 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSources of Hallucination by Large Language Models on Inference Tasks
Paper and Code

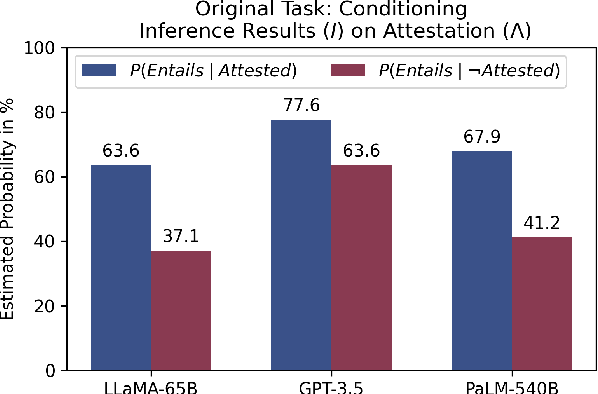

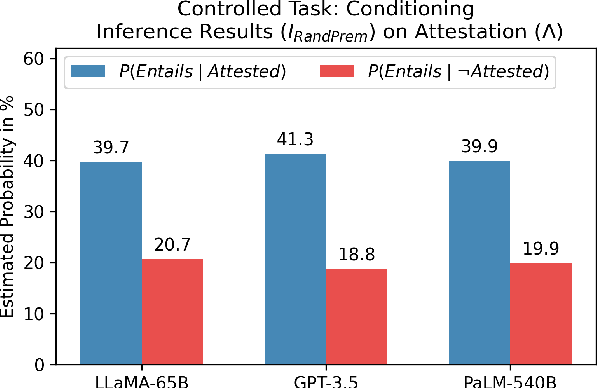
Large Language Models (LLMs) are claimed to be capable of Natural Language Inference (NLI), necessary for applied tasks like question answering and summarization, yet this capability is under-explored. We present a series of behavioral studies on several LLM families (LLaMA, GPT-3.5, and PaLM) which probe their behavior using controlled experiments. We establish two factors which predict much of their performance, and propose that these are major sources of hallucination in generative LLM. First, the most influential factor is memorization of the training data. We show that models falsely label NLI test samples as entailing when the hypothesis is attested in the training text, regardless of the premise. We further show that named entity IDs are used as "indices" to access the memorized data. Second, we show that LLMs exploit a further corpus-based heuristic using the relative frequencies of words. We show that LLMs score significantly worse on NLI test samples which do not conform to these factors than those which do; we also discuss a tension between the two factors, and a performance trade-off.