 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVERGE: Formal Refinement and Guidance Engine for Verifiable LLM Reasoning
Jan 27, 2026Despite the syntactic fluency of Large Language Models (LLMs), ensuring their logical correctness in high-stakes domains remains a fundamental challenge. We present a neurosymbolic framework that combines LLMs with SMT solvers to produce verification-guided answers through iterative refinement. Our approach decomposes LLM outputs into atomic claims, autoformalizes them into first-order logic, and verifies their logical consistency using automated theorem proving. We introduce three key innovations: (1) multi-model consensus via formal semantic equivalence checking to ensure logic-level alignment between candidates, eliminating the syntactic bias of surface-form metrics, (2) semantic routing that directs different claim types to appropriate verification strategies: symbolic solvers for logical claims and LLM ensembles for commonsense reasoning, and (3) precise logical error localization via Minimal Correction Subsets (MCS), which pinpoint the exact subset of claims to revise, transforming binary failure signals into actionable feedback. Our framework classifies claims by their logical status and aggregates multiple verification signals into a unified score with variance-based penalty. The system iteratively refines answers using structured feedback until acceptance criteria are met or convergence is achieved. This hybrid approach delivers formal guarantees where possible and consensus verification elsewhere, advancing trustworthy AI. With the GPT-OSS-120B model, VERGE demonstrates an average performance uplift of 18.7% at convergence across a set of reasoning benchmarks compared to single-pass approaches.
A Neurosymbolic Approach to Natural Language Formalization and Verification
Nov 12, 2025Large Language Models perform well at natural language interpretation and reasoning, but their inherent stochasticity limits their adoption in regulated industries like finance and healthcare that operate under strict policies. To address this limitation, we present a two-stage neurosymbolic framework that (1) uses LLMs with optional human guidance to formalize natural language policies, allowing fine-grained control of the formalization process, and (2) uses inference-time autoformalization to validate logical correctness of natural language statements against those policies. When correctness is paramount, we perform multiple redundant formalization steps at inference time, cross checking the formalizations for semantic equivalence. Our benchmarks demonstrate that our approach exceeds 99% soundness, indicating a near-zero false positive rate in identifying logical validity. Our approach produces auditable logical artifacts that substantiate the verification outcomes and can be used to improve the original text.
VeriCoT: Neuro-symbolic Chain-of-Thought Validation via Logical Consistency Checks
Nov 06, 2025



LLMs can perform multi-step reasoning through Chain-of-Thought (CoT), but they cannot reliably verify their own logic. Even when they reach correct answers, the underlying reasoning may be flawed, undermining trust in high-stakes scenarios. To mitigate this issue, we introduce VeriCoT, a neuro-symbolic method that extracts and verifies formal logical arguments from CoT reasoning. VeriCoT formalizes each CoT reasoning step into first-order logic and identifies premises that ground the argument in source context, commonsense knowledge, or prior reasoning steps. The symbolic representation enables automated solvers to verify logical validity while the NL premises allow humans and systems to identify ungrounded or fallacious reasoning steps. Experiments on the ProofWriter, LegalBench, and BioASQ datasets show VeriCoT effectively identifies flawed reasoning, and serves as a strong predictor of final answer correctness. We also leverage VeriCoT's verification signal for (1) inference-time self-reflection, (2) supervised fine-tuning (SFT) on VeriCoT-distilled datasets and (3) preference fine-tuning (PFT) with direct preference optimization (DPO) using verification-based pairwise rewards, further improving reasoning validity and accuracy.
From Models to Microtheories: Distilling a Model's Topical Knowledge for Grounded Question Answering
Dec 24, 2024



Recent reasoning methods (e.g., chain-of-thought, entailment reasoning) help users understand how language models (LMs) answer a single question, but they do little to reveal the LM's overall understanding, or "theory," about the question's topic, making it still hard to trust the model. Our goal is to materialize such theories - here called microtheories (a linguistic analog of logical microtheories) - as a set of sentences encapsulating an LM's core knowledge about a topic. These statements systematically work together to entail answers to a set of questions to both engender trust and improve performance. Our approach is to first populate a knowledge store with (model-generated) sentences that entail answers to training questions and then distill those down to a core microtheory that is concise, general, and non-redundant. We show that, when added to a general corpus (e.g., Wikipedia), microtheories can supply critical, topical information not necessarily present in the corpus, improving both a model's ability to ground its answers to verifiable knowledge (i.e., show how answers are systematically entailed by documents in the corpus, fully grounding up to +8% more answers), and the accuracy of those grounded answers (up to +8% absolute). We also show that, in a human evaluation in the medical domain, our distilled microtheories contain a significantly higher concentration of topically critical facts than the non-distilled knowledge store. Finally, we show we can quantify the coverage of a microtheory for a topic (characterized by a dataset) using a notion of $p$-relevance. Together, these suggest that microtheories are an efficient distillation of an LM's topic-relevant knowledge, that they can usefully augment existing corpora, and can provide both performance gains and an interpretable, verifiable window into the model's knowledge of a topic.
Core: Robust Factual Precision Scoring with Informative Sub-Claim Identification
Jul 04, 2024

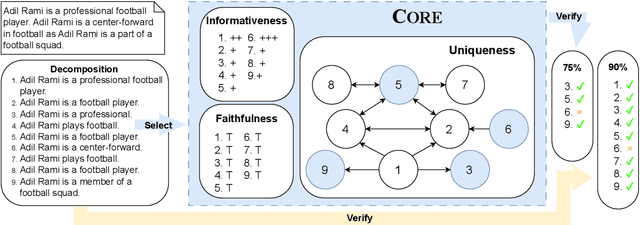

Hallucinations -- the generation of untrue claims -- pose a challenge to the application of large language models (LLMs) [1] thereby motivating the development of metrics to evaluate factual precision. We observe that popular metrics using the Decompose-Then-Verify framework, such as FActScore [2], can be manipulated by adding obvious or repetitive claims to artificially inflate scores. We expand the FActScore dataset to design and analyze factual precision metrics, demonstrating that models can be trained to achieve high scores under existing metrics through exploiting the issues we identify. This motivates our new customizable plug-and-play subclaim selection component called Core, which filters down individual subclaims according to their uniqueness and informativeness. Metrics augmented by Core are substantially more robust as shown in head-to-head comparisons. We release an evaluation framework supporting the modular use of Core (https://github.com/zipJiang/Core) and various decomposition strategies, and we suggest its adoption by the LLM community. [1] Hong et al., "The Hallucinations Leaderboard -- An Open Effort to Measure Hallucinations in Large Language Models", arXiv:2404.05904v2 [cs.CL]. [2] Min et al., "FActScore: Fine-grained Atomic Evaluation of Factual Precision in Long Form Text Generation", arXiv:2305.14251v2 [cs.CL].
Learning to Reason via Program Generation, Emulation, and Search
May 28, 2024Program synthesis with language models (LMs) has unlocked a large set of reasoning abilities; code-tuned LMs have proven adept at generating programs that solve a wide variety of algorithmic symbolic manipulation tasks (e.g. word concatenation). However, not all reasoning tasks are easily expressible as code, e.g. tasks involving commonsense reasoning, moral decision-making, and sarcasm understanding. Our goal is to extend an LM's program synthesis skills to such tasks and evaluate the results via pseudo-programs, namely Python programs where some leaf function calls are left undefined. To that end, we propose, Code Generation and Emulated EXecution (CoGEX). CoGEX works by (1) training LMs to generate their own pseudo-programs, (2) teaching them to emulate their generated program's execution, including those leaf functions, allowing the LM's knowledge to fill in the execution gaps; and (3) using them to search over many programs to find an optimal one. To adapt the CoGEX model to a new task, we introduce a method for performing program search to find a single program whose pseudo-execution yields optimal performance when applied to all the instances of a given dataset. We show that our approach yields large improvements compared to standard in-context learning approaches on a battery of tasks, both algorithmic and soft reasoning. This result thus demonstrates that code synthesis can be applied to a much broader class of problems than previously considered. Our released dataset, fine-tuned models, and implementation can be found at \url{https://github.com/nweir127/CoGEX}.
SELF-CORRECT: LLMs Struggle with Refining Self-Generated Responses
Apr 04, 2024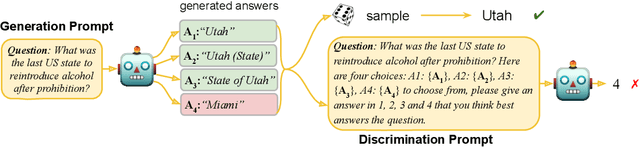

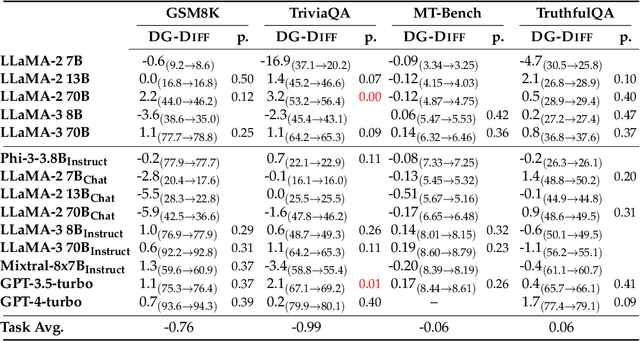

Can LLMs continually improve their previous outputs for better results? An affirmative answer would require LLMs to be better at discriminating among previously-generated alternatives, than generating initial responses. We explore the validity of this hypothesis in practice. We first introduce a unified framework that allows us to compare the generative and discriminative capability of any model on any task. Then, in our resulting experimental analysis of several LLMs, we do not observe the performance of those models on discrimination to be reliably better than generation. We hope these findings inform the growing literature on self-improvement AI systems.
TV-TREES: Multimodal Entailment Trees for Neuro-Symbolic Video Reasoning
Mar 11, 2024It is challenging to perform question-answering over complex, multimodal content such as television clips. This is in part because current video-language models rely on single-modality reasoning, have lowered performance on long inputs, and lack interpetability. We propose TV-TREES, the first multimodal entailment tree generator. TV-TREES serves as an approach to video understanding that promotes interpretable joint-modality reasoning by producing trees of entailment relationships between simple premises directly entailed by the videos and higher-level conclusions. We then introduce the task of multimodal entailment tree generation to evaluate the reasoning quality of such methods. Our method's experimental results on the challenging TVQA dataset demonstrate intepretable, state-of-the-art zero-shot performance on full video clips, illustrating a best-of-both-worlds contrast to black-box methods.
Enhancing Systematic Decompositional Natural Language Inference Using Informal Logic
Feb 27, 2024Contemporary language models enable new opportunities for structured reasoning with text, such as the construction and evaluation of intuitive, proof-like textual entailment trees without relying on brittle formal logic. However, progress in this direction has been hampered by a long-standing lack of a clear protocol for determining what valid compositional entailment is. This absence causes noisy datasets and limited performance gains by modern neuro-symbolic engines. To address these problems, we formulate a consistent and theoretically grounded approach to annotating decompositional entailment datasets, and evaluate its impact on LLM-based textual inference. We find that our resulting dataset, RDTE (Recognizing Decompositional Textual Entailment), has a substantially higher internal consistency (+9%) than prior decompositional entailment datasets, suggesting that RDTE is a significant step forward in the long-standing problem of forming a clear protocol for discerning entailment. We also find that training an RDTE-oriented entailment classifier via knowledge distillation and employing it in a modern neuro-symbolic reasoning engine significantly improves results (both accuracy and proof quality) over other entailment classifier baselines, illustrating the practical benefit of this advance for textual inference.
Reframing Tax Law Entailment as Analogical Reasoning
Jan 12, 2024Statutory reasoning refers to the application of legislative provisions to a series of case facts described in natural language. We re-frame statutory reasoning as an analogy task, where each instance of the analogy task involves a combination of two instances of statutory reasoning. This increases the dataset size by two orders of magnitude, and introduces an element of interpretability. We show that this task is roughly as difficult to Natural Language Processing models as the original task. Finally, we come back to statutory reasoning, solving it with a combination of a retrieval mechanism and analogy models, and showing some progress on prior comparable work.