e.g. word concatenation). However, not all reasoning tasks are easily expressible as code, e.g. tasks involving commonsense reasoning, moral decision-making, and sarcasm understanding. Our goal is to extend an LM's program synthesis skills to such tasks and evaluate the results via pseudo-programs, namely Python programs where some leaf function calls are left undefined. To that end, we propose, Code Generation and Emulated EXecution (CoGEX). CoGEX works by (1) training LMs to generate their own pseudo-programs, (2) teaching them to emulate their generated program's execution, including those leaf functions, allowing the LM's knowledge to fill in the execution gaps; and (3) using them to search over many programs to find an optimal one. To adapt the CoGEX model to a new task, we introduce a method for performing program search to find a single program whose pseudo-execution yields optimal performance when applied to all the instances of a given dataset. We show that our approach yields large improvements compared to standard in-context learning approaches on a battery of tasks, both algorithmic and soft reasoning. This result thus demonstrates that code synthesis can be applied to a much broader class of problems than previously considered. Our released dataset, fine-tuned models, and implementation can be found at \url{https://github.com/nweir127/CoGEX}.
Small Language Models Need Strong Verifiers to Self-Correct Reasoning
Apr 26, 2024



Self-correction has emerged as a promising solution to boost the reasoning performance of large language models (LLMs), where LLMs refine their solutions using self-generated critiques that pinpoint the errors. This work explores whether smaller-size (<= 13B) language models (LMs) have the ability of self-correction on reasoning tasks with minimal inputs from stronger LMs. We propose a novel pipeline that prompts smaller LMs to collect self-correction data that supports the training of self-refinement abilities. First, we leverage correct solutions to guide the model in critiquing their incorrect responses. Second, the generated critiques, after filtering, are used for supervised fine-tuning of the self-correcting reasoner through solution refinement. Our experimental results show improved self-correction abilities of two models on five datasets spanning math and commonsense reasoning, with notable performance gains when paired with a strong GPT-4-based verifier, though limitations are identified when using a weak self-verifier for determining when to correct.
Source-Aware Training Enables Knowledge Attribution in Language Models
Apr 11, 2024



Large language models (LLMs) learn a vast amount of knowledge during pretraining, but they are often oblivious to the source(s) of such knowledge. We investigate the problem of intrinsic source citation, where LLMs are required to cite the pretraining source supporting a generated response. Intrinsic source citation can enhance LLM transparency, interpretability, and verifiability. To give LLMs such ability, we explore source-aware training -- a post pretraining recipe that involves (i) training the LLM to associate unique source document identifiers with the knowledge in each document, followed by (ii) an instruction-tuning to teach the LLM to cite a supporting pretraining source when prompted. Source-aware training can easily be applied to pretrained LLMs off the shelf, and diverges minimally from existing pretraining/fine-tuning frameworks. Through experiments on carefully curated data, we demonstrate that our training recipe can enable faithful attribution to the pretraining data without a substantial impact on the model's quality compared to standard pretraining. Our results also highlight the importance of data augmentation in achieving attribution. Code and data available here: \url{https://github.com/mukhal/intrinsic-source-citation}