 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTACO: Trajectory Aligning Cross-view Optimisation
May 05, 2026Cross-View Geo-localisation (CVGL) matches ground imagery against satellite tiles to give absolute position fixes, an alternative to GNSS where signals are occluded, jammed, or spoofed. Recent fine-grained CVGL methods regress sub-tile metric pose, but have only been evaluated as one-shot localisers, never as the primary fix in a live pipeline. Inertial sensing provides high-rate relative motion, but accumulates unbounded drift without an absolute anchor. We propose TACO, a tightly-coupled IMU + fine-grained CVGL pipeline that consumes a single GNSS reading at start-up and thereafter operates on onboard sensing alone. A closed-form cross-track error model triggers CVGL before IMU drift exceeds the matcher's capture radius, and a forward-biased five-point multi-crop search keeps inference cost fixed at five forward passes per fix. A yaw-residual gate rejects fixes that disagree with the onboard compass, and an anisotropic body-frame noise model scales each Unscented Kalman Filter update by per-fix confidence. A factor graph with vetted loop closures provides an offline smoothed trajectory. On the KITTI raw dataset, TACO reduces median Absolute Trajectory Error (ATE) from 97.0m (IMU-only) to 16.3m, a 5.9 times reduction, at <0.1 ms per-frame fusion cost and a 5-10% camera duty cycle. Code is available: github.com/tavisshore/TACO.
PEnG: Pose-Enhanced Geo-Localisation
Nov 24, 2024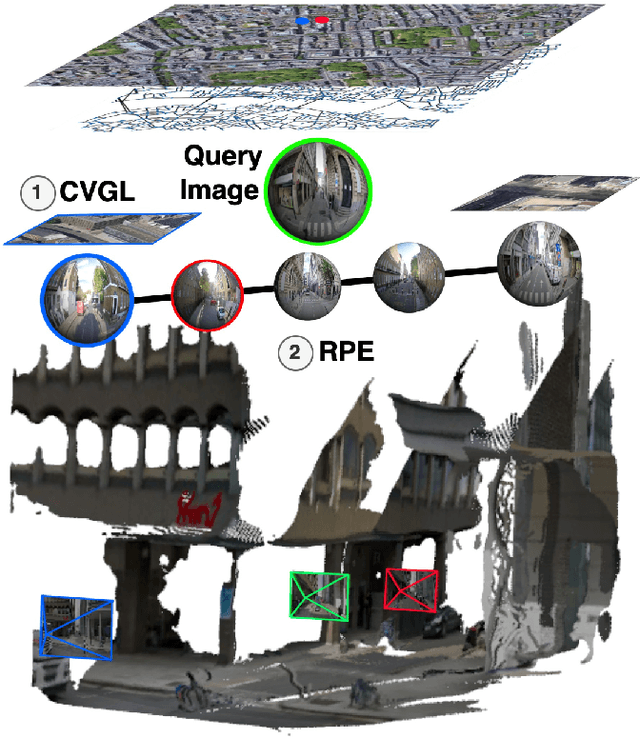


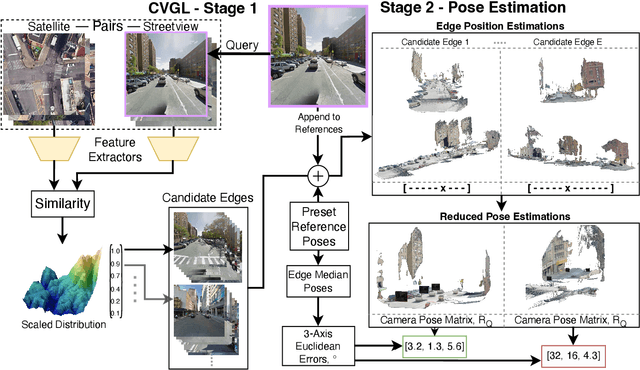
Cross-view Geo-localisation is typically performed at a coarse granularity, because densely sampled satellite image patches overlap heavily. This heavy overlap would make disambiguating patches very challenging. However, by opting for sparsely sampled patches, prior work has placed an artificial upper bound on the localisation accuracy that is possible. Even a perfect oracle system cannot achieve accuracy greater than the average separation of the tiles. To solve this limitation, we propose combining cross-view geo-localisation and relative pose estimation to increase precision to a level practical for real-world application. We develop PEnG, a 2-stage system which first predicts the most likely edges from a city-scale graph representation upon which a query image lies. It then performs relative pose estimation within these edges to determine a precise position. PEnG presents the first technique to utilise both viewpoints available within cross-view geo-localisation datasets to enhance precision to a sub-metre level, with some examples achieving centimetre level accuracy. Our proposed ensemble achieves state-of-the-art precision - with relative Top-5m retrieval improvements on previous works of 213%. Decreasing the median euclidean distance error by 96.90% from the previous best of 734m down to 22.77m, when evaluating with 90 degree horizontal FOV images. Code will be made available: tavisshore.co.uk/PEnG
BEV-CV: Birds-Eye-View Transform for Cross-View Geo-Localisation
Dec 23, 2023Cross-view image matching for geo-localisation is a challenging problem due to the significant visual difference between aerial and ground-level viewpoints. The method provides localisation capabilities from geo-referenced images, eliminating the need for external devices or costly equipment. This enhances the capacity of agents to autonomously determine their position, navigate, and operate effectively in environments where GPS signals are unavailable. Current research employs a variety of techniques to reduce the domain gap such as applying polar transforms to aerial images or synthesising between perspectives. However, these approaches generally rely on having a 360{\deg} field of view, limiting real-world feasibility. We propose BEV-CV, an approach which introduces two key novelties. Firstly we bring ground-level images into a semantic Birds-Eye-View before matching embeddings, allowing for direct comparison with aerial segmentation representations. Secondly, we introduce the use of a Normalised Temperature-scaled Cross Entropy Loss to the sub-field, achieving faster convergence than with the standard triplet loss. BEV-CV achieves state-of-the-art recall accuracies, improving feature extraction Top-1 rates by more than 300%, and Top-1% rates by approximately 150% for 70{\deg} crops, and for orientation-aware application we achieve a 35% Top-1 accuracy increase with 70{\deg} crops.