 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTACO: Trajectory Aligning Cross-view Optimisation
May 05, 2026Cross-View Geo-localisation (CVGL) matches ground imagery against satellite tiles to give absolute position fixes, an alternative to GNSS where signals are occluded, jammed, or spoofed. Recent fine-grained CVGL methods regress sub-tile metric pose, but have only been evaluated as one-shot localisers, never as the primary fix in a live pipeline. Inertial sensing provides high-rate relative motion, but accumulates unbounded drift without an absolute anchor. We propose TACO, a tightly-coupled IMU + fine-grained CVGL pipeline that consumes a single GNSS reading at start-up and thereafter operates on onboard sensing alone. A closed-form cross-track error model triggers CVGL before IMU drift exceeds the matcher's capture radius, and a forward-biased five-point multi-crop search keeps inference cost fixed at five forward passes per fix. A yaw-residual gate rejects fixes that disagree with the onboard compass, and an anisotropic body-frame noise model scales each Unscented Kalman Filter update by per-fix confidence. A factor graph with vetted loop closures provides an offline smoothed trajectory. On the KITTI raw dataset, TACO reduces median Absolute Trajectory Error (ATE) from 97.0m (IMU-only) to 16.3m, a 5.9 times reduction, at <0.1 ms per-frame fusion cost and a 5-10% camera duty cycle. Code is available: github.com/tavisshore/TACO.
Multi-Domain Learning with Global Expert Mapping
Apr 20, 2026Human perception generalizes well across different domains, but most vision models struggle beyond their training data. This gap motivates multi-dataset learning, where a single model is trained on diverse datasets to improve robustness under domain shifts. However, unified training remains challenging due to inconsistencies in data distributions and label semantics. Mixture-of-Experts (MoE) models provide a scalable solution by routing inputs to specialized subnetworks (experts). Yet, existing MoEs often fail to specialize effectively, as their load-balancing mechanisms enforce uniform input distribution across experts. This fairness conflicts with domain-aware routing, causing experts to learn redundant representations, and reducing performance especially on rare or out-of-distribution domains. We propose GEM (Global Expert Mapping), a planner-compiler framework that replaces the learned router with a global scheduler. Our planner, based on linear programming relaxation, computes a fractional assignment of datasets to experts, while the compiler applies hierarchical rounding to convert this soft plan into a deterministic, capacity-aware mapping. Unlike prior MoEs, GEM avoids balancing loss, resolves the conflict between fairness and specialization, and produces interpretable routing. Experiments show that GEM-DINO achieves state-of-the-art performance on the UODB benchmark, with notable gains on underrepresented datasets and solves task interference in few-shot adaptation scenarios.
FeatureSLAM: Feature-enriched 3D gaussian splatting SLAM in real time
Jan 09, 2026We present a real-time tracking SLAM system that unifies efficient camera tracking with photorealistic feature-enriched mapping using 3D Gaussian Splatting (3DGS). Our main contribution is integrating dense feature rasterization into the novel-view synthesis, aligned with a visual foundation model. This yields strong semantics, going beyond basic RGB-D input, aiding both tracking and mapping accuracy. Unlike previous semantic SLAM approaches (which embed pre-defined class labels) FeatureSLAM enables entirely new downstream tasks via free-viewpoint, open-set segmentation. Across standard benchmarks, our method achieves real-time tracking, on par with state-of-the-art systems while improving tracking stability and map fidelity without prohibitive compute. Quantitatively, we obtain 9\% lower pose error and 8\% higher mapping accuracy compared to recent fixed-set SLAM baselines. Our results confirm that real-time feature-embedded SLAM, is not only valuable for enabling new downstream applications. It also improves the performance of the underlying tracking and mapping subsystems, providing semantic and language masking results that are on-par with offline 3DGS models, alongside state-of-the-art tracking, depth and RGB rendering.
HuGeDiff: 3D Human Generation via Diffusion with Gaussian Splatting
Jun 04, 2025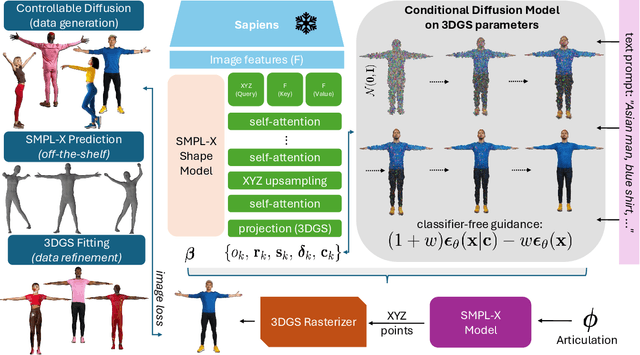
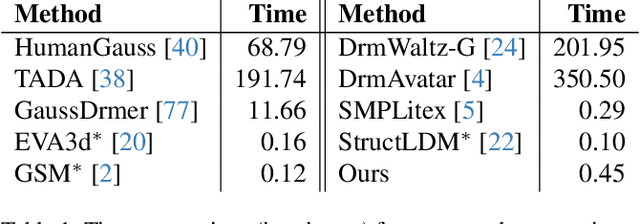
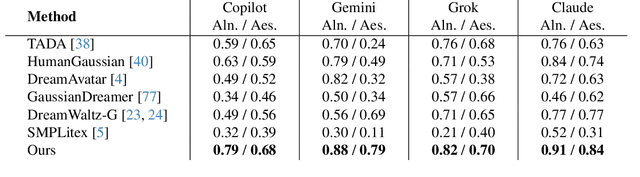

3D human generation is an important problem with a wide range of applications in computer vision and graphics. Despite recent progress in generative AI such as diffusion models or rendering methods like Neural Radiance Fields or Gaussian Splatting, controlling the generation of accurate 3D humans from text prompts remains an open challenge. Current methods struggle with fine detail, accurate rendering of hands and faces, human realism, and controlability over appearance. The lack of diversity, realism, and annotation in human image data also remains a challenge, hindering the development of a foundational 3D human model. We present a weakly supervised pipeline that tries to address these challenges. In the first step, we generate a photorealistic human image dataset with controllable attributes such as appearance, race, gender, etc using a state-of-the-art image diffusion model. Next, we propose an efficient mapping approach from image features to 3D point clouds using a transformer-based architecture. Finally, we close the loop by training a point-cloud diffusion model that is conditioned on the same text prompts used to generate the original samples. We demonstrate orders-of-magnitude speed-ups in 3D human generation compared to the state-of-the-art approaches, along with significantly improved text-prompt alignment, realism, and rendering quality. We will make the code and dataset available.
HandOcc: NeRF-based Hand Rendering with Occupancy Networks
May 04, 2025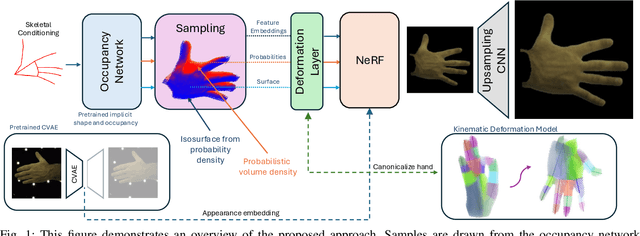
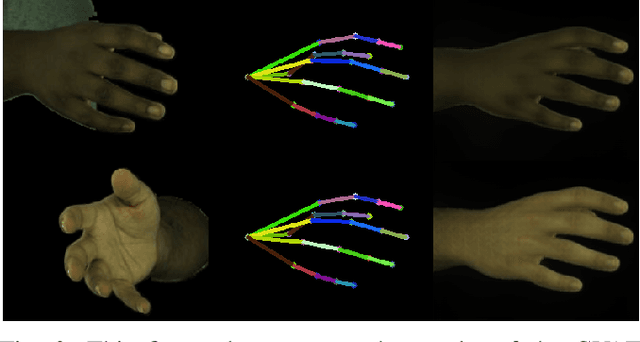

We propose HandOcc, a novel framework for hand rendering based upon occupancy. Popular rendering methods such as NeRF are often combined with parametric meshes to provide deformable hand models. However, in doing so, such approaches present a trade-off between the fidelity of the mesh and the complexity and dimensionality of the parametric model. The simplicity of parametric mesh structures is appealing, but the underlying issue is that it binds methods to mesh initialization, making it unable to generalize to objects where a parametric model does not exist. It also means that estimation is tied to mesh resolution and the accuracy of mesh fitting. This paper presents a pipeline for meshless 3D rendering, which we apply to the hands. By providing only a 3D skeleton, the desired appearance is extracted via a convolutional model. We do this by exploiting a NeRF renderer conditioned upon an occupancy-based representation. The approach uses the hand occupancy to resolve hand-to-hand interactions further improving results, allowing fast rendering, and excellent hand appearance transfer. On the benchmark InterHand2.6M dataset, we achieved state-of-the-art results.
SignSplat: Rendering Sign Language via Gaussian Splatting
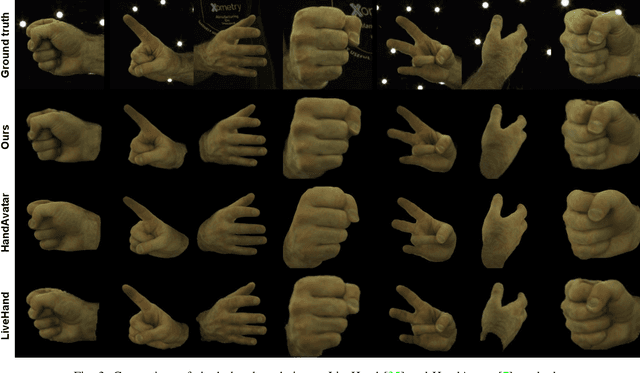
May 04, 2025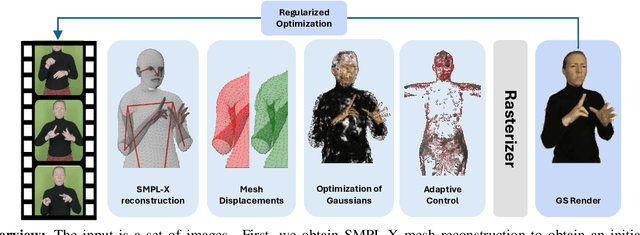
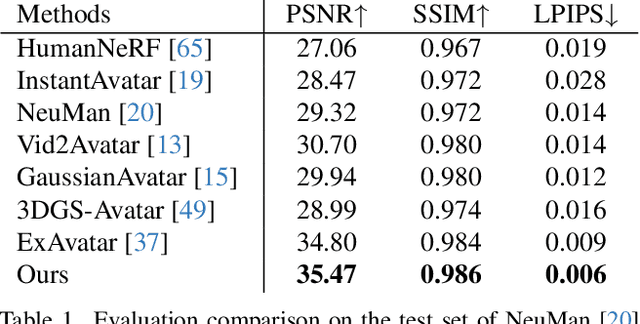


State-of-the-art approaches for conditional human body rendering via Gaussian splatting typically focus on simple body motions captured from many views. This is often in the context of dancing or walking. However, for more complex use cases, such as sign language, we care less about large body motion and more about subtle and complex motions of the hands and face. The problems of building high fidelity models are compounded by the complexity of capturing multi-view data of sign. The solution is to make better use of sequence data, ensuring that we can overcome the limited information from only a few views by exploiting temporal variability. Nevertheless, learning from sequence-level data requires extremely accurate and consistent model fitting to ensure that appearance is consistent across complex motions. We focus on how to achieve this, constraining mesh parameters to build an accurate Gaussian splatting framework from few views capable of modelling subtle human motion. We leverage regularization techniques on the Gaussian parameters to mitigate overfitting and rendering artifacts. Additionally, we propose a new adaptive control method to densify Gaussians and prune splat points on the mesh surface. To demonstrate the accuracy of our approach, we render novel sequences of sign language video, building on neural machine translation approaches to sign stitching. On benchmark datasets, our approach achieves state-of-the-art performance; and on highly articulated and complex sign language motion, we significantly outperform competing approaches.
HyperGS: Hyperspectral 3D Gaussian Splatting
Dec 17, 2024We introduce HyperGS, a novel framework for Hyperspectral Novel View Synthesis (HNVS), based on a new latent 3D Gaussian Splatting (3DGS) technique. Our approach enables simultaneous spatial and spectral renderings by encoding material properties from multi-view 3D hyperspectral datasets. HyperGS reconstructs high-fidelity views from arbitrary perspectives with improved accuracy and speed, outperforming currently existing methods. To address the challenges of high-dimensional data, we perform view synthesis in a learned latent space, incorporating a pixel-wise adaptive density function and a pruning technique for increased training stability and efficiency. Additionally, we introduce the first HNVS benchmark, implementing a number of new baselines based on recent SOTA RGB-NVS techniques, alongside the small number of prior works on HNVS. We demonstrate HyperGS's robustness through extensive evaluation of real and simulated hyperspectral scenes with a 14db accuracy improvement upon previously published models.
The Radiance of Neural Fields: Democratizing Photorealistic and Dynamic Robotic Simulation
Nov 25, 2024



As robots increasingly coexist with humans, they must navigate complex, dynamic environments rich in visual information and implicit social dynamics, like when to yield or move through crowds. Addressing these challenges requires significant advances in vision-based sensing and a deeper understanding of socio-dynamic factors, particularly in tasks like navigation. To facilitate this, robotics researchers need advanced simulation platforms offering dynamic, photorealistic environments with realistic actors. Unfortunately, most existing simulators fall short, prioritizing geometric accuracy over visual fidelity, and employing unrealistic agents with fixed trajectories and low-quality visuals. To overcome these limitations, we developed a simulator that incorporates three essential elements: (1) photorealistic neural rendering of environments, (2) neurally animated human entities with behavior management, and (3) an ego-centric robotic agent providing multi-sensor output. By utilizing advanced neural rendering techniques in a dual-NeRF simulator, our system produces high-fidelity, photorealistic renderings of both environments and human entities. Additionally, it integrates a state-of-the-art Social Force Model to model dynamic human-human and human-robot interactions, creating the first photorealistic and accessible human-robot simulation system powered by neural rendering.
PEnG: Pose-Enhanced Geo-Localisation
Nov 24, 2024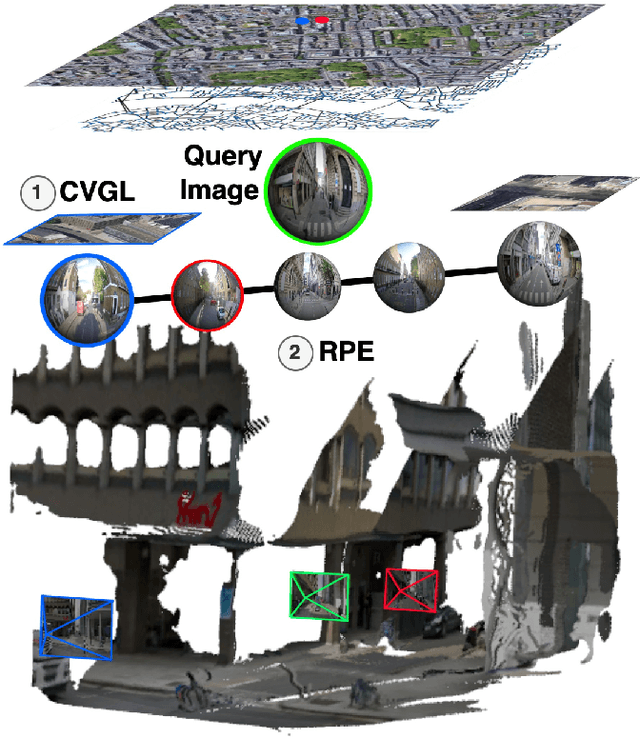


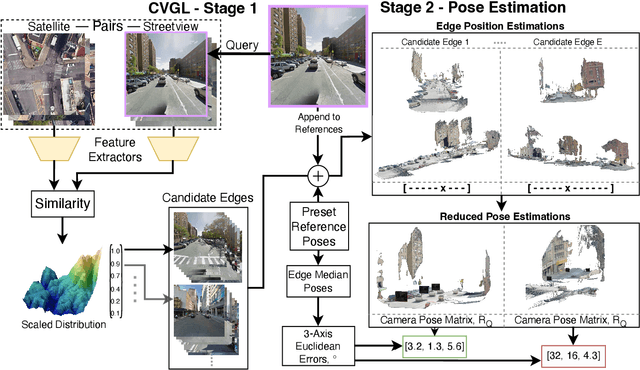
Cross-view Geo-localisation is typically performed at a coarse granularity, because densely sampled satellite image patches overlap heavily. This heavy overlap would make disambiguating patches very challenging. However, by opting for sparsely sampled patches, prior work has placed an artificial upper bound on the localisation accuracy that is possible. Even a perfect oracle system cannot achieve accuracy greater than the average separation of the tiles. To solve this limitation, we propose combining cross-view geo-localisation and relative pose estimation to increase precision to a level practical for real-world application. We develop PEnG, a 2-stage system which first predicts the most likely edges from a city-scale graph representation upon which a query image lies. It then performs relative pose estimation within these edges to determine a precise position. PEnG presents the first technique to utilise both viewpoints available within cross-view geo-localisation datasets to enhance precision to a sub-metre level, with some examples achieving centimetre level accuracy. Our proposed ensemble achieves state-of-the-art precision - with relative Top-5m retrieval improvements on previous works of 213%. Decreasing the median euclidean distance error by 96.90% from the previous best of 734m down to 22.77m, when evaluating with 90 degree horizontal FOV images. Code will be made available: tavisshore.co.uk/PEnG
Two Hands Are Better Than One: Resolving Hand to Hand Intersections via Occupancy Networks
Apr 08, 2024



3D hand pose estimation from images has seen considerable interest from the literature, with new methods improving overall 3D accuracy. One current challenge is to address hand-to-hand interaction where self-occlusions and finger articulation pose a significant problem to estimation. Little work has applied physical constraints that minimize the hand intersections that occur as a result of noisy estimation. This work addresses the intersection of hands by exploiting an occupancy network that represents the hand's volume as a continuous manifold. This allows us to model the probability distribution of points being inside a hand. We designed an intersection loss function to minimize the likelihood of hand-to-point intersections. Moreover, we propose a new hand mesh parameterization that is superior to the commonly used MANO model in many respects including lower mesh complexity, underlying 3D skeleton extraction, watertightness, etc. On the benchmark InterHand2.6M dataset, the models trained using our intersection loss achieve better results than the state-of-the-art by significantly decreasing the number of hand intersections while lowering the mean per-joint positional error. Additionally, we demonstrate superior performance for 3D hand uplift on Re:InterHand and SMILE datasets and show reduced hand-to-hand intersections for complex domains such as sign-language pose estimation.