 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConformal Thinking: Risk Control for Reasoning on a Compute Budget
Feb 03, 2026Reasoning Large Language Models (LLMs) enable test-time scaling, with dataset-level accuracy improving as the token budget increases, motivating adaptive reasoning -- spending tokens when they improve reliability and stopping early when additional computation is unlikely to help. However, setting the token budget, as well as the threshold for adaptive reasoning, is a practical challenge that entails a fundamental risk-accuracy trade-off. We re-frame the budget setting problem as risk control, limiting the error rate while minimizing compute. Our framework introduces an upper threshold that stops reasoning when the model is confident (risking incorrect output) and a novel parametric lower threshold that preemptively stops unsolvable instances (risking premature stoppage). Given a target risk and a validation set, we use distribution-free risk control to optimally specify these stopping mechanisms. For scenarios with multiple budget controlling criteria, we incorporate an efficiency loss to select the most computationally efficient exiting mechanism. Empirical results across diverse reasoning tasks and models demonstrate the effectiveness of our risk control approach, demonstrating computational efficiency gains from the lower threshold and ensemble stopping mechanisms while adhering to the user-specified risk target.
RANKVIDEO: Reasoning Reranking for Text-to-Video Retrieval
Feb 03, 2026Reranking is a critical component of modern retrieval systems, which typically pair an efficient first-stage retriever with a more expressive model to refine results. While large reasoning models have driven rapid progress in text-centric reranking, reasoning-based reranking for video retrieval remains underexplored. To address this gap, we introduce RANKVIDEO, a reasoning-based reranker for video retrieval that explicitly reasons over query-video pairs using video content to assess relevance. RANKVIDEO is trained using a two-stage curriculum consisting of perception-grounded supervised fine-tuning followed by reranking training that combines pointwise, pairwise, and teacher confidence distillation objectives, and is supported by a data synthesis pipeline for constructing reasoning-intensive query-video pairs. Experiments on the large-scale MultiVENT 2.0 benchmark demonstrate that RANKVIDEO consistently improves retrieval performance within a two-stage framework, yielding an average improvement of 31% on nDCG@10 and outperforming text-only and vision-language reranking alternatives, while more efficient.
HLTCOE Evaluation Team at TREC 2025: VQA Track
Dec 08, 2025The HLTCOE Evaluation team participated in TREC VQA's Answer Generation (AG) task, for which we developed a listwise learning framework that aims to improve semantic precision and ranking consistency in answer generation. Given a video-question pair, a base multimodal model first generates multiple candidate answers, which are then reranked using a model trained with a novel Masked Pointer Cross-Entropy Loss with Rank Weights. This objective integrates pointer-based candidate selection, rank-dependent weighting, and masked cross-entropy under vocabulary restriction, enabling stable and interpretable listwise optimization. By bridging generative modeling with discriminative ranking, our method produces coherent, fine-grained answer lists. Experiments reveal consistent gains in accuracy and ranking stability, especially for questions requiring temporal reasoning and semantic disambiguation.
All Claims Are Equal, but Some Claims Are More Equal Than Others: Importance-Sensitive Factuality Evaluation of LLM Generations
Oct 08, 2025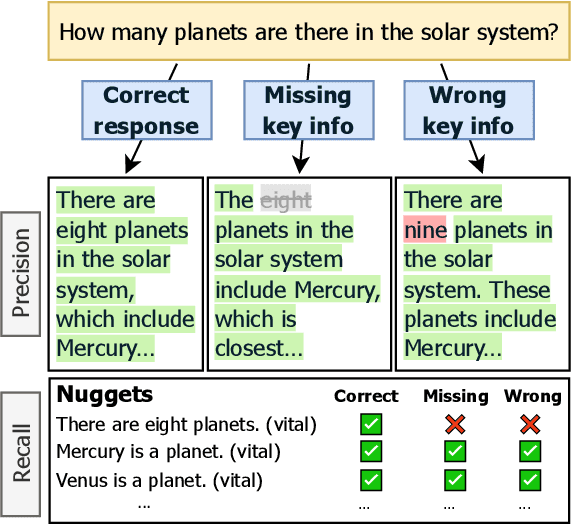
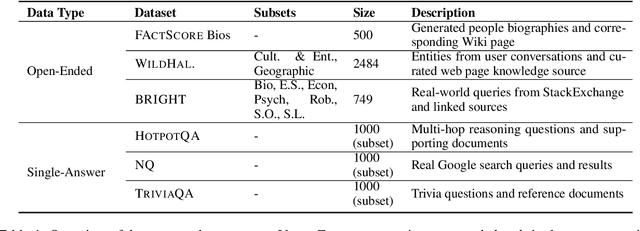
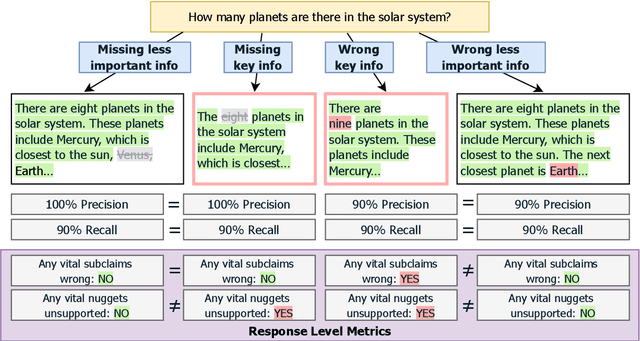

Existing methods for evaluating the factuality of large language model (LLM) responses treat all claims as equally important. This results in misleading evaluations when vital information is missing or incorrect as it receives the same weight as peripheral details, raising the question: how can we reliably detect such differences when there are errors in key information? Current approaches that measure factuality tend to be insensitive to omitted or false key information. To investigate this lack of sensitivity, we construct VITALERRORS, a benchmark of 6,733 queries with minimally altered LLM responses designed to omit or falsify key information. Using this dataset, we demonstrate the insensitivities of existing evaluation metrics to key information errors. To address this gap, we introduce VITAL, a set of metrics that provide greater sensitivity in measuring the factuality of responses by incorporating the relevance and importance of claims with respect to the query. Our analysis demonstrates that VITAL metrics more reliably detect errors in key information than previous methods. Our dataset, metrics, and analysis provide a foundation for more accurate and robust assessment of LLM factuality.
mmBERT: A Modern Multilingual Encoder with Annealed Language Learning
Sep 08, 2025Encoder-only languages models are frequently used for a variety of standard machine learning tasks, including classification and retrieval. However, there has been a lack of recent research for encoder models, especially with respect to multilingual models. We introduce mmBERT, an encoder-only language model pretrained on 3T tokens of multilingual text in over 1800 languages. To build mmBERT we introduce several novel elements, including an inverse mask ratio schedule and an inverse temperature sampling ratio. We add over 1700 low-resource languages to the data mix only during the decay phase, showing that it boosts performance dramatically and maximizes the gains from the relatively small amount of training data. Despite only including these low-resource languages in the short decay phase we achieve similar classification performance to models like OpenAI's o3 and Google's Gemini 2.5 Pro. Overall, we show that mmBERT significantly outperforms the previous generation of models on classification and retrieval tasks -- on both high and low-resource languages.
Enabling Equitable Access to Trustworthy Financial Reasoning
Aug 28, 2025According to the United States Internal Revenue Service, ''the average American spends $\$270$ and 13 hours filing their taxes''. Even beyond the U.S., tax filing requires complex reasoning, combining application of overlapping rules with numerical calculations. Because errors can incur costly penalties, any automated system must deliver high accuracy and auditability, making modern large language models (LLMs) poorly suited for this task. We propose an approach that integrates LLMs with a symbolic solver to calculate tax obligations. We evaluate variants of this system on the challenging StAtutory Reasoning Assessment (SARA) dataset, and include a novel method for estimating the cost of deploying such a system based on real-world penalties for tax errors. We further show how combining up-front translation of plain-text rules into formal logic programs, combined with intelligently retrieved exemplars for formal case representations, can dramatically improve performance on this task and reduce costs to well below real-world averages. Our results demonstrate the promise and economic feasibility of neuro-symbolic architectures for increasing equitable access to reliable tax assistance.
MegaWika 2: A More Comprehensive Multilingual Collection of Articles and their Sources
Aug 05, 2025We introduce MegaWika 2, a large, multilingual dataset of Wikipedia articles with their citations and scraped web sources; articles are represented in a rich data structure, and scraped source texts are stored inline with precise character offsets of their citations in the article text. MegaWika 2 is a major upgrade from the original MegaWika, spanning six times as many articles and twice as many fully scraped citations. Both MegaWika and MegaWika 2 support report generation research ; whereas MegaWika also focused on supporting question answering and retrieval applications, MegaWika 2 is designed to support fact checking and analyses across time and language.
Seq vs Seq: An Open Suite of Paired Encoders and Decoders
Jul 15, 2025The large language model (LLM) community focuses almost exclusively on decoder-only language models, since they are easier to use for text generation. However, a large subset of the community still uses encoder-only models for tasks such as classification or retrieval. Previous work has attempted to compare these architectures, but is forced to make comparisons with models that have different numbers of parameters, training techniques, and datasets. We introduce the SOTA open-data Ettin suite of models: paired encoder-only and decoder-only models ranging from 17 million parameters to 1 billion, trained on up to 2 trillion tokens. Using the same recipe for both encoder-only and decoder-only models produces SOTA recipes in both categories for their respective sizes, beating ModernBERT as an encoder and Llama 3.2 and SmolLM2 as decoders. Like previous work, we find that encoder-only models excel at classification and retrieval tasks while decoders excel at generative tasks. However, we show that adapting a decoder model to encoder tasks (and vice versa) through continued training is subpar compared to using only the reverse objective (i.e. a 400M encoder outperforms a 1B decoder on MNLI, and vice versa for generative tasks). We open-source all artifacts of this study including training data, training order segmented by checkpoint, and 200+ checkpoints to allow future work to analyze or extend all aspects of training.
How Grounded is Wikipedia? A Study on Structured Evidential Support
Jun 14, 2025Wikipedia is a critical resource for modern NLP, serving as a rich repository of up-to-date and citation-backed information on a wide variety of subjects. The reliability of Wikipedia -- its groundedness in its cited sources -- is vital to this purpose. This work provides a quantitative analysis of the extent to which Wikipedia *is* so grounded and of how readily grounding evidence may be retrieved. To this end, we introduce PeopleProfiles -- a large-scale, multi-level dataset of claim support annotations on Wikipedia articles of notable people. We show that roughly 20% of claims in Wikipedia *lead* sections are unsupported by the article body; roughly 27% of annotated claims in the article *body* are unsupported by their (publicly accessible) cited sources; and >80% of lead claims cannot be traced to these sources via annotated body evidence. Further, we show that recovery of complex grounding evidence for claims that *are* supported remains a challenge for standard retrieval methods.
Jailbreak Distillation: Renewable Safety Benchmarking
May 28, 2025Large language models (LLMs) are rapidly deployed in critical applications, raising urgent needs for robust safety benchmarking. We propose Jailbreak Distillation (JBDistill), a novel benchmark construction framework that "distills" jailbreak attacks into high-quality and easily-updatable safety benchmarks. JBDistill utilizes a small set of development models and existing jailbreak attack algorithms to create a candidate prompt pool, then employs prompt selection algorithms to identify an effective subset of prompts as safety benchmarks. JBDistill addresses challenges in existing safety evaluation: the use of consistent evaluation prompts across models ensures fair comparisons and reproducibility. It requires minimal human effort to rerun the JBDistill pipeline and produce updated benchmarks, alleviating concerns on saturation and contamination. Extensive experiments demonstrate our benchmarks generalize robustly to 13 diverse evaluation models held out from benchmark construction, including proprietary, specialized, and newer-generation LLMs, significantly outperforming existing safety benchmarks in effectiveness while maintaining high separability and diversity. Our framework thus provides an effective, sustainable, and adaptable solution for streamlining safety evaluation.