 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-Parametric Machine Text Detection via Multi-View Gaussian Processes
Jun 12, 2026Adversarial conditions such as paraphrasing and targeted style transfer sharply degrade the accuracy of machine text detectors. A document, however, carries multiple complementary signals (e.g., stylistic features, likelihood and rank-order features, and structural features), and an attack that suppresses one may leave others intact. While a parametric classifier can learn to combine these features given sufficient supervision, classifiers are prone to making confidently incorrect predictions when the distribution shifts (e.g., novel attacks or unseen language models). To address this, we propose a multi-view, non-parametric detection framework that extracts complementary feature views from the same document and aggregates per-view evidence through a Gaussian process ensemble. By aggregating evidence across views, an adversary must simultaneously defeat multiple independent axes of detection, substantially raising the cost of evasion. The Gaussian process formulation additionally provides calibrated probabilities and principled abstention on out-of-distribution inputs, supporting reliable deployment in high-stakes settings. We evaluate on three benchmarks spanning diverse generators and attacks: the DetectRL and RAID benchmarks, and the PAN2025 shared task and demonstrate that our multi-view detector maintains strong performance under the considered attacks, outperforming existing approaches against held out attacks.
Learning Extrapolative Sequence Transformations from Markov Chains
May 26, 2025Most successful applications of deep learning involve similar training and test conditions. However, tasks such as biological sequence design involve searching for sequences that improve desirable properties beyond previously known values, which requires novel hypotheses that \emph{extrapolate} beyond training data. In these settings, extrapolation may be achieved by using random search methods such as Markov chain Monte Carlo (MCMC), which, given an initial state, sample local transformations to approximate a target density that rewards states with the desired properties. However, even with a well-designed proposal, MCMC may struggle to explore large structured state spaces efficiently. Rather than relying on stochastic search, it would be desirable to have a model that greedily optimizes the properties of interest, successfully extrapolating in as few steps as possible. We propose to learn such a model from the Markov chains resulting from MCMC search. Specifically, our approach uses selected states from Markov chains as a source of training data for an autoregressive model, which is then able to efficiently generate novel sequences that extrapolate along the sequence-level properties of interest. The proposed approach is validated on three problems: protein sequence design, text sentiment control, and text anonymization. We find that the autoregressive model can extrapolate as well or better than MCMC, but with the additional benefits of scalability and significantly higher sample efficiency.
AdapterSwap: Continuous Training of LLMs with Data Removal and Access-Control Guarantees
Apr 12, 2024Large language models (LLMs) are increasingly capable of completing knowledge intensive tasks by recalling information from a static pretraining corpus. Here we are concerned with LLMs in the context of evolving data requirements. For instance: batches of new data that are introduced periodically; subsets of data with user-based access controls; or requirements on dynamic removal of documents with guarantees that associated knowledge cannot be recalled. We wish to satisfy these requirements while at the same time ensuring a model does not forget old information when new data becomes available. To address these issues, we introduce AdapterSwap, a training and inference scheme that organizes knowledge from a data collection into a set of low-rank adapters, which are dynamically composed during inference. Our experiments demonstrate AdapterSwap's ability to support efficient continual learning, while also enabling organizations to have fine-grained control over data access and deletion.
Few-Shot Detection of Machine-Generated Text using Style Representations
Jan 12, 2024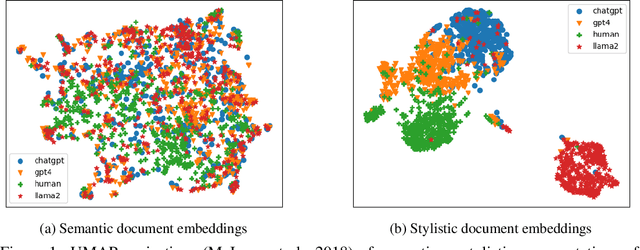
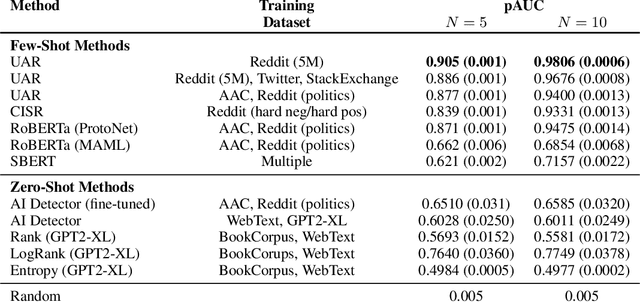
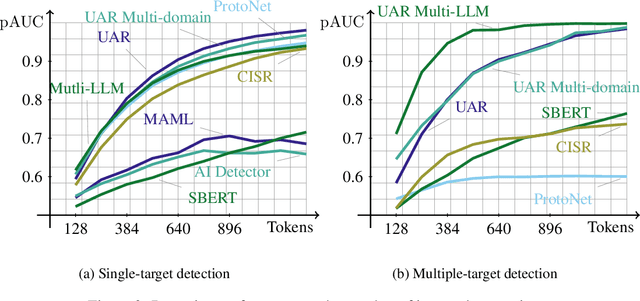
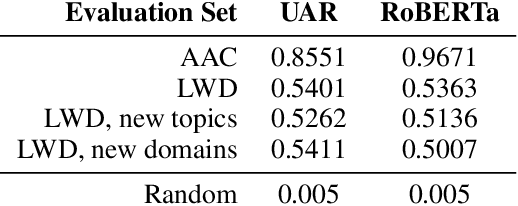
The advent of instruction-tuned language models that convincingly mimic human writing poses a significant risk of abuse. For example, such models could be used for plagiarism, disinformation, spam, or phishing. However, such abuse may be counteracted with the ability to detect whether a piece of text was composed by a language model rather than a human. Some previous approaches to this problem have relied on supervised methods trained on corpora of confirmed human and machine-written documents. Unfortunately, model under-specification poses an unavoidable challenge for neural network-based detectors, making them brittle in the face of data shifts, such as the release of further language models producing still more fluent text than the models used to train the detectors. Other previous approaches require access to the models that may have generated a document in question at inference or detection time, which is often impractical. In light of these challenges, we pursue a fundamentally different approach not relying on samples from language models of concern at training time. Instead, we propose to leverage representations of writing style estimated from human-authored text. Indeed, we find that features effective at distinguishing among human authors are also effective at distinguishing human from machine authors, including state of the art large language models like Llama 2, ChatGPT, and GPT-4. Furthermore, given a handful of examples composed by each of several specific language models of interest, our approach affords the ability to predict which model generated a given document.
Learning to Generate Text in Arbitrary Writing Styles
Dec 28, 2023Prior work in style-controlled text generation has focused on tasks such as emulating the style of prolific literary authors, producing formal or informal text, and the degree of toxicity of generated text. Plentiful demonstrations of these styles are available, and as a result modern language models are often able to emulate them, either via prompting or discriminative control. However, in applications such as writing assistants, it is desirable for language models to produce text in an author-specific style on the basis of a small writing sample. We find that instruction-tuned language models can struggle to reproduce author-specific style demonstrated in a prompt. Instead, we propose to guide a language model to generate text in a target style using contrastively-trained representations that capture stylometric features. A central challenge in doing so is that an author's writing is characterized by surprising token choices under a generic language model. To reconcile this tension, we combine generative re-scoring to achieve an author-specific model, with discriminative control to ensure style consistency at the sequence-level. The combination of these approaches is found to be particularly effective at adhering to an author-specific style in a variety of conditions, including unconditional generation and style transfer, and is applicable to any underlying language model without requiring fine-tuning.
Defending Against Poisoning Attacks in Open-Domain Question Answering
Dec 20, 2022Recent work in open-domain question answering (ODQA) has shown that adversarial poisoning of the input contexts can cause large drops in accuracy for production systems. However, little to no work has proposed methods to defend against these attacks. To do so, we introduce a new method that uses query augmentation to search for a diverse set of retrieved passages that could answer the original question. We integrate these new passages into the model through the design of a novel confidence method, comparing the predicted answer to its appearance in the retrieved contexts (what we call Confidence from Answer Redundancy, e.g. CAR). Together these methods allow for a simple but effective way to defend against poisoning attacks and provide gains of 5-20% exact match across varying levels of data poisoning.
A Deep Metric Learning Approach to Account Linking
May 15, 2021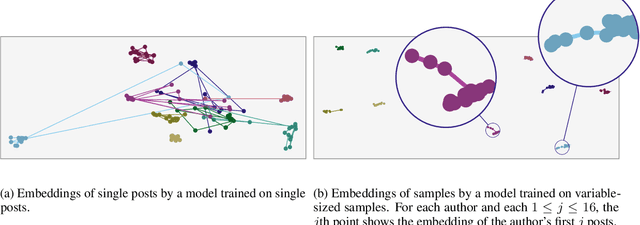
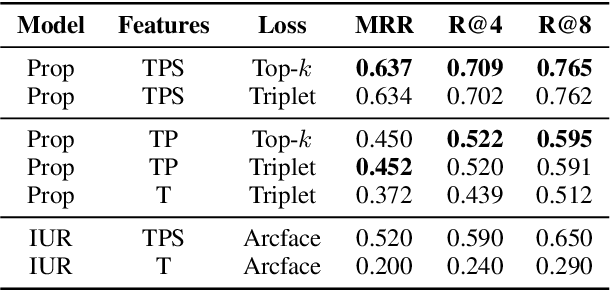
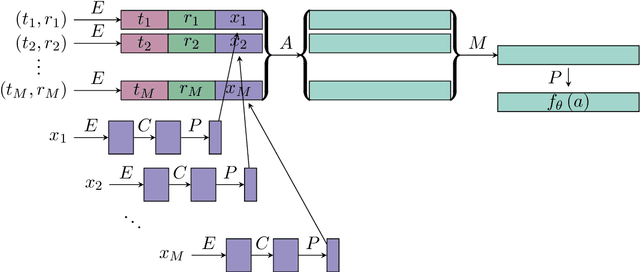
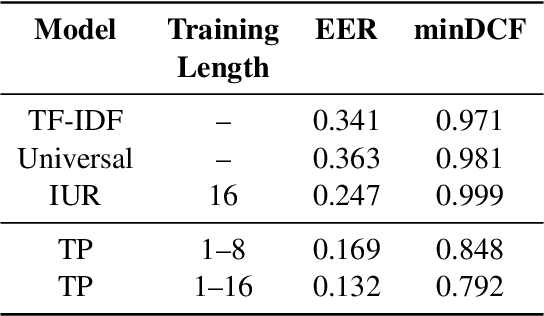
We consider the task of linking social media accounts that belong to the same author in an automated fashion on the basis of the content and metadata of their corresponding document streams. We focus on learning an embedding that maps variable-sized samples of user activity -- ranging from single posts to entire months of activity -- to a vector space, where samples by the same author map to nearby points. The approach does not require human-annotated data for training purposes, which allows us to leverage large amounts of social media content. The proposed model outperforms several competitive baselines under a novel evaluation framework modeled after established recognition benchmarks in other domains. Our method achieves high linking accuracy, even with small samples from accounts not seen at training time, a prerequisite for practical applications of the proposed linking framework.