 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Function Demonstrations Improve Generation in Low-Resource Programming Languages
Mar 24, 2025
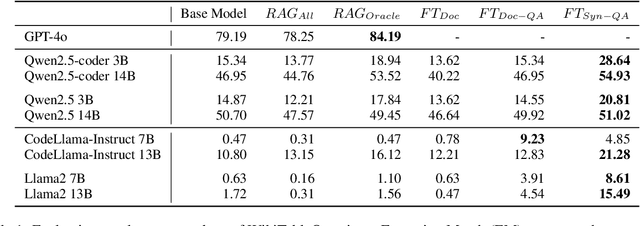

A key consideration when training an LLM is whether the target language is more or less resourced, whether this is English compared to Welsh, or Python compared to Excel. Typical training data for programming languages consist of real program demonstrations coupled with human-written comments. Here we present novel approaches to the creation of such data for low resource programming languages. We generate fully-synthetic, textbook-quality demonstrations of common library functions in an example domain of Excel formulas, using a teacher model. We then finetune an underperforming student model, and show improvement on 2 question-answering datasets recast into the Excel domain. We show advantages of finetuning over standard, off-the-shelf RAG approaches, which can offer only modest improvement due to the unfamiliar target domain.
Synthetic Clarification and Correction Dialogues about Data-Centric Tasks -- A Teacher-Student Approach
Mar 18, 2025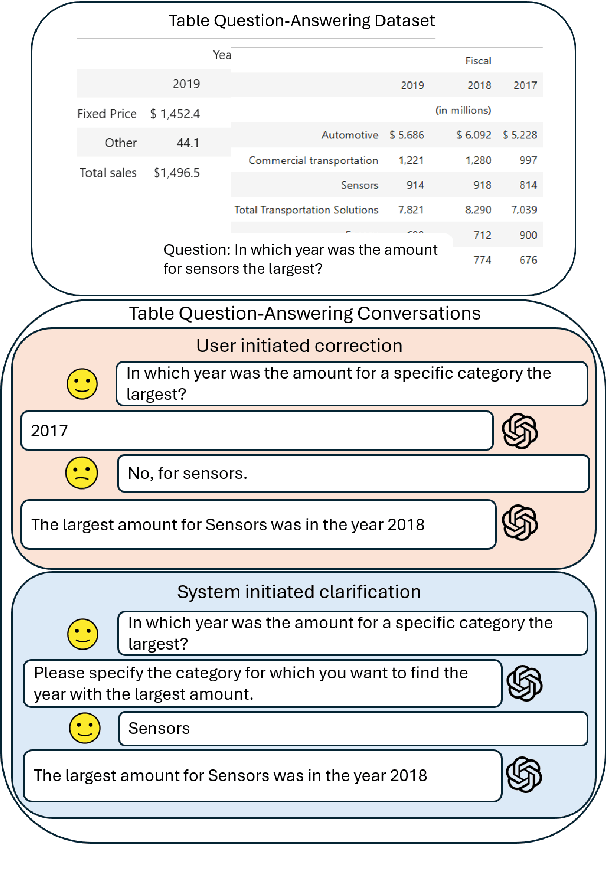
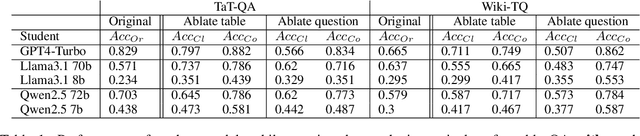
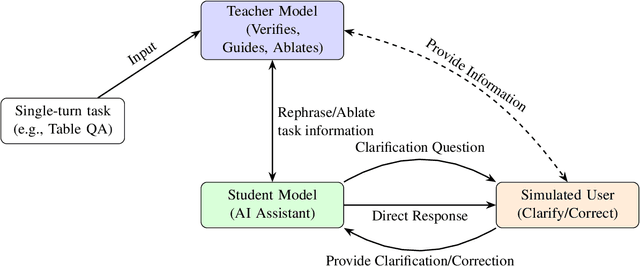
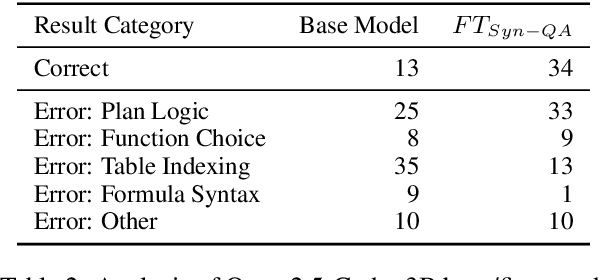
Real dialogues with AI assistants for solving data-centric tasks often follow dynamic, unpredictable paths due to imperfect information provided by the user or in the data, which must be caught and handled. Developing datasets which capture such user-AI interactions is difficult and time-consuming. In this work, we develop a novel framework for synthetically generating controlled, multi-turn conversations between a user and AI assistant for the task of table-based question answering, which can be generated from an existing dataset with fully specified table QA examples for any target domain. Each conversation aims to solve a table-based reasoning question through collaborative effort, modeling one of two real-world scenarios: (1) an AI-initiated clarification, or (2) a user-initiated correction. Critically, we employ a strong teacher LLM to verify the correctness of our synthetic conversations, ensuring high quality. We demonstrate synthetic datasets generated from TAT-QA and WikiTableQuestions as benchmarks of frontier LLMs. We find that even larger models struggle to effectively issuing clarification questions and accurately integrate user feedback for corrections.
Evaluating the Evaluator: Measuring LLMs' Adherence to Task Evaluation Instructions
Aug 16, 2024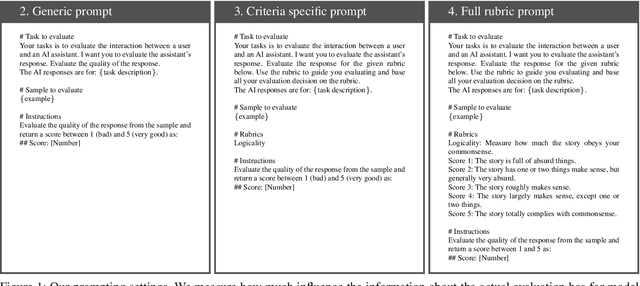
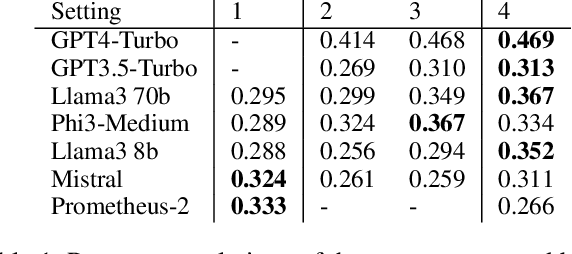
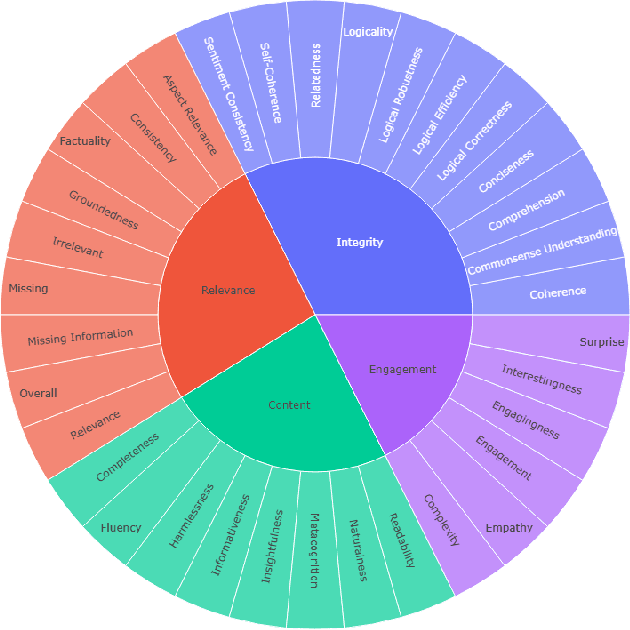
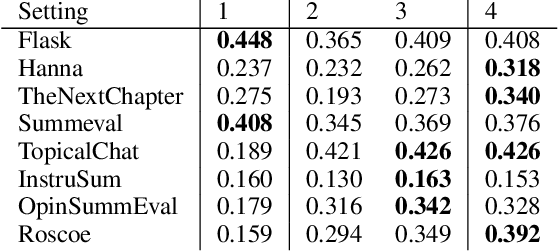
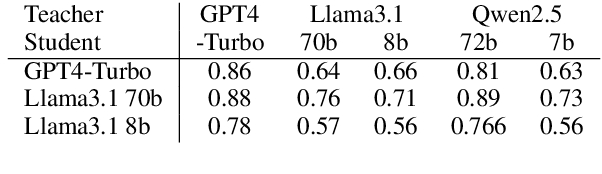
LLMs-as-a-judge is a recently popularized method which replaces human judgements in task evaluation (Zheng et al. 2024) with automatic evaluation using LLMs. Due to widespread use of RLHF (Reinforcement Learning from Human Feedback), state-of-the-art LLMs like GPT4 and Llama3 are expected to have strong alignment with human preferences when prompted for a quality judgement, such as the coherence of a text. While this seems beneficial, it is not clear whether the assessments by an LLM-as-a-judge constitute only an evaluation based on the instructions in the prompts, or reflect its preference for high-quality data similar to its fine-tune data. To investigate how much influence prompting the LLMs-as-a-judge has on the alignment of AI judgements to human judgements, we analyze prompts with increasing levels of instructions about the target quality of an evaluation, for several LLMs-as-a-judge. Further, we compare to a prompt-free method using model perplexity as a quality measure instead. We aggregate a taxonomy of quality criteria commonly used across state-of-the-art evaluations with LLMs and provide this as a rigorous benchmark of models as judges. Overall, we show that the LLMs-as-a-judge benefit only little from highly detailed instructions in prompts and that perplexity can sometimes align better with human judgements than prompting, especially on textual quality.
Sources of Hallucination by Large Language Models on Inference Tasks
May 23, 2023
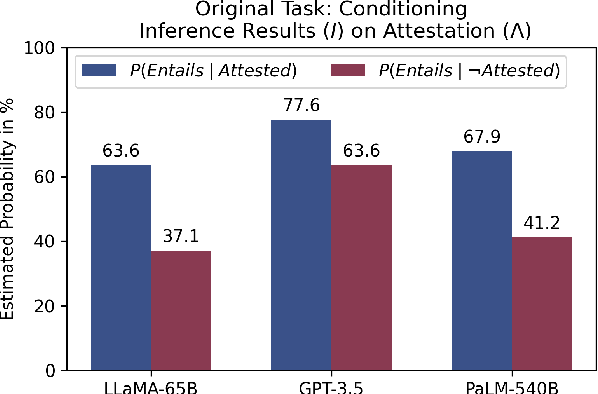

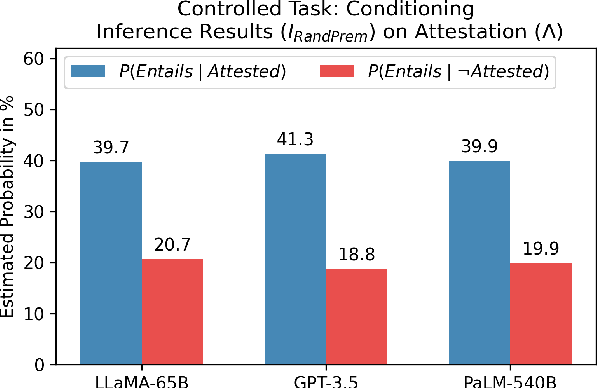
Large Language Models (LLMs) are claimed to be capable of Natural Language Inference (NLI), necessary for applied tasks like question answering and summarization, yet this capability is under-explored. We present a series of behavioral studies on several LLM families (LLaMA, GPT-3.5, and PaLM) which probe their behavior using controlled experiments. We establish two factors which predict much of their performance, and propose that these are major sources of hallucination in generative LLM. First, the most influential factor is memorization of the training data. We show that models falsely label NLI test samples as entailing when the hypothesis is attested in the training text, regardless of the premise. We further show that named entity IDs are used as "indices" to access the memorized data. Second, we show that LLMs exploit a further corpus-based heuristic using the relative frequencies of words. We show that LLMs score significantly worse on NLI test samples which do not conform to these factors than those which do; we also discuss a tension between the two factors, and a performance trade-off.
Smoothing Entailment Graphs with Language Models
Jul 30, 2022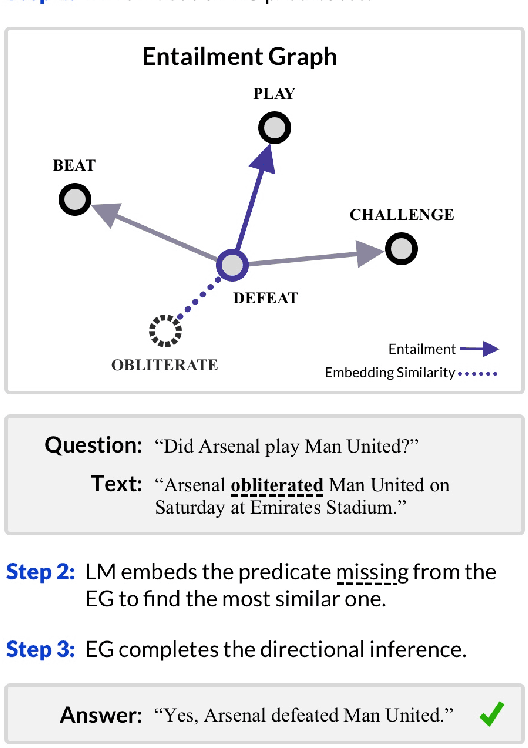


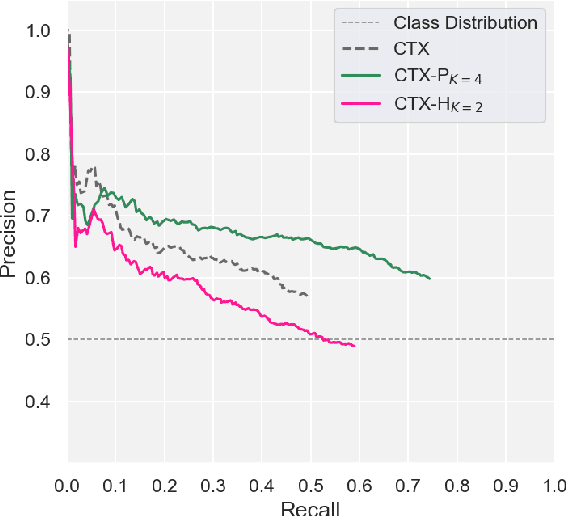
The diversity and Zipfian frequency distribution of natural language predicates in corpora leads to sparsity when learning Entailment Graphs. As symbolic models for natural language inference, an EG cannot recover if missing a novel premise or hypothesis at test-time. In this paper we approach the problem of vertex sparsity by introducing a new method of graph smoothing, using a Language Model to find the nearest approximations of missing predicates. We improve recall by 25.1 and 16.3 absolute percentage points on two difficult directional entailment datasets while exceeding average precision, and show a complementarity with other improvements to edge sparsity. We further analyze language model embeddings and discuss why they are naturally suitable for premise-smoothing, but not hypothesis-smoothing. Finally, we formalize a theory for smoothing a symbolic inference method by constructing transitive chains to smooth both the premise and hypothesis.
Modality and Negation in Event Extraction
Sep 20, 2021
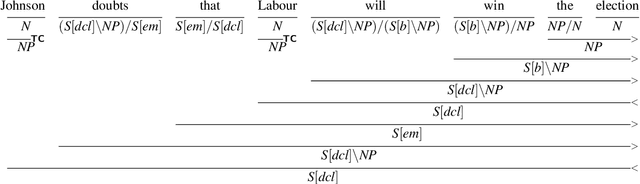
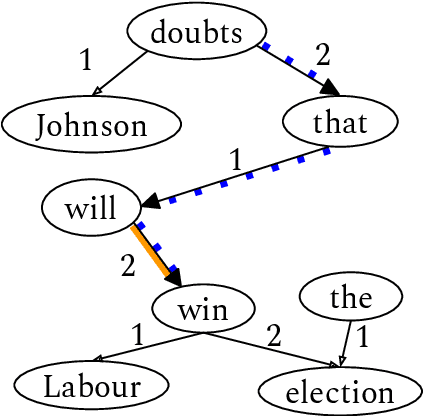
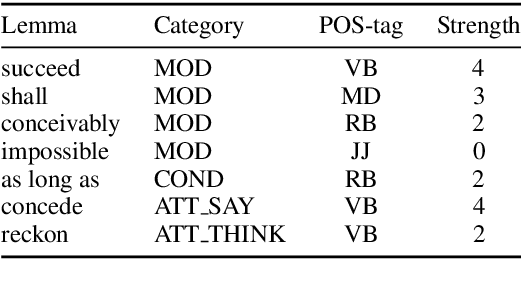
Language provides speakers with a rich system of modality for expressing thoughts about events, without being committed to their actual occurrence. Modality is commonly used in the political news domain, where both actual and possible courses of events are discussed. NLP systems struggle with these semantic phenomena, often incorrectly extracting events which did not happen, which can lead to issues in downstream applications. We present an open-domain, lexicon-based event extraction system that captures various types of modality. This information is valuable for Question Answering, Knowledge Graph construction and Fact-checking tasks, and our evaluation shows that the system is sufficiently strong to be used in downstream applications.
* S. Bijl de Vroe, L. Guillou, M. Stanojevi\'c, N. McKenna, and M. Steedman. 2021. Modality and Negation in Event Extraction. In Proceedings of the 4th Workshop on Challenges and Applications of Automated Extraction of Socio-political Events from Text (CASE 2021), pages 31-42, online. Association for Computational Linguistics
Multivalent Entailment Graphs for Question Answering
Apr 16, 2021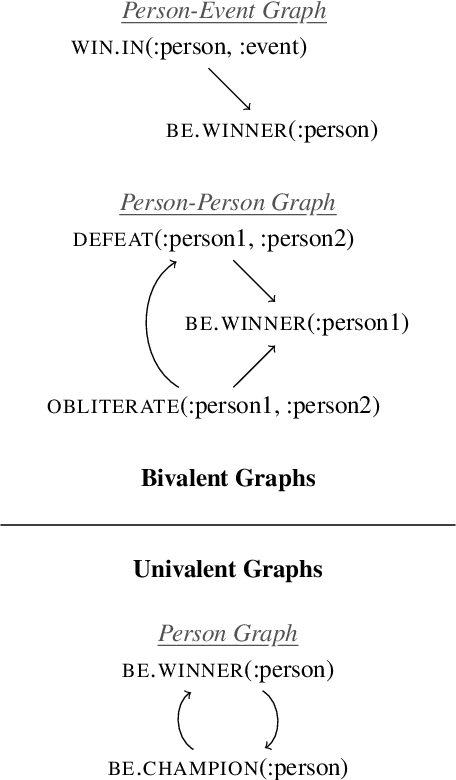
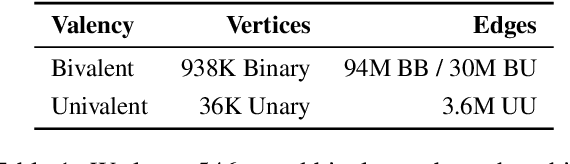

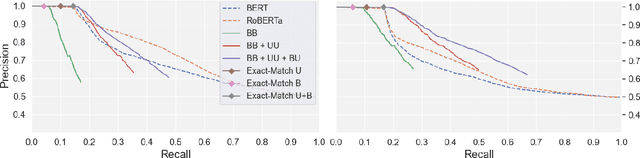
Drawing inferences between open-domain natural language predicates is a necessity for true language understanding. There has been much progress in unsupervised learning of entailment graphs for this purpose. We make three contributions: (1) we reinterpret the Distributional Inclusion Hypothesis to model entailment between predicates of different valencies, like DEFEAT(Biden, Trump) entails WIN(Biden); (2) we actualize this theory by learning unsupervised Multivalent Entailment Graphs of open-domain predicates; and (3) we demonstrate the capabilities of these graphs on a novel question answering task. We show that directional entailment is more helpful for inference than bidirectional similarity on questions of fine-grained semantics. We also show that drawing on evidence across valencies answers more questions than by using only the same valency evidence.