 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Function Demonstrations Improve Generation in Low-Resource Programming Languages
Paper and Code
Mar 24, 2025
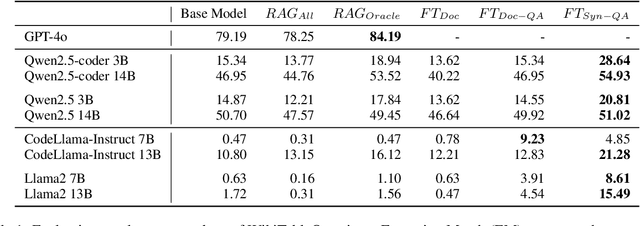
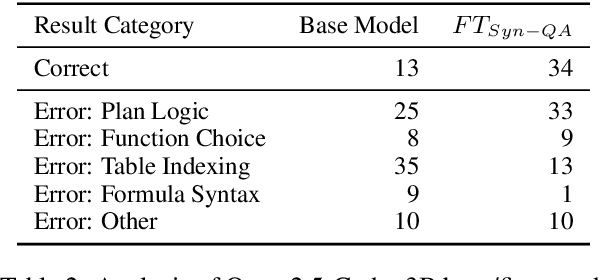

A key consideration when training an LLM is whether the target language is more or less resourced, whether this is English compared to Welsh, or Python compared to Excel. Typical training data for programming languages consist of real program demonstrations coupled with human-written comments. Here we present novel approaches to the creation of such data for low resource programming languages. We generate fully-synthetic, textbook-quality demonstrations of common library functions in an example domain of Excel formulas, using a teacher model. We then finetune an underperforming student model, and show improvement on 2 question-answering datasets recast into the Excel domain. We show advantages of finetuning over standard, off-the-shelf RAG approaches, which can offer only modest improvement due to the unfamiliar target domain.