 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModelling Child Learning and Parsing of Long-range Syntactic Dependencies
Mar 17, 2025


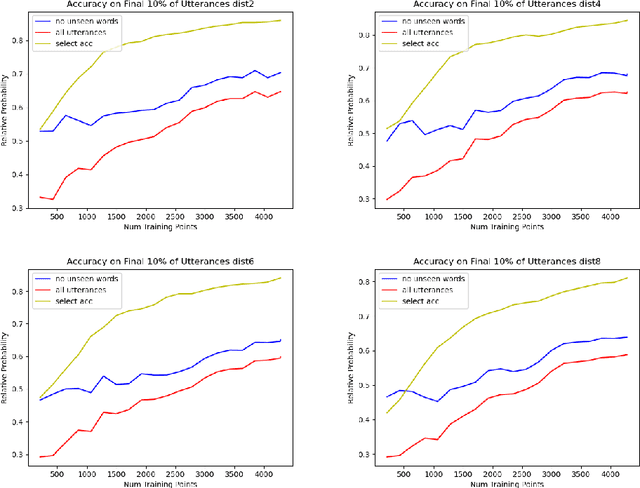
This work develops a probabilistic child language acquisition model to learn a range of linguistic phenonmena, most notably long-range syntactic dependencies of the sort found in object wh-questions, among other constructions. The model is trained on a corpus of real child-directed speech, where each utterance is paired with a logical form as a meaning representation. It then learns both word meanings and language-specific syntax simultaneously. After training, the model can deduce the correct parse tree and word meanings for a given utterance-meaning pair, and can infer the meaning if given only the utterance. The successful modelling of long-range dependencies is theoretically important because it exploits aspects of the model that are, in general, trans-context-free.
A Language-agnostic Model of Child Language Acquisition
Aug 22, 2024



This work reimplements a recent semantic bootstrapping child-language acquisition model, which was originally designed for English, and trains it to learn a new language: Hebrew. The model learns from pairs of utterances and logical forms as meaning representations, and acquires both syntax and word meanings simultaneously. The results show that the model mostly transfers to Hebrew, but that a number of factors, including the richer morphology in Hebrew, makes the learning slower and less robust. This suggests that a clear direction for future work is to enable the model to leverage the similarities between different word forms.
Sources of Hallucination by Large Language Models on Inference Tasks
May 23, 2023
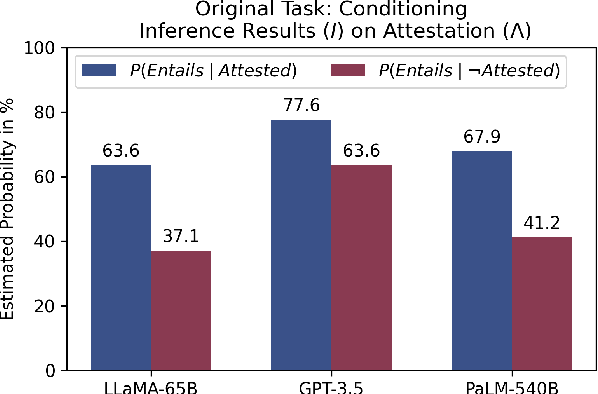

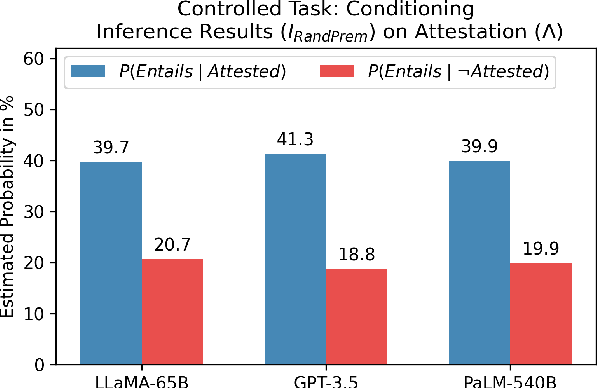
Large Language Models (LLMs) are claimed to be capable of Natural Language Inference (NLI), necessary for applied tasks like question answering and summarization, yet this capability is under-explored. We present a series of behavioral studies on several LLM families (LLaMA, GPT-3.5, and PaLM) which probe their behavior using controlled experiments. We establish two factors which predict much of their performance, and propose that these are major sources of hallucination in generative LLM. First, the most influential factor is memorization of the training data. We show that models falsely label NLI test samples as entailing when the hypothesis is attested in the training text, regardless of the premise. We further show that named entity IDs are used as "indices" to access the memorized data. Second, we show that LLMs exploit a further corpus-based heuristic using the relative frequencies of words. We show that LLMs score significantly worse on NLI test samples which do not conform to these factors than those which do; we also discuss a tension between the two factors, and a performance trade-off.
Three-dimensional Cooperative Localization of Commercial-Off-The-Shelf Sensors
Nov 03, 2021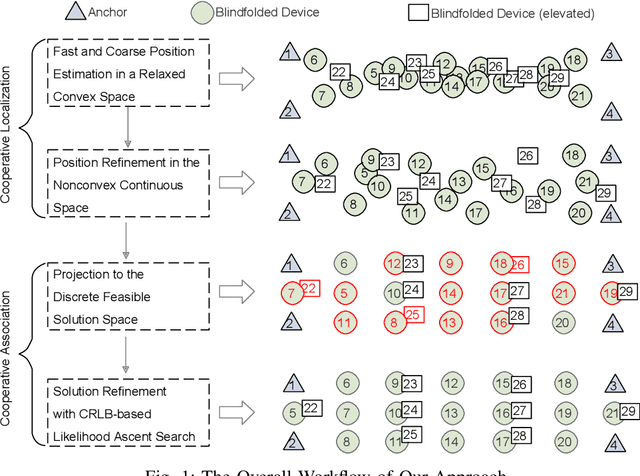
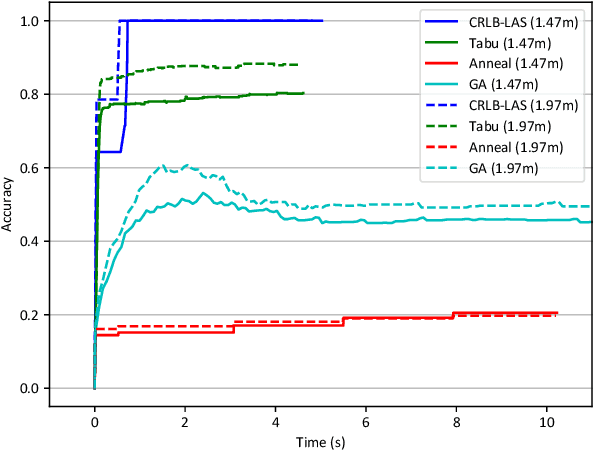
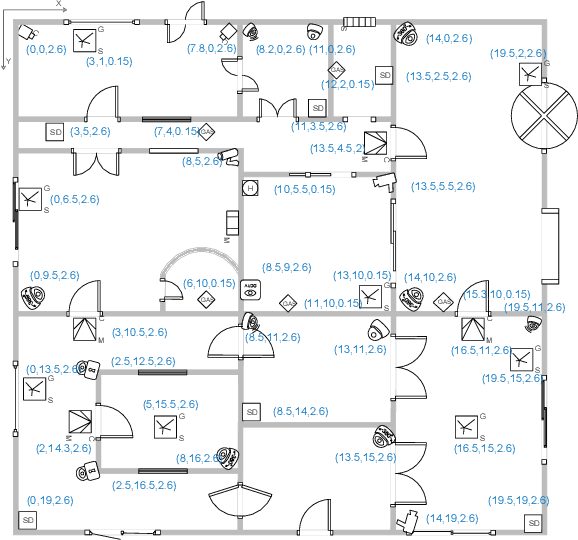
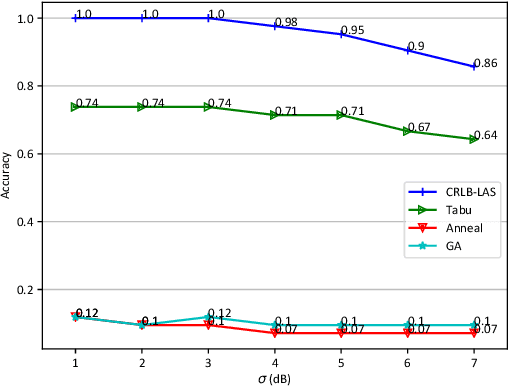
Many location-based services use Received Signal Strength (RSS) measurements due to their universal availability. In this paper, we study the association of a large number of low-cost Internet-of-Things (IoT) sensors and their possible installation locations, which can enable various sensing and automation-related applications. We propose an efficient approach to solve the corresponding permutation combinatorial optimization problem, which integrates continuous space cooperative localization and permutation space likelihood ascent search. A convex relaxation-based optimization is designed to estimate the coarse locations of blindfolded devices in continuous 3D spaces, which are then projected to the feasible permutation space. An efficient Cram\'er-Rao Lower Bound based likelihood ascent search algorithm is proposed to refine the solution. Extensive experiments were conducted to evaluate the performance of the proposed approach, which show that the proposed approach significantly outperforms state-of-the-art combinatorial optimization algorithms and achieves close-to-100% accuracy with affordable execution time.
Blindness to Modality Helps Entailment Graph Mining
Sep 21, 2021
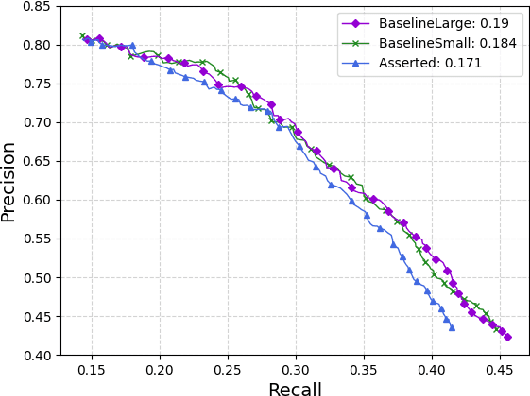
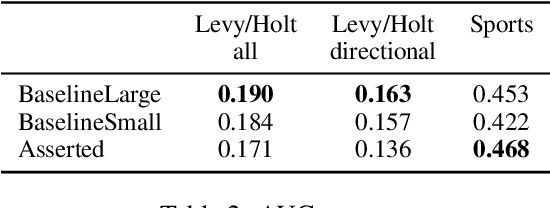
Understanding linguistic modality is widely seen as important for downstream tasks such as Question Answering and Knowledge Graph Population. Entailment Graph learning might also be expected to benefit from attention to modality. We build Entailment Graphs using a news corpus filtered with a modality parser, and show that stripping modal modifiers from predicates in fact increases performance. This suggests that for some tasks, the pragmatics of modal modification of predicates allows them to contribute as evidence of entailment.
Incorporating Temporal Information in Entailment Graph Mining
Sep 20, 2021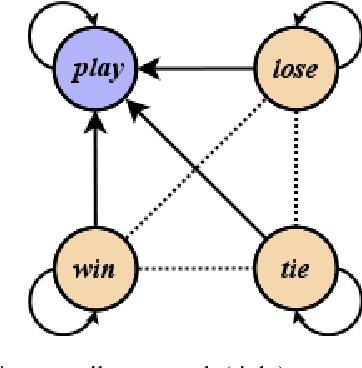
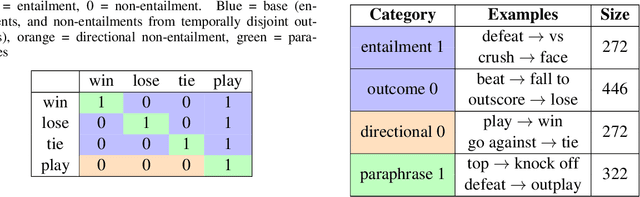
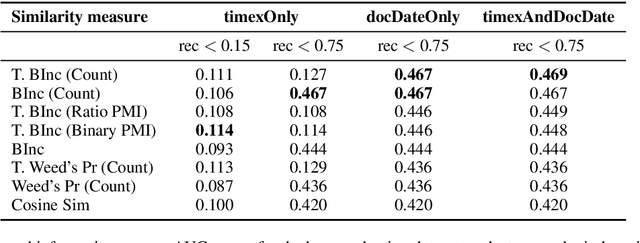
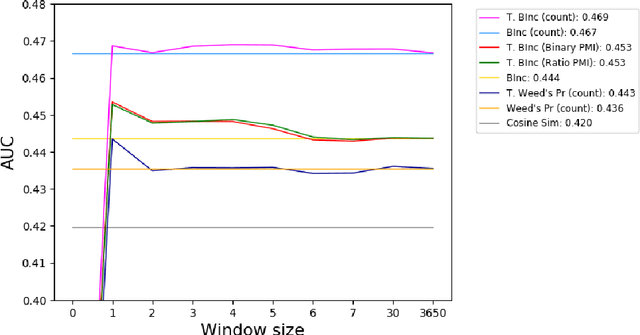
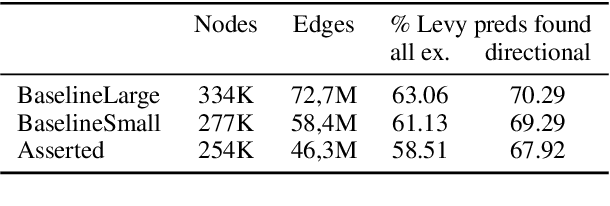
We present a novel method for injecting temporality into entailment graphs to address the problem of spurious entailments, which may arise from similar but temporally distinct events involving the same pair of entities. We focus on the sports domain in which the same pairs of teams play on different occasions, with different outcomes. We present an unsupervised model that aims to learn entailments such as win/lose $\rightarrow$ play, while avoiding the pitfall of learning non-entailments such as win $\not\rightarrow$ lose. We evaluate our model on a manually constructed dataset, showing that incorporating time intervals and applying a temporal window around them, are effective strategies.
* L. Guillou, S. Bijl de Vroe, M.J. Hosseini, M. Johnson, and M. Steedman. 2020. Incorporating temporal information in entailment graph mining. In Proceedings of the Graph-based Methods for Natural Language Processing (TextGraphs), pages 60-71, Barcelona, Spain (Online). Association for Computational Linguistics
Neural Rule-Execution Tracking Machine For Transformer-Based Text Generation
Jul 27, 2021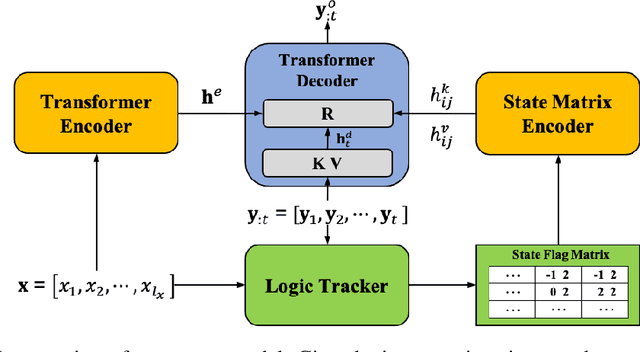

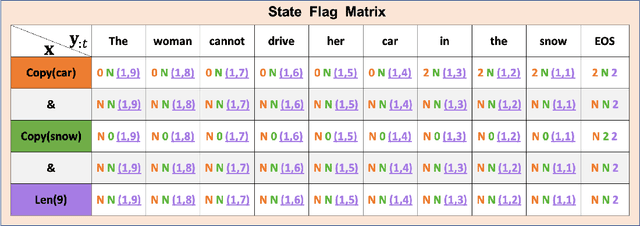
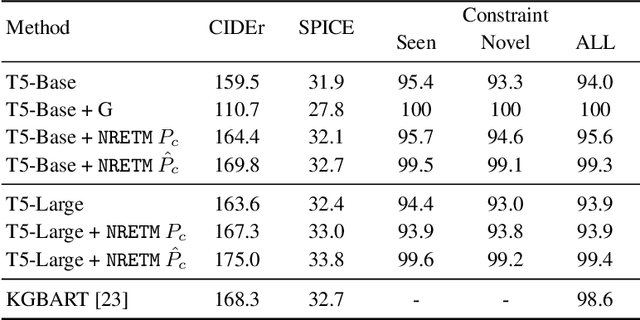
Sequence-to-Sequence (S2S) neural text generation models, especially the pre-trained ones (e.g., BART and T5), have exhibited compelling performance on various natural language generation tasks. However, the black-box nature of these models limits their application in tasks where specific rules (e.g., controllable constraints, prior knowledge) need to be executed. Previous works either design specific model structure (e.g., Copy Mechanism corresponding to the rule "the generated output should include certain words in the source input") or implement specialized inference algorithm (e.g., Constrained Beam Search) to execute particular rules through the text generation. These methods require careful design case-by-case and are difficult to support multiple rules concurrently. In this paper, we propose a novel module named Neural Rule-Execution Tracking Machine that can be equipped into various transformer-based generators to leverage multiple rules simultaneously to guide the neural generation model for superior generation performance in a unified and scalable way. Extensive experimental results on several benchmarks verify the effectiveness of our proposed model in both controllable and general text generation.
There and Back Again: Self-supervised Multispectral Correspondence Estimation
Mar 19, 2021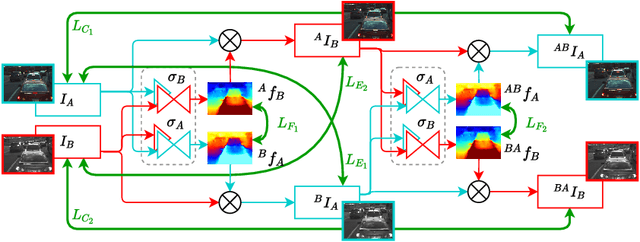
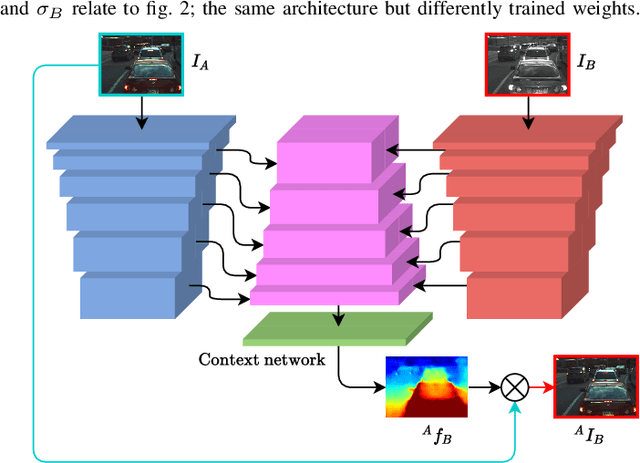

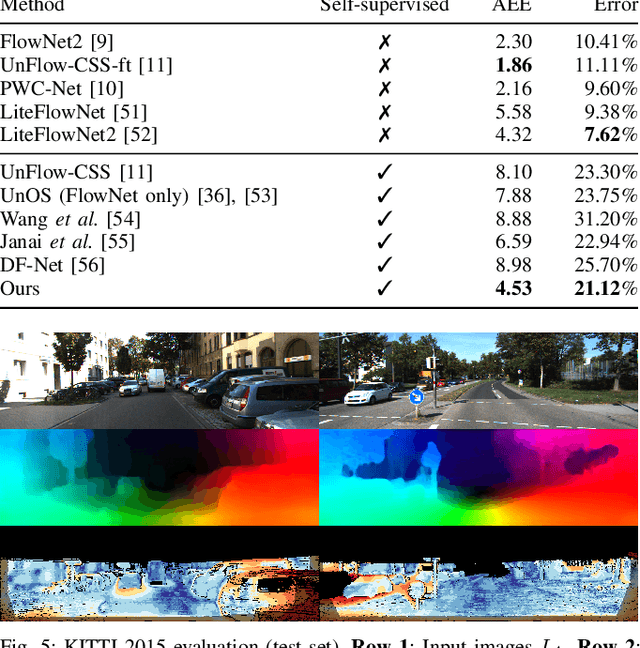
Across a wide range of applications, from autonomous vehicles to medical imaging, multi-spectral images provide an opportunity to extract additional information not present in color images. One of the most important steps in making this information readily available is the accurate estimation of dense correspondences between different spectra. Due to the nature of cross-spectral images, most correspondence solving techniques for the visual domain are simply not applicable. Furthermore, most cross-spectral techniques utilize spectra-specific characteristics to perform the alignment. In this work, we aim to address the dense correspondence estimation problem in a way that generalizes to more than one spectrum. We do this by introducing a novel cycle-consistency metric that allows us to self-supervise. This, combined with our spectra-agnostic loss functions, allows us to train the same network across multiple spectra. We demonstrate our approach on the challenging task of dense RGB-FIR correspondence estimation. We also show the performance of our unmodified network on the cases of RGB-NIR and RGB-RGB, where we achieve higher accuracy than similar self-supervised approaches. Our work shows that cross-spectral correspondence estimation can be solved in a common framework that learns to generalize alignment across spectra.
ECOL-R: Encouraging Copying in Novel Object Captioning with Reinforcement Learning
Jan 25, 2021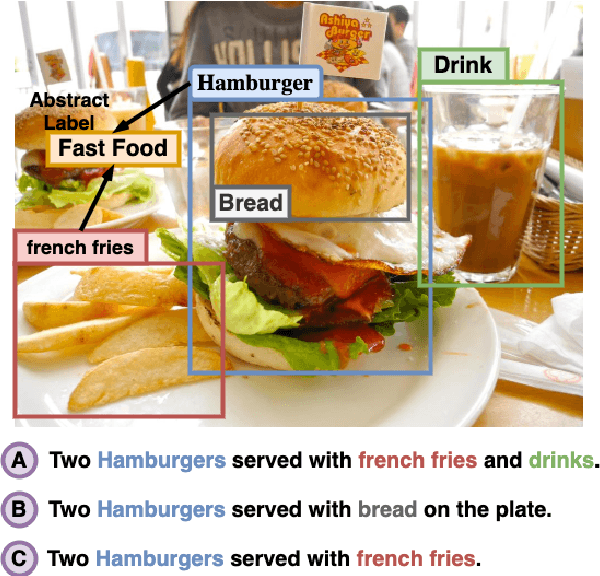
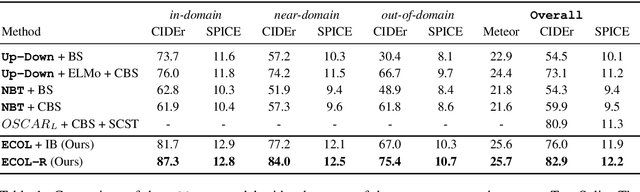

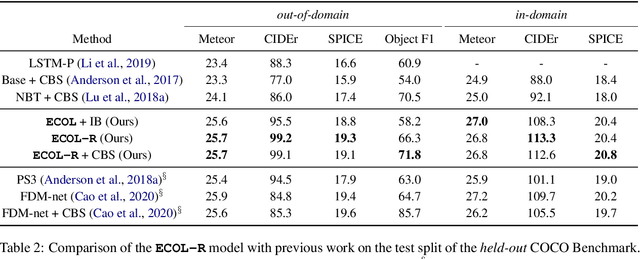
Novel Object Captioning is a zero-shot Image Captioning task requiring describing objects not seen in the training captions, but for which information is available from external object detectors. The key challenge is to select and describe all salient detected novel objects in the input images. In this paper, we focus on this challenge and propose the ECOL-R model (Encouraging Copying of Object Labels with Reinforced Learning), a copy-augmented transformer model that is encouraged to accurately describe the novel object labels. This is achieved via a specialised reward function in the SCST reinforcement learning framework (Rennie et al., 2017) that encourages novel object mentions while maintaining the caption quality. We further restrict the SCST training to the images where detected objects are mentioned in reference captions to train the ECOL-R model. We additionally improve our copy mechanism via Abstract Labels, which transfer knowledge from known to novel object types, and a Morphological Selector, which determines the appropriate inflected forms of novel object labels. The resulting model sets new state-of-the-art on the nocaps (Agrawal et al., 2019) and held-out COCO (Hendricks et al., 2016) benchmarks.
Detecting and Exorcising Statistical Demons from Language Models with Anti-Models of Negative Data
Oct 22, 2020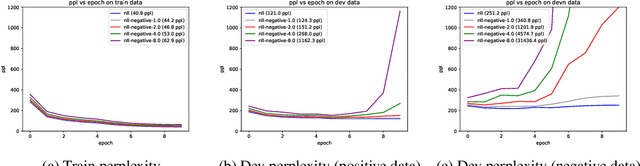
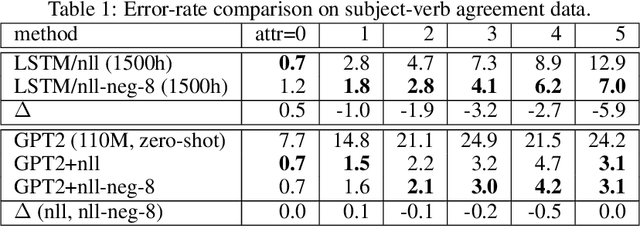
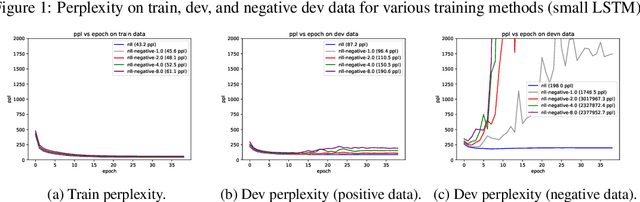
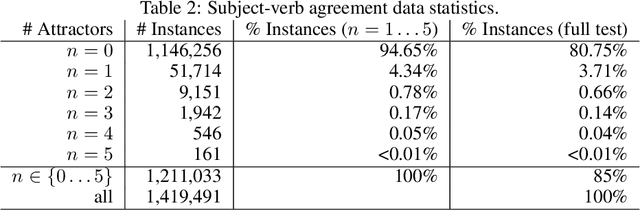
It's been said that "Language Models are Unsupervised Multitask Learners." Indeed, self-supervised language models trained on "positive" examples of English text generalize in desirable ways to many natural language tasks. But if such models can stray so far from an initial self-supervision objective, a wayward model might generalize in undesirable ways too, say to nonsensical "negative" examples of unnatural language. A key question in this work is: do language models trained on (positive) training data also generalize to (negative) test data? We use this question as a contrivance to assess the extent to which language models learn undesirable properties of text, such as n-grams, that might interfere with the learning of more desirable properties of text, such as syntax. We find that within a model family, as the number of parameters, training epochs, and data set size increase, so does a model's ability to generalize to negative n-gram data, indicating standard self-supervision generalizes too far. We propose a form of inductive bias that attenuates such undesirable signals with negative data distributions automatically learned from positive data. We apply the method to remove n-gram signals from LSTMs and find that doing so causes them to favor syntactic signals, as demonstrated by large error reductions (up to 46% on the hardest cases) on a syntactic subject-verb agreement task.