 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCERiL: Continuous Event-based Reinforcement Learning
Feb 15, 2023This paper explores the potential of event cameras to enable continuous time reinforcement learning. We formalise this problem where a continuous stream of unsynchronised observations is used to produce a corresponding stream of output actions for the environment. This lack of synchronisation enables greatly enhanced reactivity. We present a method to train on event streams derived from standard RL environments, thereby solving the proposed continuous time RL problem. The CERiL algorithm uses specialised network layers which operate directly on an event stream, rather than aggregating events into quantised image frames. We show the advantages of event streams over less-frequent RGB images. The proposed system outperforms networks typically used in RL, even succeeding at tasks which cannot be solved traditionally. We also demonstrate the value of our CERiL approach over a standard SNN baseline using event streams.
EDeNN: Event Decay Neural Networks for low latency vision
Sep 09, 2022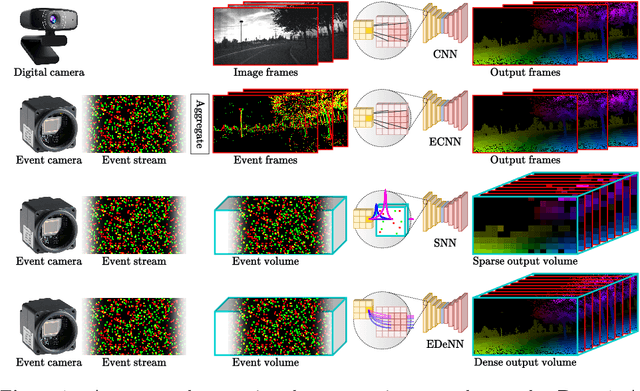

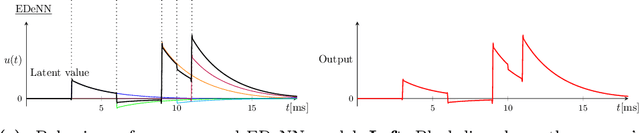
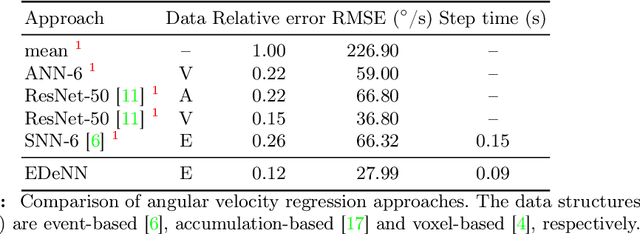
Despite the success of neural networks in computer vision tasks, digital 'neurons' are a very loose approximation of biological neurons. Today's learning approaches are designed to function on digital devices with digital data representations such as image frames. In contrast, biological vision systems are generally much more capable and efficient than state-of-the-art digital computer vision algorithms. Event cameras are an emerging sensor technology which imitates biological vision with asynchronously firing pixels, eschewing the concept of the image frame. To leverage modern learning techniques, many event-based algorithms are forced to accumulate events back to image frames, somewhat squandering the advantages of event cameras. We follow the opposite paradigm and develop a new type of neural network which operates closer to the original event data stream. We demonstrate state-of-the-art performance in angular velocity regression and competitive optical flow estimation, while avoiding difficulties related to training SNN. Furthermore, the processing latency of our proposed approached is less than 1/10 any other implementation, while continuous inference increases this improvement by another order of magnitude.
EVReflex: Dense Time-to-Impact Prediction for Event-based Obstacle Avoidance
Sep 01, 2021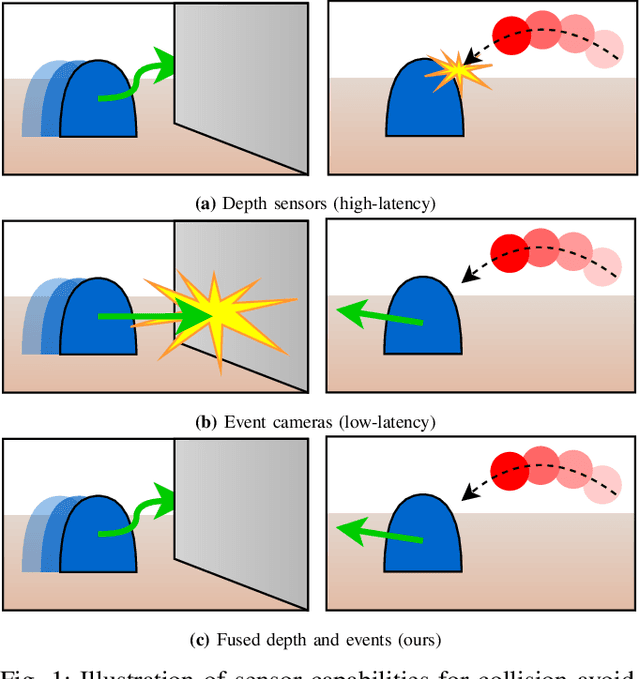
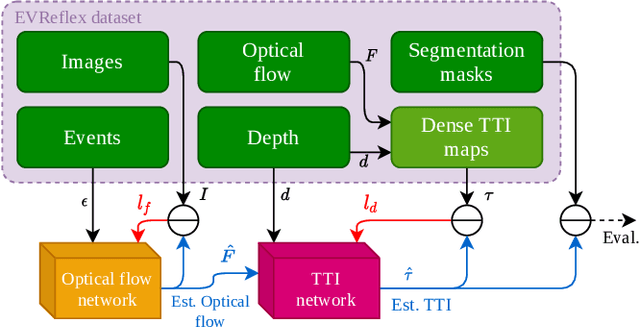
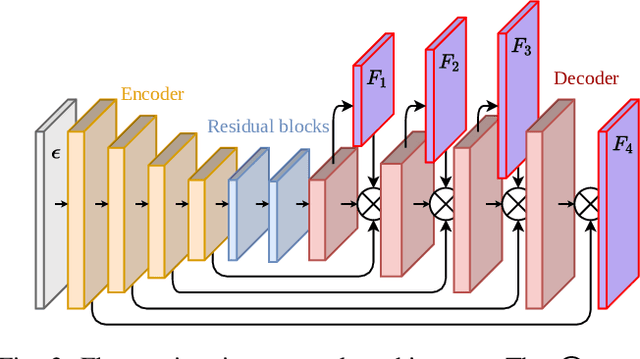
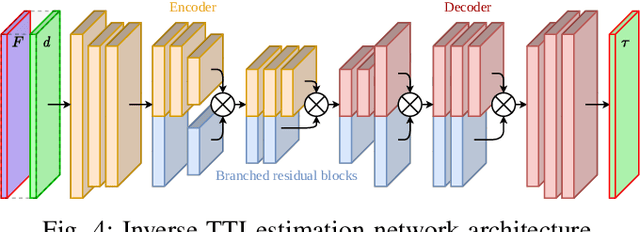
The broad scope of obstacle avoidance has led to many kinds of computer vision-based approaches. Despite its popularity, it is not a solved problem. Traditional computer vision techniques using cameras and depth sensors often focus on static scenes, or rely on priors about the obstacles. Recent developments in bio-inspired sensors present event cameras as a compelling choice for dynamic scenes. Although these sensors have many advantages over their frame-based counterparts, such as high dynamic range and temporal resolution, event-based perception has largely remained in 2D. This often leads to solutions reliant on heuristics and specific to a particular task. We show that the fusion of events and depth overcomes the failure cases of each individual modality when performing obstacle avoidance. Our proposed approach unifies event camera and lidar streams to estimate metric time-to-impact without prior knowledge of the scene geometry or obstacles. In addition, we release an extensive event-based dataset with six visual streams spanning over 700 scanned scenes.
There and Back Again: Self-supervised Multispectral Correspondence Estimation
Mar 19, 2021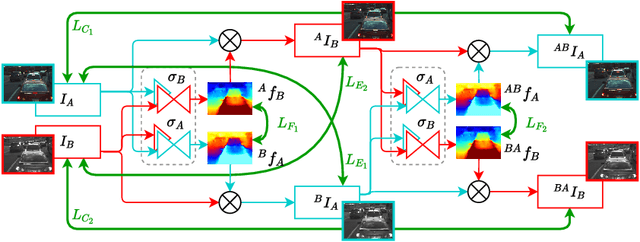
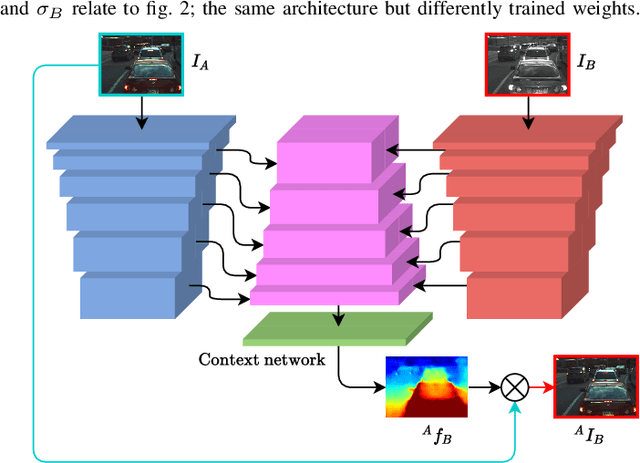

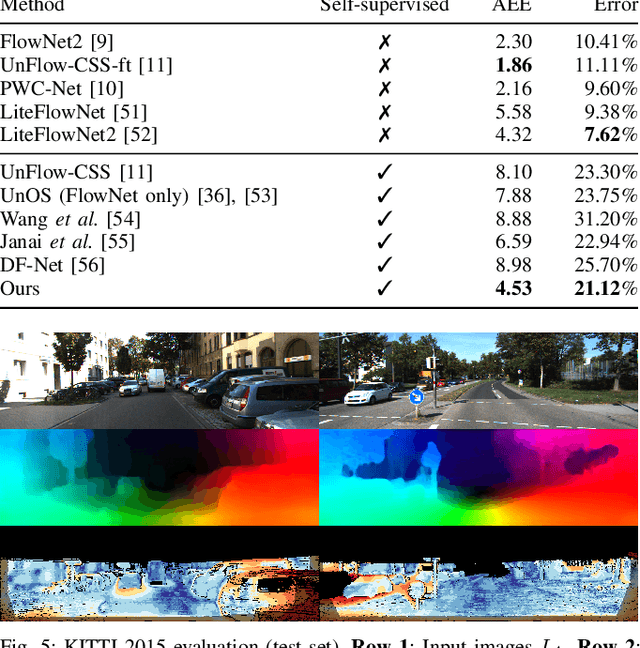
Across a wide range of applications, from autonomous vehicles to medical imaging, multi-spectral images provide an opportunity to extract additional information not present in color images. One of the most important steps in making this information readily available is the accurate estimation of dense correspondences between different spectra. Due to the nature of cross-spectral images, most correspondence solving techniques for the visual domain are simply not applicable. Furthermore, most cross-spectral techniques utilize spectra-specific characteristics to perform the alignment. In this work, we aim to address the dense correspondence estimation problem in a way that generalizes to more than one spectrum. We do this by introducing a novel cycle-consistency metric that allows us to self-supervise. This, combined with our spectra-agnostic loss functions, allows us to train the same network across multiple spectra. We demonstrate our approach on the challenging task of dense RGB-FIR correspondence estimation. We also show the performance of our unmodified network on the cases of RGB-NIR and RGB-RGB, where we achieve higher accuracy than similar self-supervised approaches. Our work shows that cross-spectral correspondence estimation can be solved in a common framework that learns to generalize alignment across spectra.
A Robust Extrinsic Calibration Framework for Vehicles with Unscaled Sensors
Mar 17, 2021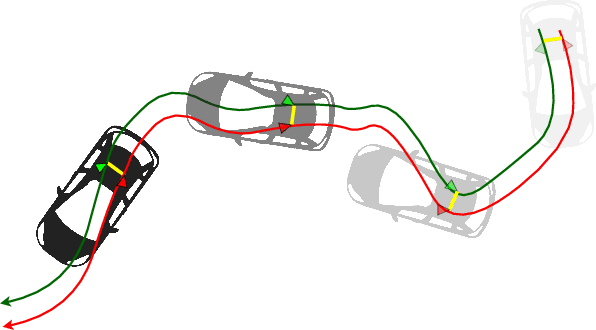
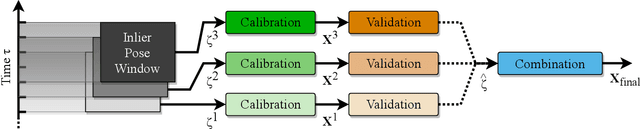
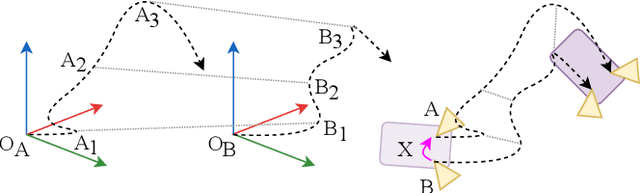
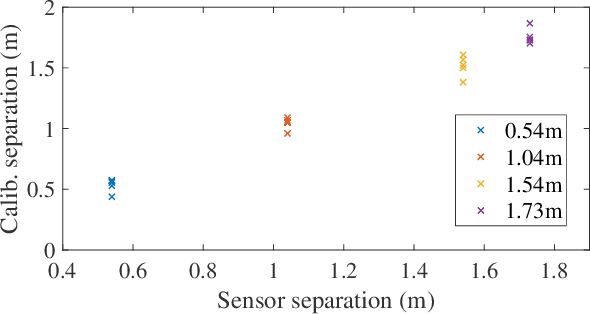
Accurate extrinsic sensor calibration is essential for both autonomous vehicles and robots. Traditionally this is an involved process requiring calibration targets, known fiducial markers and is generally performed in a lab. Moreover, even a small change in the sensor layout requires recalibration. With the anticipated arrival of consumer autonomous vehicles, there is demand for a system which can do this automatically, after deployment and without specialist human expertise. To solve these limitations, we propose a flexible framework which can estimate extrinsic parameters without an explicit calibration stage, even for sensors with unknown scale. Our first contribution builds upon standard hand-eye calibration by jointly recovering scale. Our second contribution is that our system is made robust to imperfect and degenerate sensor data, by collecting independent sets of poses and automatically selecting those which are most ideal. We show that our approach's robustness is essential for the target scenario. Unlike previous approaches, ours runs in real time and constantly estimates the extrinsic transform. For both an ideal experimental setup and a real use case, comparison against these approaches shows that we outperform the state-of-the-art. Furthermore, we demonstrate that the recovered scale may be applied to the full trajectory, circumventing the need for scale estimation via sensor fusion.